Cela arrive souvent lorsqu'il y a beaucoup de conversions, que leur prix est acceptable et que les ventes n'augmentent pas et même diminuent. Ici, les analyses "avant profit par clic" ne suffisent plus pour en découvrir la raison. Et puis l'analyse «avant le profit du manager» vient à la rescousse. Parce que quelle que soit l'idéal de la mise en place de la publicité, les clients interagissent d'abord avec les gestionnaires, puis prennent une décision. Le succès de votre entreprise dépend de la qualité du travail des employés.
Les systèmes d'analyse traditionnels utilisent le CRM pour enregistrer le fait d'une vente / contact avec un manager. Cependant, cette approche ne résout que partiellement le problème: elle évalue l'efficacité de l'employé «dans le résultat net». Autrement dit, il montre les ventes et la conversion, mais laisse la communication même avec le client «à la mer». Mais le résultat dépend du niveau de communication.
Pour combler cette lacune, nous avons développé un outil qui reliera automatiquement chaque appel au responsable qui l'a traité. Vous n'êtes pas obligé d'utiliser CRM et des services tiers. En fait, notre système met une balise «nom du responsable» sur chaque appel entrant.
Ainsi, les responsables du service commercial / service client contrôleront la qualité du travail, trouveront les zones problématiques et créeront des analyses. Une segmentation rapide des appels vers les managers qui les reçoivent y contribuera.
Formulation du problème
La tâche que nous nous sommes fixée est la suivante: faire connaître au système les modes de parole de tous les managers qui peuvent recevoir des appels. Ensuite, pour un nouvel appel, vous devez marquer le responsable, dont la voix est la plus "similaire" dans la conversation dans la liste des appels connus.
Dans ce cas, on considère a priori que le nouvel appel téléphonique est réussi. Autrement dit, la conversation entre le gestionnaire et le client a effectivement eu lieu. De manière informelle, cette tâche peut être attribuée à la classe de tâches «enseigner avec un enseignant», c'est-à-dire la classification.
En tant qu'objets - en quelque sorte des enregistrements audio vectorisés (numérisés), où seule la voix du manager retentit. Les réponses sont des étiquettes de classe (noms de gestionnaires). Ensuite, la tâche de l'algorithme de marquage est:
- Extraction de fonctionnalités significatives à partir de fichiers audio
- Choisir l'algorithme de classification le plus adapté
- Apprentissage de l'algorithme et sauvegarde des modèles de gestionnaire
- Évaluer la qualité de l'algorithme et modifier ses paramètres
- Marquer (classer) les nouveaux appels
Certaines de ces tâches relèvent de sous-tâches distinctes. Cela est dû aux spécificités des conditions dans lesquelles l'algorithme doit fonctionner. Les appels téléphoniques sont généralement bruyants. Un client dans une conversation peut communiquer avec plusieurs gestionnaires. De plus, cela n'aura pas lieu du tout et les appels incluent souvent l'IVR, etc.
Par exemple, la tâche de baliser les nouveaux appels peut être divisée en:
- Vérifier l'appel pour le succès (le fait qu'il y ait un appel)
- Diviser la stéréo en pistes mono
- Filtrage du bruit
- Identification des zones avec parole (filtrage de la musique et autres sons parasites)
À l'avenir, nous parlerons de chacune de ces sous-tâches séparément. En attendant, nous formulerons les contraintes techniques que nous imposons aux données d'entrée, à la solution résultante, ainsi qu'à l'algorithme de classification lui-même.
Contraintes de la solution
Le besoin de restrictions est en partie dicté par la technique et les exigences de la complexité de la mise en œuvre, ainsi que par l'équilibre entre l'universalité de l'algorithme et la précision de son fonctionnement.
Limitations du fichier d'entrée et des fichiers d'exemple de formation:
- Format - wav ou wave (vous pouvez encore recoder en mp3)
- La chaîne stéréo doit ensuite être divisée en 2 pistes - l'opérateur et le client
- Taux d'échantillonnage - 16 000 Hz et plus
- Profondeur de bits - à partir de 16 bits et plus
- Le fichier d'entraînement du modèle doit durer au moins 30 secondes et ne contenir que la voix d'un manager spécifique
- , , ,
Toutes les exigences ci-dessus, à l'exception de la dernière, ont été formulées à la suite d'une série d'expériences qui ont été menées au stade de la mise en place des algorithmes. Cette combinaison s'est avérée la plus efficace en termes de minimisation de la probabilité d'erreur, à savoir une mauvaise classification dans des conditions de réglage facile.
Par exemple, il est évident que plus le fichier de l'ensemble d'apprentissage est long, plus le classificateur sera précis. Mais plus il est difficile de trouver un tel fichier dans le journal des appels (notre exemple d'apprentissage). Par conséquent, la durée de 30 secondes est un compromis entre précision et complexité des réglages. La dernière condition (succès) est nécessaire. Le système ne doit pas marquer un responsable pour un appel où il n'y a pas eu de conversation.
Les limites de l'algorithme ont conduit à la solution suivante:
- , . « ». . - , .
- . , , .
La première exigence est venue de l'expérimentation. Puis il s'est avéré que le gestionnaire "inconnu" complique l'architecture de la solution. Pour cela, il est nécessaire de sélectionner des seuils après lesquels le salarié sera classé comme «non reconnu». De plus, le gestionnaire «inconnu» réduit la précision de 10 points de pourcentage.
De plus, une erreur du second type apparaît lorsqu'un gestionnaire connu est classé comme inconnu. La probabilité d'une telle erreur est de 7 à 10%, en fonction du nombre d'erreurs connues. Cette exigence peut être qualifiée d'essentielle. Cela oblige le tuner d'algorithme à indiquer tous les gestionnaires de l'échantillon d'apprentissage. Et aussi ajouter des modèles de nouveaux employés là-bas et supprimer ceux qui quittent.
La deuxième exigence provient de considérations pratiques et de l'architecture de l'algorithme que nous utilisons. En bref, l'algorithme décompose l'audio analysé en fragments de parole et «compare» chacun d'eux avec tous les modèles de gestionnaire formés un par un.
En conséquence, une "mini-étiquette" est attribuée à chacun des mini-fragments. Avec cette approche, il y a une forte probabilité que certains des fragments ne soient pas reconnus correctement. Par exemple, s'ils restent bruyants ou si leur longueur est trop courte.
Ensuite, si tous les "mini-tags" sont affichés dans la solution finale, alors en plus du tag du vrai manager, beaucoup de "trash" seront affichés. Par conséquent, seule la balise la plus "fréquente" est affichée.
Description des données d'entrée / sortie
Nous allons diviser les données d'entrée en 2 types:
Données en entrée de l'algorithme de génération de modèles de managers (données pour la formation):
- Fichier audio + étiquette de classe
Données en entrée de l'algorithme de marquage (données pour test / fonctionnement normal):
- Données externes (fichier audio)
- Données internes (modèles enregistrés)
La sortie est également divisée en 2 types:
- Données de sortie de l'algorithme de génération de modèle
- Modèles de gestionnaires formés
- Sortie de l'algorithme de balisage
- Balise de gestionnaire
A l'entrée de l'algorithme, dans n'importe quel mode de son fonctionnement, un fichier audio répondant aux exigences est reçu. Ils sont dans la section «restrictions».
A l'entrée de l'algorithme de génération de modèle, il est permis que plusieurs fichiers d'entrée correspondent à une classe (gestionnaire). Mais un fichier ne peut pas correspondre à plusieurs gestionnaires. Le nom de l'étiquette de classe peut être placé dans le nom du fichier. Ou créez simplement un répertoire distinct pour chaque employé.
L'algorithme d'entraînement de modèle basé sur les entrées génère de nombreux modèles qui peuvent être chargés pendant l'entraînement. Leur nombre correspond au nombre de balises différentes dans l'ensemble des fichiers audio.
Ainsi, s'il y a des fichiers M marqués avec n différentes étiquettes de classe, puis l'algorithme au stade de la formation crée n modèles de gestionnaires:
- Model_manager_1.pkl
- Model_manager_2.pkl
- ...
- Model_manager_n.pkl
où au lieu de " manager _... " est le nom de la classe.
L'entrée de l'algorithme de balisage est un fichier audio non étiqueté, dans lequel il y a a priori une conversation entre un manager et un client, ainsi que n modèles d'employés. En conséquence, l'algorithme renvoie une balise - le nom de la classe du gestionnaire le plus "plausible".
Prétraitement des données
Les fichiers audio sont prétraités. Il est séquentiel et s'exécute à la fois en mode balisage et en mode d'apprentissage du modèle:
- Vérification du succès de l'appel - uniquement au stade de l'étiquetage
- Diviser la stéréo en 2 pistes mono et travailler uniquement avec la piste de l'opérateur
- Numérisation - extraction des paramètres du signal audio
- Filtrage du bruit
- Suppression des "longues" pauses - identification des fragments avec du son
- Filtrer les fragments non vocaux - supprimer la musique, l'arrière-plan, etc.
- Fusion de fragments avec de la parole (uniquement au stade de la formation)
Nous ne nous attarderons pas sur l’étape de la vérification du succès. C'est un sujet pour un article séparé. En bref, l'essence de la scène est que l'appel est classé selon qu'il y a ou non une conversation de «personnes vivantes». Par «personnes vivantes», nous entendons un client et un responsable, pas un assistant vocal, de la musique, etc.
Le succès d'un appel est vérifié à l'aide d'un classificateur spécialement formé avec un seuil externe - «la durée minimale d'une conversation après laquelle l'appel est considéré comme réussi».
Au deuxième stade, le fichier stéréo est divisé en 2 pistes: le gestionnaire et le client. Le traitement ultérieur est effectué uniquement pour la piste de l'employé.
Au stade de la numérisation, les paramètres de la «caractéristique» sont extraits de la piste opérateur, qui sont une représentation numérique du signal. Chez Calltouch, nous avons utilisé des composants craie-cepstrale. De plus, les paramètres sont extraits sur un très petit fragment, appelé largeur de fenêtre (0,025 seconde). Toutes les fonctionnalités sont normalisées en même temps.
nfft=2048 //
appendEnergy = False
def get_MFCC(sr,audio): // , sr=16000 -
features = mfcc.mfcc(audio, sr, 0.025, 0.01, 13, 26, nfft, 0, 1000, appendEnergy)
features = preprocessing.scale(features)
return features
count = 1
features = np.asarray(()) //
for path in file_paths: //
path = path.strip()
sr,audio = read(source + path) //
vector = get_MFCC (sr, audio) #
if features.size == 0:
features = vector
else:
features = np.vstack((features, vector))En sortie, chaque fichier audio se transforme en un tableau, dans lequel les caractéristiques mel-cepstrales de chaque fragment de 0,025 seconde sont enregistrées ligne par ligne.
Le traitement ultérieur du fichier consiste à filtrer le bruit, à supprimer les longues pauses (pas les pauses entre les sons) et à rechercher la parole. Ces tâches peuvent être accomplies à l'aide de divers outils. Dans notre solution, nous avons utilisé des méthodes de la bibliothèque pyaudioanalysis:
clear_noise(fname,outname,ch_n) # .- fname - fichier d'entrée
- outname - fichier de sortie
- ch_n - nombre de canaux
En sortie, nous obtenons le fichier outname, qui contient le son, débarrassé du bruit, du fname.
silenceRemoval(x, Fs, stWin, stStep) # « »- x - matrice d'entrée (signal numérisé)
- Fs - taux d'échantillonnage
- stWin - largeur de la fenêtre d'extraction d'entités
- stStep - taille de pas de décalage
En sortie, on obtient un tableau de la forme:
[l_1, r_1]
[l_2, r_2]
[l_3, r_3]
…
[l_N, r_N]
où l_i est l'heure de début du i-ème segment (sec), r_i est l'heure de fin du i-ème segment (sec ).
detect_audio_segment(x,thrs) # .- x - matrice d'entrée (signal numérisé)
- hrs - longueur minimale (en secondes) du fragment de parole détecté
À la sortie, nous obtenons ces fragments [l_i, r_i] , qui contiennent un discours d'une durée de trois secondes.
À la suite du prétraitement, le fichier audio d'entrée est converti sous la forme d'un tableau:
[l_1, r_1]
[l_2, r_2]
[l_3, r_3]
…
[l_N, r_N],
où chaque fragment est un intervalle de temps du fichier vocal effacé.
Ainsi, nous pouvons faire correspondre chacun de ces fragments avec une matrice de caractéristiques (petites caractéristiques cepstrales), qui sera utilisée pour la formation du modèle et au stade du marquage.
Méthodes / algorithmes utilisés
Comme indiqué ci-dessus, notre solution est basée sur la bibliothèque pyaudioanalysis.py écrite en Python 2.7. Du fait que notre solution générale est implémentée en Python 3.7, certaines des fonctions de la bibliothèque ont été modifiées et adaptées pour cette version du langage.
En général, l'algorithme de l'outil de balisage des gestionnaires peut être divisé en 2 parties:
- Formation des gestionnaires de modèles
- Balisage
Une description plus détaillée de chaque pièce ressemble à ceci.
Formation des gestionnaires de modèles:
- Chargement de l'échantillon de formation
- Prétraitement des données
- Compter le nombre de classes
- Créer un modèle de gestionnaire pour chacune des classes
- Sauvegarder le modèle
Marquage:
- Chargement des appels
- Vérifier l'appel au succès
- Prétraitement d'un appel réussi
- Chargement de tous les modèles de gestionnaire formés
- Classification de chaque fragment de l'appel traité
- Trouver le modèle de gestionnaire le plus probable
- Balisage
Nous avons déjà discuté en détail des tâches de prétraitement des données. Examinons maintenant les méthodes de création de modèles de gestionnaire.
Nous avons utilisé l'algorithme GMM (Gaussian Mixture Model) comme modèle . Il modélise nos données en supposant qu'il s'agit de réalisations d'une variable aléatoire avec une distribution qui est décrite par un mélange de gaussiens - chacun avec sa propre variance et sa propre espérance mathématique.
On sait que l'algorithme le plus courant pour trouver les paramètres optimaux d'un tel mélange est l'algorithme EM (Expectation Maximization) . Il divise le difficile problème de la maximisation de la vraisemblance d'une variable aléatoire multidimensionnelle en une série de problèmes de maximisation de dimension inférieure.
À la suite d'une série d'expériences, nous sommes arrivés aux paramètres suivants de l'algorithme GMM:
gmm = GMM(n_components = 16, n_iter = 200, covariance_type='diag',n_init = 3)Un tel modèle est créé pour chaque gestionnaire, puis il est formé - ses paramètres sont adaptés à des données spécifiques.
gmm.fit(features)Ensuite, le modèle est enregistré pour être utilisé au stade du balisage:
picklefile = path[path.find('/')+1:path.find('.')]+".gmm"
pickle.dump(gmm,open(dest + picklefile,'wb'))Au stade du balisage, nous chargeons les modèles précédemment enregistrés:
gmm_files = [os.path.join(modelpath,fname) for fname in
os.listdir(modelpath) if fname.endswith('.gmm')]modelpath est le répertoire dans lequel nous avons enregistré les modèles.
models = [pickle.load(open(fname,'rb'),encoding='latin1') for fname in gmm_files]Et chargez également les noms des modèles (ce sont nos balises):
speakers = [fname.split("/")[-1].split(".gmm")[0] for fname
in gmm_files]Le fichier audio téléchargé, pour lequel vous devez baliser, est vectorisé et prétraité. En outre, chaque fragment contenant le discours est comparé aux modèles entraînés et le gagnant est déterminé en fonction du logarithme maximum de la probabilité:
log_likelihood = np.zeros(len(models)) #
for i in range(len(models)):
gmm = models[i] #
scores = np.array(gmm.score(vector))
log_likelihood[i] = scores.sum() # i –
winner = np.argmax(log_likelihood) #
print("\tdetected as - ", speakers[winner])En conséquence, notre algorithme a approximativement la conclusion suivante:
commence dans: 1.92 se termine par: 8.72
[-10400.93604115 -12111.38278205]
détecté comme - Olga
commence dans: 9.22 se termine dans: 15.72
[-10193.80504138 -11911.11095894]
détecté comme - Olga
commence dans: 26.7 se termine dans: 29,82
[-4867,97641331 -5506,44233563]
détecté en tant que - Ivan
commence dans: 33.34 extrémités: 47,14
[-21143,02629011 -24796,44582627]
détecté comme - Ivan
commence dans: 52.56 extrémités: 59,24
[-10916,83282132 -12.124,26855 starts538]
détecté comme - Olga
starts538 dans: 116,32 se termine par: 134,56
[-36764,94876054 -34810,38959083]
détecté comme - Olga
commence dans: 151,18 se termine dans: 154,86
[-8041.33666572 -6859.14253903]
détecté comme - Olga
commence dans: 159.7 se termine dans: 162.92
[-6421.72235531 -5983.90538059]
détecté comme - Olga
commence dans: 185.02 se termine dans: 208.7
…
commence dans: 442.04 se termine dans:
445.5 [-7451.0289772 -6286.6619 ]
détecté comme - Olga
*******
WINNER - Olga
Cet exemple suppose qu'il y a au moins 2 classes - [Olga, Ivan] . Le fichier audio est découpé en segments [1.92, 8.72], [9.22, 15.72],…, [442.04, 445.5] et le modèle le plus approprié est déterminé pour chacun des segments.
Le logarithme de vraisemblance cumulée est indiqué entre parenthèses à côté de chaque bloc:[-10400.93604115 -12111.38278205] , le premier élément est la probabilité d' Olga , et le second est Ivan . Comme le premier argument est supérieur au second, ce segment est classé comme Olga . Le vainqueur final est déterminé par la majorité des «votes» des fragments.
résultats
Au départ, nous avons conçu l'algorithme en supposant qu'un gestionnaire «inconnu» peut être présent dans les appels entrants - c'est-à-dire que son modèle n'est pas présent dans l'échantillon d'apprentissage.
Pour détecter un tel utilisateur, nous devons entrer une métrique sur le vecteur log_likelihood . De telle sorte que certaines de ses valeurs indiqueront que, très probablement, ce fragment n'est pas correctement décrit par aucun des modèles existants. Nous avons suggéré la métrique suivante comme test:
Leukl=(log_likelihood-np.min(log_likelihood))/(np.max(log_likelihood)-np.min(log_likelihood))
-sorted(-np.array(Leukl))[1]<TCette valeur indique à quel point les scores sont distribués «uniformément» dans le vecteur log_likelihood . L'uniformité des estimations (leur proximité les unes avec les autres) signifie que tous les modèles se comportent de la même manière et qu'il n'y a pas de leader clair.
Cela suggère que tous les modèles sont probablement faux et que nous avons un gestionnaire qui n'était pas au stade de la formation. La relation entre T et la qualité de la classification est illustrée dans les figures.
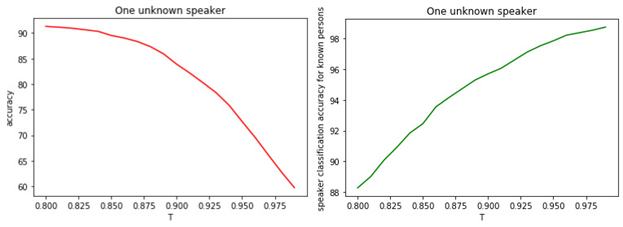
Figure: 1.
a) Exactitude de la classification binaire des gestionnaires connus et inconnus.
b) La précision de la classification des managers célèbres.

Figure: 2.
a) La proportion de gestionnaires connus affectés à la catégorie des gestionnaires connus.
b) La proportion de gestionnaires inconnus affectés à la classe des connus.
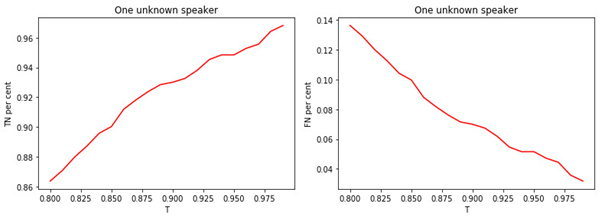
Figure: 3.
a) La part des gestionnaires inconnus affectés à la classe des inconnus.
b) La proportion de gestionnaires connus affectés à la classe d'inconnues.
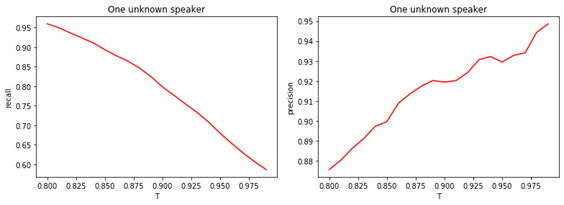
Figure: 4.
a) Exhaustivité de la classification binaire (rappel).
b) Précision de la classification binaire (précision).
La relation entre la valeur du seuil T et la qualité de la classification (marquage) est évidente. Plus T est grand (plus les conditions d'attribution d'un gestionnaire à la classe des inconnues sont strictes), moins il est probable qu'un gestionnaire bien connu soit classé comme inconnu. Mais il est plus probable de «rater» un gestionnaire inconnu.
La valeur de seuil optimale est de 0,8 . Parce que nous classons les managers connus avec une précision d'environ 90%et déterminer les «inconnues» avec une précision de 81% . Si nous supposons que tous les gestionnaires nous sont «familiers», alors la précision sera d'environ 98% .
conclusions
Dans l'article, nous avons décrit les idées générales du fonctionnement de notre outil d'identification des managers dans les appels. Bien sûr, nous ne prétendons pas que notre algorithme est optimal et incapable de s'améliorer.
Il repose sur un certain nombre d'hypothèses qui ne sont pas toujours satisfaites dans la pratique. Par exemple, nous pouvons faire face à un manager inconnu s'il n'y a pas de données le concernant. Ou deux ou plusieurs gestionnaires peuvent mener une conversation avec le client «à parts égales». Du point de vue de l'algorithme, les directions suivantes pour d'autres améliorations peuvent être proposées:
- Choisir un modèle d'algorithme différent de GMM
- Optimiser les paramètres GMM
- Sélection d'une métrique différente pour détecter un nouveau manager
- Rechercher les caractéristiques les plus significatives du signal vocal
- Combinaison de différents outils de prétraitement audio et optimisation des paramètres de ces méthodes