Aujourd'hui, nous avons une conversation physique et technique avec Mikhail Burtsev , le chef du laboratoire des réseaux de neurones au MIPT. Ses intérêts de recherche comprennent les modèles d'apprentissage des réseaux neuronaux, les systèmes neurocognitifs et neurohybrides, l'évolution des systèmes adaptatifs et des algorithmes évolutifs, les neurocontrôleurs et la robotique. Tout cela sera discuté.

- Comment l'histoire du Laboratoire des Réseaux de Neurones et du Deep Learning de Phystech a-t-elle commencé?
- En 2015, j'ai participé à une initiative de l'Agence pour les Initiatives Stratégiques (ASI) appelée «Foresight Fleet» - c'est une plate-forme de discussion de plusieurs jours dans le cadre de l'Initiative technique nationale. Le sujet clé était les technologies qui doivent être développées pour que les entreprises apparaissent en Russie avec le potentiel de prendre des positions de leader sur les marchés mondiaux. Le message principal était qu'il est extrêmement difficile de pénétrer les marchés formés, mais les technologies ouvrent de nouveaux territoires et de nouveaux marchés, et c'est précisément sur eux que nous devons pénétrer.
Nous avons donc navigué sur un bateau à moteur le long de la Volga et discuté des technologies qui pourraient aider à créer de tels marchés et à briser les barrières technologiques actuelles. Et dans cette discussion sur l'avenir, le sujet des assistants personnels s'est développé. Il est clair que nous avons déjà commencé à les utiliser - Alexa, Alice, Siri ... et il était évident qu'il y avait des barrières techniques dans la compréhension entre les humains et les ordinateurs. D'autre part, de nombreux développements de la recherche se sont accumulés, par exemple dans le domaine de l'apprentissage par renforcement, dans le traitement du langage naturel. Et c'est devenu clair: de nombreuses tâches difficiles sont de mieux en mieux résolues à l'aide de réseaux de neurones.
Et je faisais juste des recherches sur les algorithmes de réseau neuronal. Sur la base des résultats des discussions de Foresight Fleet, nous avons formulé le concept d'un projet de développement technologique pour un avenir proche, qui a ensuite été transformé en projet iPavlov. Ce fut le début de mon interaction avec Phystech.
Plus en détail, nous avons formulé trois tâches. Infrastructure - création d'une bibliothèque ouverte pour mener des dialogues avec l'utilisateur. Le second est la recherche sur le traitement du langage naturel. Plus la solution de problèmes commerciaux spécifiques .
Sberbank a agi en tant que partenaire et le projet lui-même a été formé sous l'aile de l'Initiative technique nationale.
, 2015 -: deephack.me — , , - , . Open Data Science.
Début 2018, nous avons publié le premier référentiel de notre bibliothèque ouverte DeepPavlov, et au cours des deux dernières années, nous avons constaté une croissance régulière de ses utilisateurs (il se concentre sur le russe et l'anglais): nous avons environ 50% des installations des États-Unis, 20-30% de la Russie. Dans l'ensemble, il s'est avéré être un projet open source plutôt réussi.
Nous développons non seulement mais essayons également de contribuer au programme de recherche mondial sur l'IA conversationnelle. Conscients de la nécessité d'une compétition académique dans ce domaine, nous avons lancé la série Conversational AI Challenges dans le cadre de NeuIPS, la principale conférence sur l'apprentissage automatique.
De plus, nous organisons non seulement des compétitions, mais nous participons également. Ainsi, l'équipe de notre laboratoire a participé l'année dernière à un concours d'Amazon appelé le prix Alexa - créant un chat bot avec lequel une personne serait intéressée à parler pendant 20 minutes.
Le prochain concours débutera en novembre.
Il s'agit d'un concours universitaire, et le noyau des participants devait être composé d'étudiants et de personnel universitaire. Il y avait 350 équipes au total, sept sont sélectionnées pour le top et trois sont invitées sur la base des résultats de l'année dernière - nous sommes arrivés au sommet.
Notre système de dialogue a mené environ 100 000 dialogues avec des utilisateurs aux États-Unis et a finalement obtenu une note d'environ 3,35-3,4 sur 5, ce qui est plutôt bien. Cela suggère que nous avons réussi à former une équipe de classe mondiale au MIPT en un temps assez court.
Maintenant, le laboratoire mène des projets avec différentes entreprises, parmi les plus importantes, Huawei et Sberbank. Projets dans différentes directions: AutoML, théorie des réseaux de neurones et, bien sûr, notre direction principale - la PNL.
- À propos des tâches qui étaient auparavant difficiles pour le machine learning: pourquoi le deep learning a-t-il décollé pour résoudre ces problèmes?
- Dur à dire. Je vais maintenant décrire mon intuition de manière légèrement simplifiée. Le fait est que si le modèle a beaucoup de paramètres, il peut étonnamment bien généraliser les résultats à de nouvelles données. En ce sens que le nombre de paramètres peut être proportionnel au nombre d'exemples. Pour la même raison, le ML classique a longtemps résisté à la pression des réseaux de neurones - il semble que rien de bon ne devrait en sortir dans cette situation.
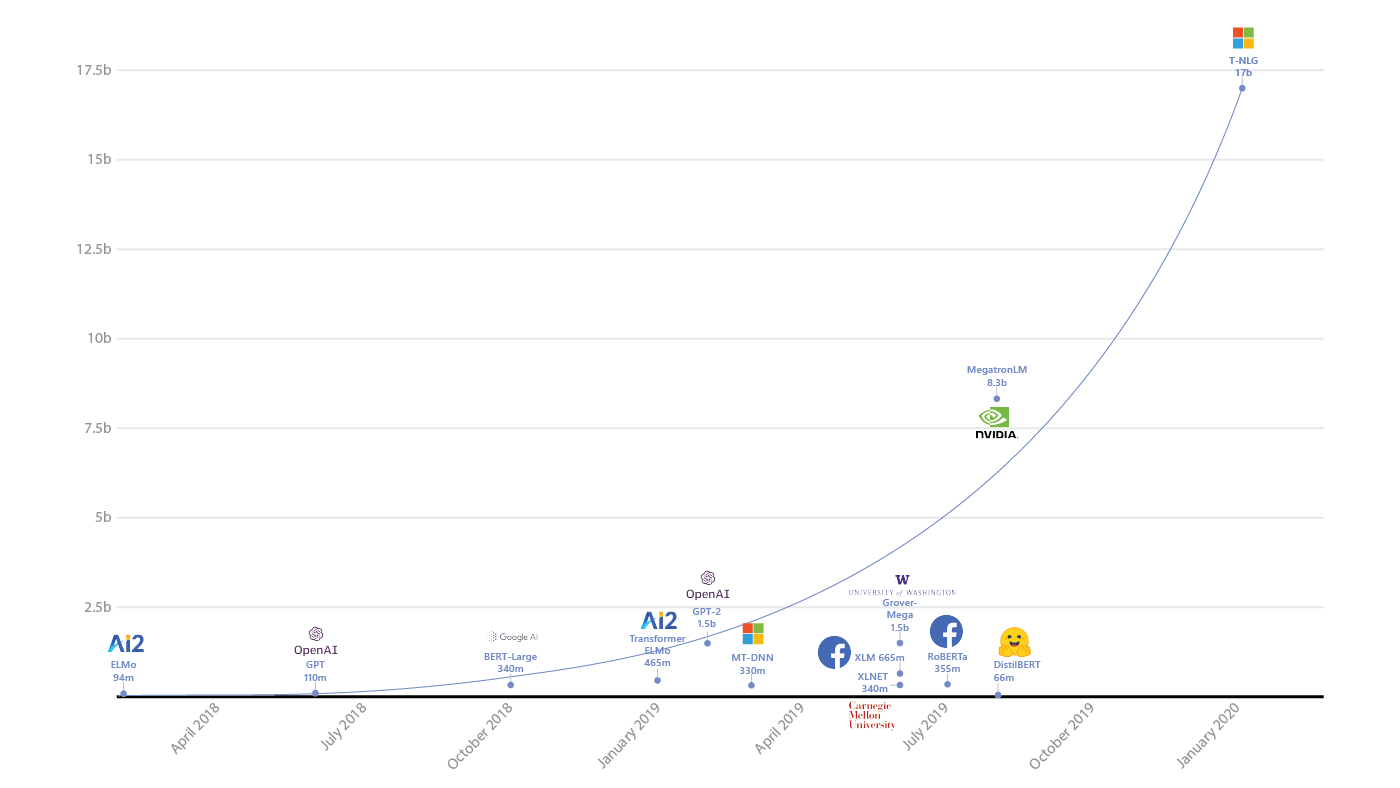
La montée en puissance des paramètres dans les modèles d'apprentissage profond ( source )
Étonnamment, ce n'est pas le cas. Ivan Skorokhodov de notre laboratoire a montré ( .pdf ) que presque tous les modèles bidimensionnels peuvent être trouvés dans l'espace de la fonction de perte du réseau neuronal.
Vous pouvez sélectionner un plan tel que chaque point de ce plan correspondra à un ensemble de paramètres de réseau neuronal. Et leur perte correspondra à un schéma arbitraire, et, en conséquence, vous pourrez capter de tels réseaux de neurones qu'ils tomberont directement sur cette image.
Un résultat très drôle. Cela suggère que même avec de telles restrictions absurdes, le réseau neuronal peut apprendre la tâche qui lui est assignée. C'est à peu près le genre d'intuition ici, oui.

Exemples de motifs tirés de l'article d'Ivan Skorokhodov
- Ces dernières années, des progrès significatifs ont été notables dans le domaine du deep learning, mais l'horizon est-il déjà visible où l'on va s'enfoncer dans la limite des indicateurs?

La croissance de la taille des modèles d'IA et des ressources qu'ils consomment (source: openai.com/blog/ai-and-compute/ )
- En PNL, la limite ne se fait pas encore sentir, même s'il semble que, par exemple, dans l'apprentissage par renforcement, quelque chose a déjà commencé caleçon. Autrement dit, il n'y a eu aucun changement qualitatif au cours des deux dernières années. Il y a eu un grand boom d'Atari à AlphaGo avec l'hybridation avec Monte Carlo Tree Search, mais il n'y a plus de percée immédiate.
Mais en PNL, c'est l'inverse: les réseaux récurrents, les réseaux convolutifs, et enfin l'architecture du transformateur et GPT lui-même (l' un des modèles de transformateurs les plus récents et les plus intéressants, souvent utilisé pour générer des textes - note de l'auteur) Est déjà un développement purement extensif. Et ici, il semble qu'il y ait encore une marge pour réaliser quelque chose de nouveau. Par conséquent, en PNL, la barre n'est pas visible d'en haut. Bien que, bien sûr, il soit presque impossible de prédire quoi que ce soit ici.
- Si nous imaginons le développement de langages et de frameworks pour l'apprentissage automatique, alors nous sommes passés de l'écriture (conditionnelle) en pur numpy, scikit-learn à tensorflow, keras - les niveaux d'abstraction ont augmenté. Quelle est la prochaine étape pour nous?
— , : - . , , low level high level code: numpy . , , NLP : .
- Tensorflow / Pytorch — : .
- : NLP- — DeepPavlov.
- : — DeepPavlov Dream .
- Un système de commutation entre les compétences / pipelines, y compris notre agent DeepPavlov.
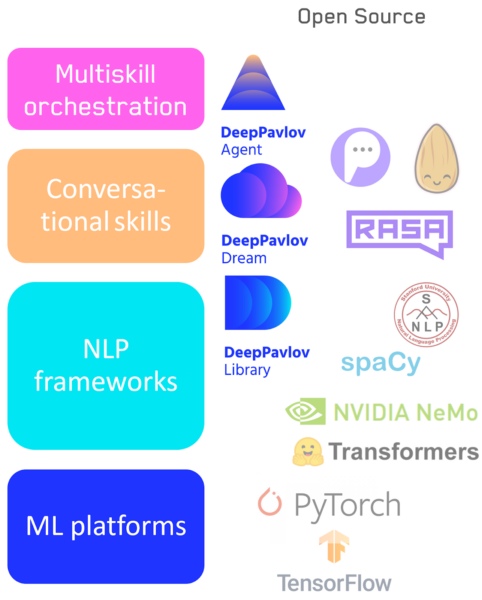
Pile de technologies d'IA conversationnelle
Différentes applications et tâches nécessitent une flexibilité d'outils différente, et par conséquent, je ne pense pas que les éléments de cette hiérarchie disparaîtront. Les systèmes de bas niveau et de haut niveau évolueront au fur et à mesure des besoins. Par exemple, les bibliothèques visuelles qui ne sont pas disponibles pour les programmeurs, mais aussi les bibliothèques de bas niveau pour les développeurs n'iront nulle part.
- Les expériences sociales sont-elles désormais menées par analogie avec le test de Turing classique, où les gens doivent comprendre si un réseau de neurones est en face d'eux ou d'une personne?
- De telles expériences sont menées régulièrement. Dans l'Alexa Challenge, une personne devait évaluer la qualité d'une conversation sans savoir si elle parlait à un robot ou à une personne. Jusqu'à présent, du point de vue d'une conversation en direct, la différence entre une machine et une personne est importante, mais elle diminue chaque année. Au fait, notre article à ce sujet vient de paraître dans AI Magazine.
En dehors de la communauté scientifique, cela se fait régulièrement. Récemment, quelqu'un a formé un modèle GPT, a créé un compte Twitter pour elle et a commencé à publier des réponses. De nombreuses personnes se sont inscrites, le compte a gagné en popularité et personne ne savait qu'il s'agissait d'un réseau neuronal.
Un format aussi court, comme sur Twitter, lorsque les formulations sont générales et «profondes», convient parfaitement au système d'inférence de réseau neuronal.
- Quels domaines considérez-vous comme les plus prometteurs, où s'attendre à un saut?
- ( Rires ) Je pourrais dire que c'est dans l'unification de toutes mes directions préférées que le saut se fera. J'essaierai de décrire plus en détail dans le cadre de la problématisation. Nous avons les modèles GPT basés sur des transformateurs de courant - ils n'ont aucun but dans la vie, ils génèrent juste du texte de type humain, sans aucun but. Et ils ne peuvent pas le lier à la situation et aux objectifs dans le contexte du monde lui-même.
Et l'un des moyens est de créer une liaison d'une vue logique du monde à GPT, qui a lu beaucoup, beaucoup de texte, et en fait, il y a déjà de nombreuses connexions logiques. Par exemple, par hybridation avec "Wikidata" (il s'agit d'un graphe décrivant les connaissances sur le monde, aux sommets desquels se trouvent des articles de Wikipédia).
Si nous pouvions connecter les deux afin que GPT puisse utiliser la base de connaissances, ce serait un bond en avant.
La seconde approche du problème de l'absence de but des modèles PNL est basée sur l'intégration de la compréhension des objectifs humains en eux. Si nous avons un modèle qui peut conduire un modèle de langage génératif lié à un graphe de connaissances, nous pourrions le former pour aider une personne à atteindre ses objectifs. Et un tel assistant doit comprendre la personne à travers la PNL, les objectifs de la personne et la situation - alors il doit planifier des actions. Et dans la planification, l'apprentissage par renforcement fonctionne le mieux.
Comment combiner et optimiser tout cela est une question ouverte.
Et le dernier est la recherche d'architectures de réseaux neuronaux. Lorsque, par exemple, en utilisant des approches évolutives, nous cherchons dans l'espace des architectures optimales pour une tâche donnée. Mais tout cela ne sera pas décidé aujourd'hui - il y a trop d'espace pour chercher.
De la bonne nouvelle: le matériel évolue très rapidement et, peut-être, cela nous permettra dans 5 à 10 ans de combiner des modèles de langage de réseau neuronal, des graphes de connaissances et l'apprentissage par renforcement. Et puis nous ferons un bond en avant dans la compréhension de l'homme par la machine.
Avec l'aide d'un tel assistant, il sera possible de lancer la solution d'autres tâches: analyse d'image, analyse des dossiers médicaux ou de la situation économique, sélection des biens.
Par conséquent, je dirais que d'un point de vue scientifique, dans les cinq prochaines années, nous verrons un développement rapide dans le domaine de l'hybridation - il y a beaucoup de tâches intéressantes.
Les gars, la pénurie de personnel sera énorme et il y a de grandes chances d'obtenir des résultats nouveaux et intéressants, et aussi d'influencer le développement de l'industrie. Connectez-vous - vous devez saisir le moment!( L'auteur soutient activement cette réponse, car il ne traite que de tels systèmes. )
- Comment commencer à plonger dans le deep learning?
- Le moyen le plus simple, me semble-t-il, est de suivre un cours en école de deep learning : au départ il était destiné aux lycéens, mais il conviendra tout à fait aux étudiants. En général, c'est une grande entreprise, j'ai aidé à planifier et à donner des conférences d'introduction là-bas.
Je recommande également de regarder les cours d'introduction des universités, de faire des tâches - il y a juste beaucoup de choses sur Internet. Le meilleur de tous les outils pour "jouer" est Colab de Google, il existe des millions d'exemples de tâches, vous pouvez le comprendre et exécuter les solutions les plus modernes - sans installer aucun logiciel sur votre ordinateur.
Une autre façon est de rivaliser sur Kaggle. Et rejoignez également Open Data Science - une communauté russophone pour la science des données, où il existe plusieurs canaux d'apprentissage en profondeur. Il y a toujours des gens là-bas qui sont prêts à vous aider avec des conseils et du code.
Ce sont les principaux moyens.
Leader-ID : amis, pour la sélection maintenant lancée pour l' accélérateur de promotion de projets IA, nous avons pensé une option de connexion pour les développeurs indépendants. Non, cela ne change pas les conditions de base dans lesquelles seules les équipes participent à l'intensif. Mais nous avons beaucoup de questions de la part d'individus qui n'ont pas leur propre projet maintenant, mais qui veulent participer (et ce ne sont pas seulement des programmeurs, les concepteurs ont un grand intérêt pour les projets d'IA). Et nous avons trouvé une solution: nous aiderons à rassembler une équipe et des personnes partageant les mêmes idées grâce à un hackathon en ligne gratuit . Il commencera le 10 octobre à 12h00 et se terminera exactement un jour plus tard. Sur celui-ci, le bot vous répartira en équipes, puis, sous sa direction, vous passerez par les principales étapes de développement du projet et le soumettrez à l'Archipel 20.35. Tous les détails sont dans votre compte personnel, il vous suffit de vous inscrire à temps.