Modèles basés sur transformateur ont obtenu des résultats remarquables dans une grande variété de disciplines, y compris AI conversation , langage naturel traitement , l' image de traitement , et même la musique . Le composant principal de toute architecture est le module d'attention Transformers ( module d' attention), qui calcule la similitude pour toutes les paires de la séquence d'entrée. Cependant, il ne s'adapte pas bien à l'augmentation de la longueur de la séquence d'entrée, ce qui nécessite une augmentation quadratique du temps de calcul pour obtenir toutes les estimations de similarité, ainsi qu'une augmentation quadratique de la quantité de mémoire utilisée pour construire une matrice pour stocker ces estimations.
Pour les applications nécessitant une attention accrue, plusieurs proxys plus rapides et plus compacts ont été proposés, tels que les techniques de mise en cache de la mémoire , mais la solution la plus courante consiste à utiliser une attention limitée . Une attention clairsemée réduit le temps de calcul et les besoins en mémoire du mécanisme d'attention en ne calculant qu'un nombre limité de scores de similitude à partir d'une séquence, plutôt que toutes les paires possibles, ce qui donne une matrice clairsemée plutôt que complète. Ces occurrences rares peuvent être suggérées manuellement, trouvées à l'aide de techniques d'optimisation, apprises ou même aléatoires, comme le démontrent des techniques telles que les transformateurs clairsemés , les formateurs longs., Transformateurs de routage , Reformers et Big Bird . Étant donné que les matrices clairsemées peuvent également être représentées par des graphiques et des arêtes , les méthodes clairsemées sont également motivées par la littérature sur les réseaux de neurones graphiques , en particulier en ce qui concerne le mécanisme d'attention décrit dans Graph Attention Networks. De telles architectures de parcimonie nécessitent généralement des couches supplémentaires pour créer implicitement un mécanisme d'attention complet.
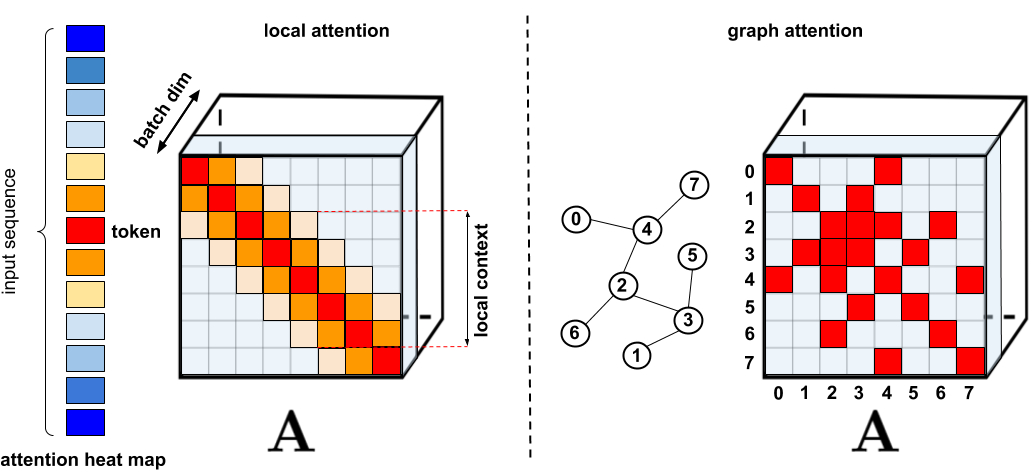
. : , . : Graph Attention Networks, , , . . « : » .
, . (1) , ; (2) ; (3) , , ; (4) , , . , , , Pointer Networks. , , , (softmax), .
, Performer, , . , , , ImageNet64, , PG-19. Performer () , , () . (Fast Attention Via Positive Orthogonal Random Features, FAVOR+), . ( , -). , .
, , , . , - . , , .
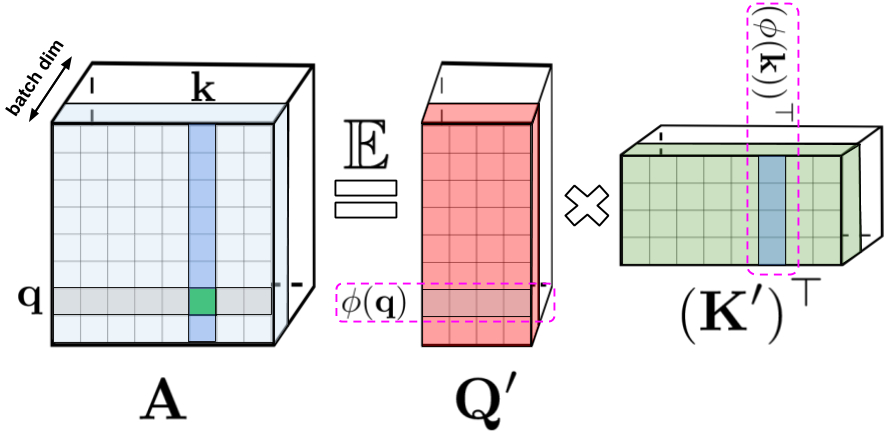
: , , , q k. : Q' K' , /. - , .
, , . , , , , -.
FAVOR+:
, . , . , , . , FAVOR+.
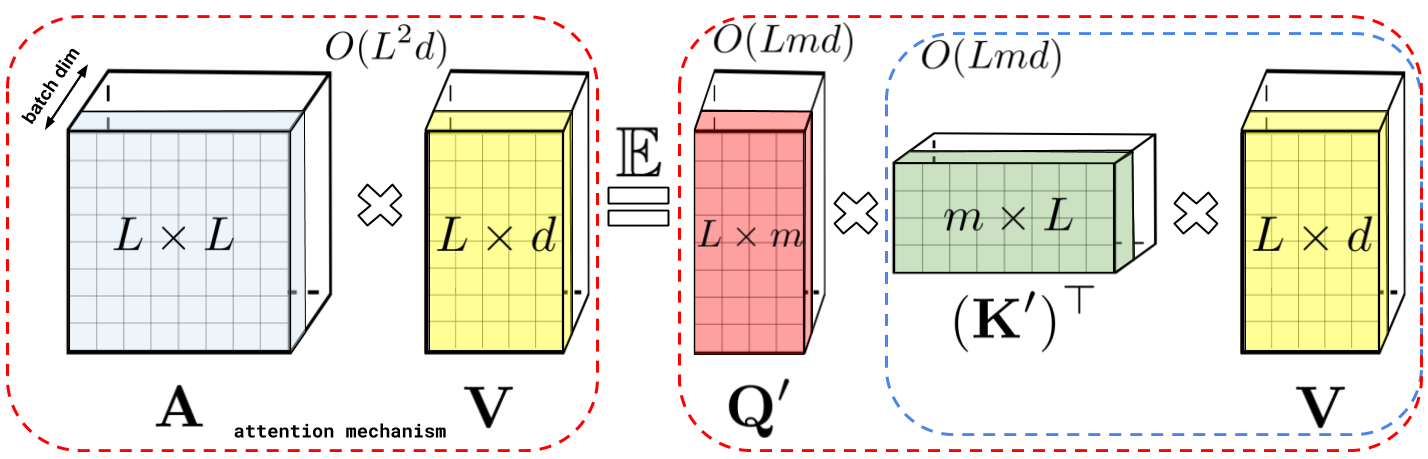
: , A V. : Q' K', A , , , , A .
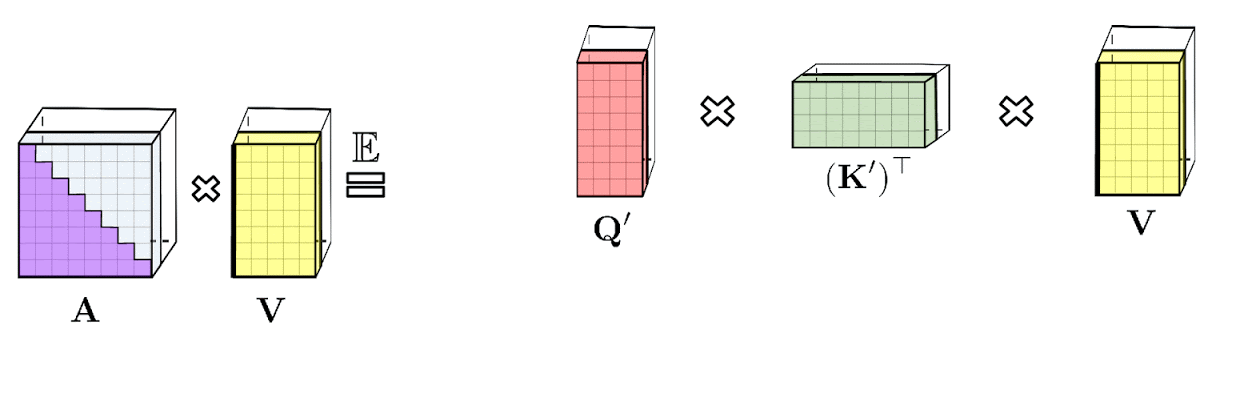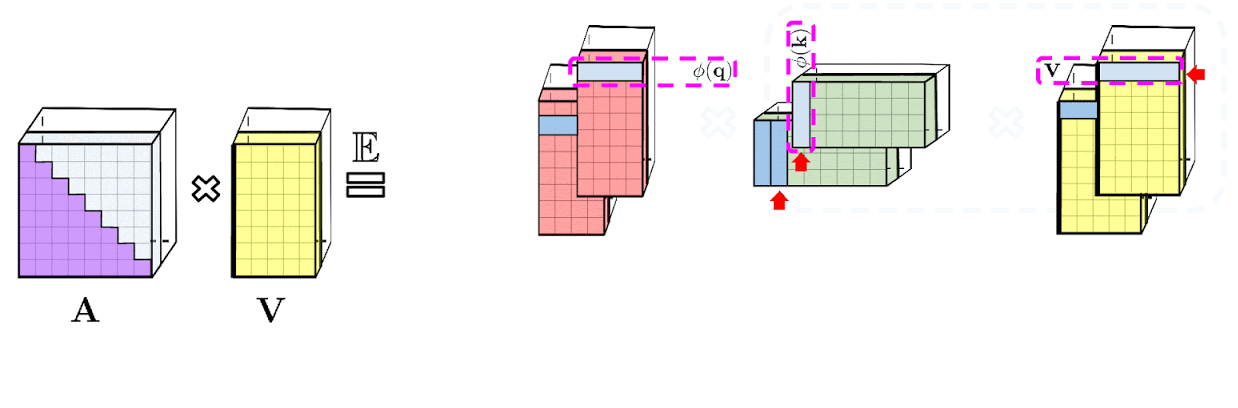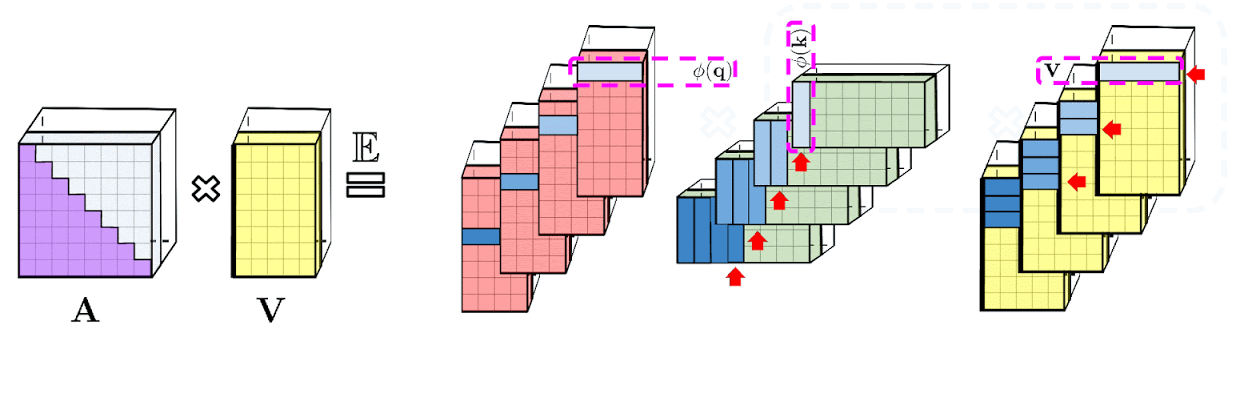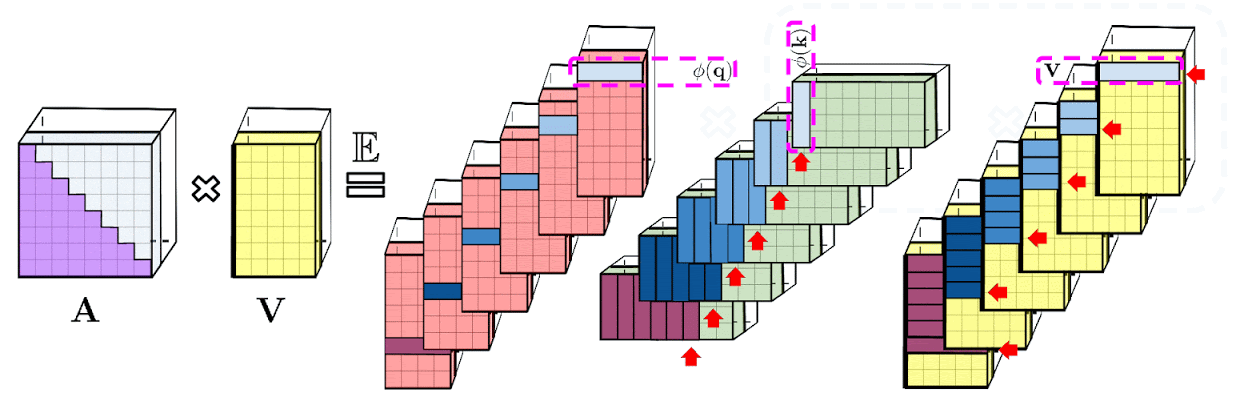
: , . : , .
Performer , , , .
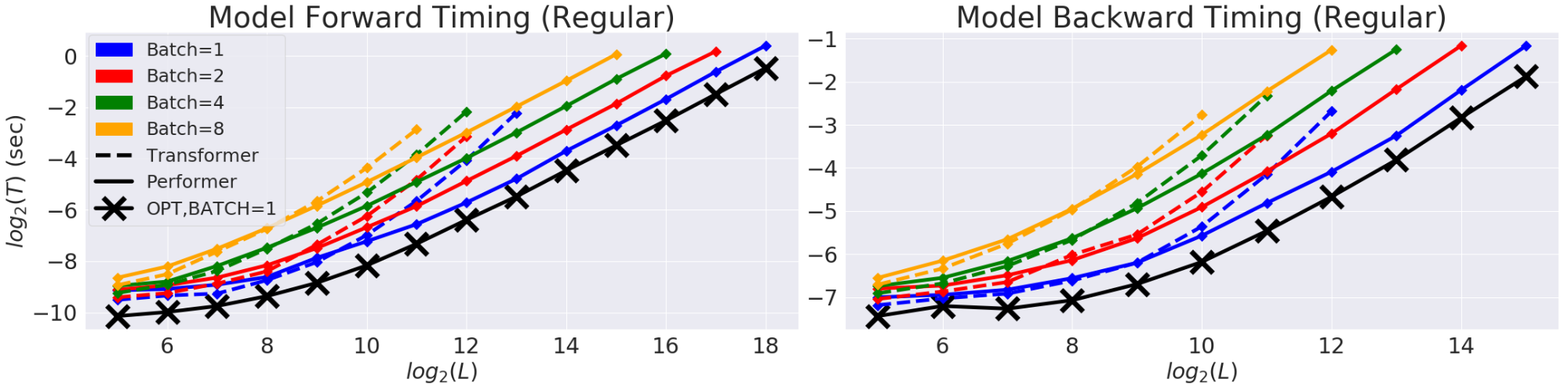
(T) (L). GPU. (X) «» , , , . Performer .
, Performer, -, , .
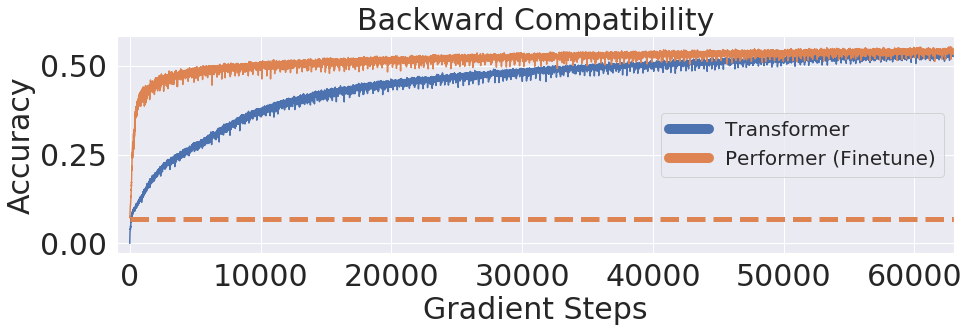
One Billion Word Benchmark (LM1B), Performer, 0.07 ( ). Performer .
:
— , . , , 20 . (, UniRef) , . Performer-ReLU ( ReLU, , ) , Performer-Softmax (accuracy) , .
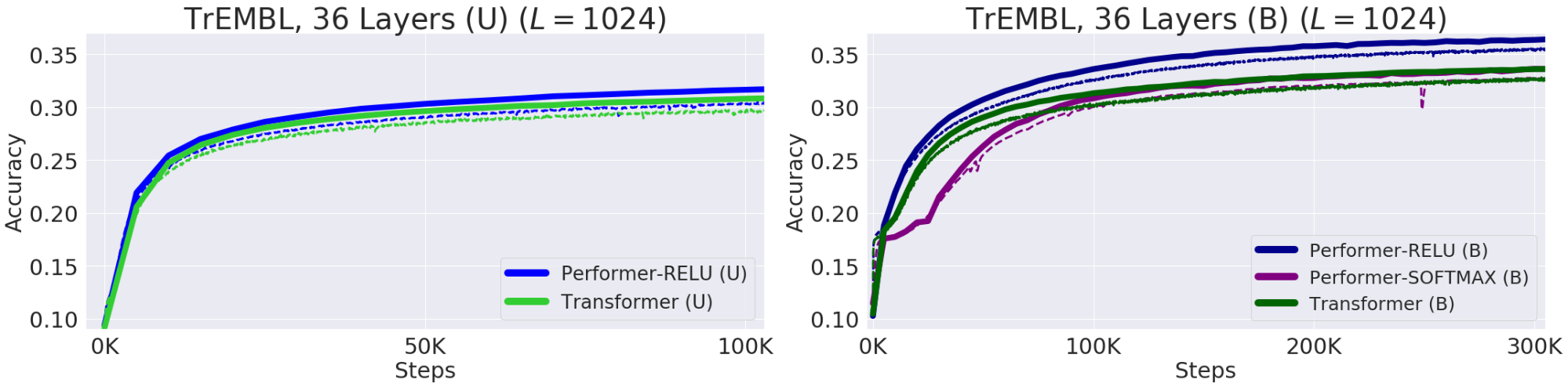
. (Train) — , (Validation) – , — (U), — (B). 36 ProGen (2019) , 16x16 TPU-v2. .
Protein Performer, ReLU. Performer , , . , , . Performer' . , , Performer - .
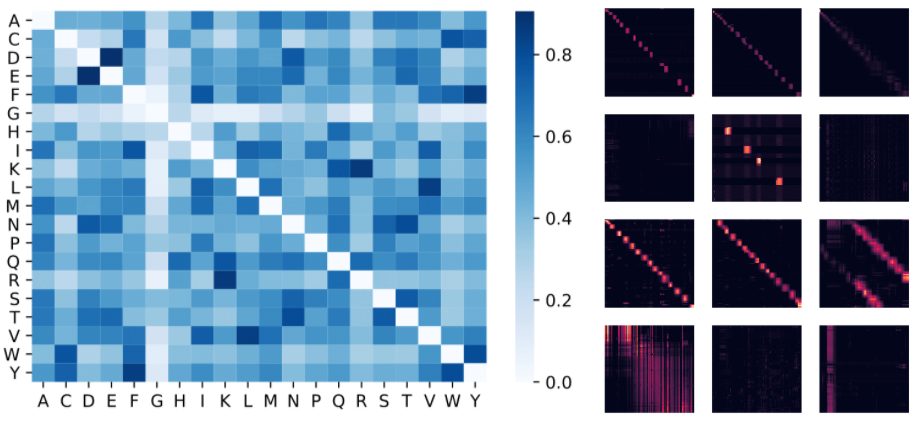
: , . , (D, E) (F, Y), . : 4 () 3 «» () BPT1_BOVIN, .
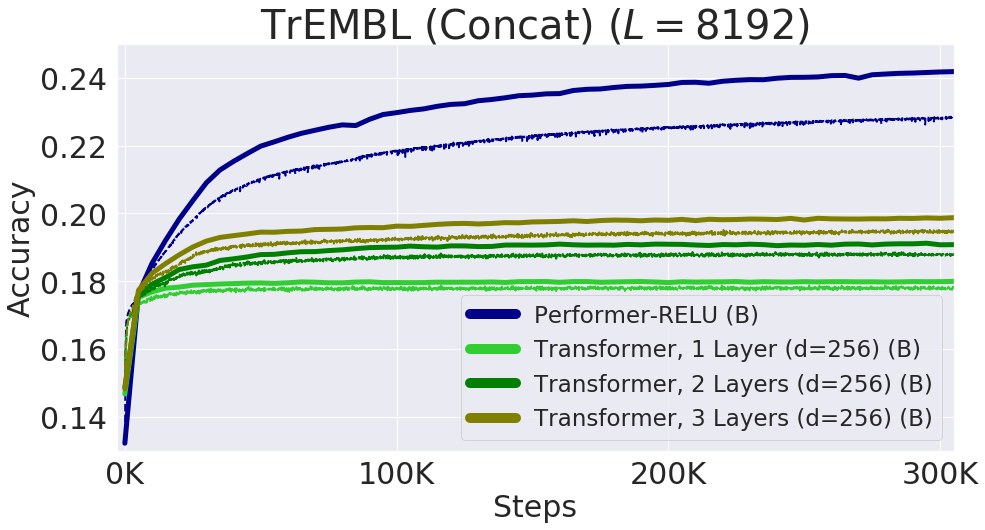
8192, . TPU, ( ) .
, . , , FAVOR Reformer. , Performer' . , , .
- — Krzysztof Choromanski, Lucy Colwell
- —
- Montage et mise en page - Sergey Shkarin