
URALCHEM fabrique des engrais. N ° 1 en Russie - pour la production de nitrate d'ammonium, par exemple, figure parmi les 3 premiers producteurs nationaux d'ammoniac, d'urée et d'engrais azotés. Des acides sulfuriques, des engrais à deux composants, des phosphates et bien d'autres sont produits. Tout cela crée des environnements agressifs dans lesquels les capteurs échouent.
Nous avons construit Data Lake et en même temps recherché les capteurs qui gèlent, échouent, commencent à donner de fausses données et se comportent généralement différemment de ce que les sources d'information devraient se comporter. Et le "truc" est qu'il est impossible de construire des modèles mathématiques et des jumeaux numériques sur la base de "mauvaises" données: ils ne résoudront tout simplement pas le problème correctement et donneront un effet commercial.
Mais les usines modernes ont besoin de Data Lake pour les data scientists. Dans 95% des cas, les données "brutes" ne sont en aucun cas collectées, mais seuls les agrégats du système de contrôle de processus sont pris en compte, qui sont stockés pendant deux mois et les points de "changement de dynamique" de l'indicateur sont stockés, qui sont calculés par un algorithme spécialement défini, ce qui pour les data scientists réduit la qualité des données, car ., peut-être, peut manquer les "rafales" de l'indicateur ... En fait, quelque chose comme ça s'est passé à URALCHEM. Il était nécessaire de créer un entrepôt de données de production, de récupérer les sources dans les magasins et dans les systèmes MES / ERP. Tout d'abord, cela est nécessaire pour commencer à collecter l'historique pour la science des données. Deuxièmement, pour que les scientifiques des données disposent d'une plate-forme pour leurs calculs et d'un bac à sable pour tester les hypothèses, et ne pas charger la même où le système de contrôle de processus tourne.Les Data Scientists ont essayé d'analyser les données disponibles, mais cela ne suffisait pas. Les données ont été stockées décimées, avec des pertes, souvent incompatibles avec le capteur. Il n'était pas possible de prendre rapidement un ensemble de données et il n'y avait nulle part où travailler avec lui non plus.
Revenons maintenant à ce qu'il faut faire si le capteur "roule".
Quand tu construis un lac
Il ne suffit pas de construire quelque chose comme ça:
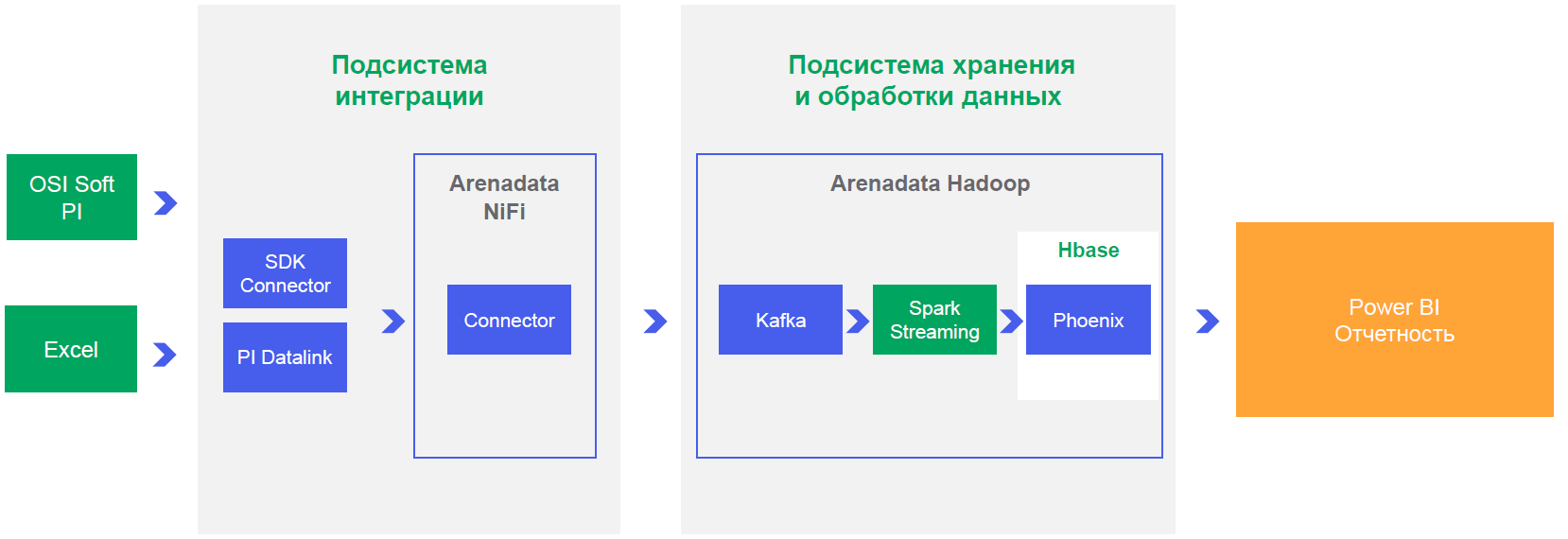
vous devez également prouver à l'entreprise que tout fonctionne et montrer un exemple d'un projet terminé. Il est clair que faire un projet sur une telle moissonneuse-batteuse consiste à construire le communisme dans un seul pays, mais les conditions sont exactement cela. Nous prenons un microscope et prouvons qu'ils peuvent enfoncer un clou.
Globalement, URALCHEM est chargé de la numérisation de la production. Dans le cadre de toute cette action, tout d'abord, créer un bac à sable pour tester les hypothèses, améliorer l'efficacité du processus de production, ainsi que développer des modèles prédictifs de pannes d'équipements, des systèmes d'aide à la décision et ainsi réduire le nombre de temps d'arrêt et améliorer la qualité des processus de production. C'est à ce moment que vous savez à l'avance que quelque chose est sur le point de tomber en panne et que vous pouvez le réparer une semaine avant que la machine ne commence à tout détruire. Avantage - en réduisant les coûts de production et en améliorant la qualité des produits.
C'est ainsi qu'apparaissent les critères de la plateforme et les exigences de base du pilote: stockage d'une grande quantité d'informations, accès en ligne aux données des systèmes de business intelligence, calculs en quasi temps réel afin d'émettre des recommandations ou des notifications dans les plus brefs délais.
Nous avons élaboré des options d'intégration et réalisé que pour les performances et le fonctionnement en mode NRT, vous devez travailler uniquement via votre connecteur, ce qui ajoutera des données à Kafka (un courtier de messages évolutif horizontalement, qui vous permet simplement de "vous abonner à l'événement" de la modification de la lecture du capteur, et basé sur de cet événement à la volée pour effectuer des calculs et générer des notifications). D'ailleurs, Artur Khismatullin, le chef du département de développement des systèmes de production, la branche OTSO d'URALCHEM JSC, nous a beaucoup aidés.
Que faut-il, par exemple, pour créer un modèle prédictif des pannes d'équipement?
Cela nécessite la télémétrie de chaque nœud en temps réel ou par tranches proches de lui. Ce n'est pas une fois par heure un état général, mais des lectures directement spécifiques de tous les capteurs pour chaque seconde.
Personne ne collecte ni ne stocke ces données. De plus, nous avons besoin de données historiques sur au moins six mois, et dans le système de contrôle des processus, comme je l'ai dit, elles sont stockées au maximum pendant les trois derniers mois. Autrement dit, vous devez commencer par le fait que les données seront collectées quelque part, écrites quelque part et stockées quelque part. Données d'environ 10 Go par nœud par an.
De plus, vous devrez travailler avec ces données d'une manière ou d'une autre. Cela nécessite une installation qui vous permet normalement d'effectuer des sélections à partir de la base de données. Et il est souhaitable que sur des join'ah complexes, tout ne se lève pas d'un jour. Surtout plus tard, lorsque la production commence à ajouter plus de problèmes de prédiction du mariage. Eh bien, pour les réparations prédictives, aussi, un rapport du soir selon lequel la machine pourrait tomber en panne lorsqu'elle est tombée en panne il y a une demi-heure - un cas comme ça.
En conséquence, le lac est nécessaire pour les scientifiques des données.
Contrairement à d'autres solutions similaires, nous avions toujours la tâche du temps réel sur Hadoop. Parce que les prochaines grandes tâches sont les données de composition des matériaux, l'analyse de la qualité des substances, la consommation de matériaux de la production.
En fait, lorsque nous avons construit la plate-forme elle-même, la prochaine chose que l'entreprise attendait de nous était de collecter des données sur la défaillance des capteurs et de créer un système qui nous permet d'envoyer des travailleurs pour les changer ou les entretenir. Et en même temps marque le témoignage d'eux comme erroné dans l'histoire.
Capteurs
En production - un environnement agressif, les capteurs fonctionnent de manière difficile et échouent souvent. Idéalement, un système de surveillance prédictive est également nécessaire pour les capteurs, mais d'abord, au moins des évaluations de ceux qui mentent et de ceux qui ne le sont pas.
Il s'est avéré que même un simple modèle de détermination de ce qu'il y a avec le capteur est essentiel pour une autre tâche: établir un équilibre mathématique. Une bonne planification du processus - combien et ce qui doit être mis, comment le chauffer, comment le traiter: si la planification est erronée, la quantité de matière première nécessaire n'est pas claire. Pas assez de produits seront produits - l'entreprise ne fera pas de profit. S'il y a plus que nécessaire - encore une fois une perte, car il est nécessaire de stocker. Le bilan matière correct ne peut être obtenu qu'à partir des informations correctes des capteurs.
Ainsi, dans notre projet pilote, la surveillance de la qualité des données de production a été choisie.
Nous nous sommes entretenus avec les technologues pour les données «brutes», avons examiné les pannes d'équipement confirmées. Les deux premières raisons sont très simples.
Ici, le capteur commence soudainement à afficher des données qui, en principe, ne devraient pas être:
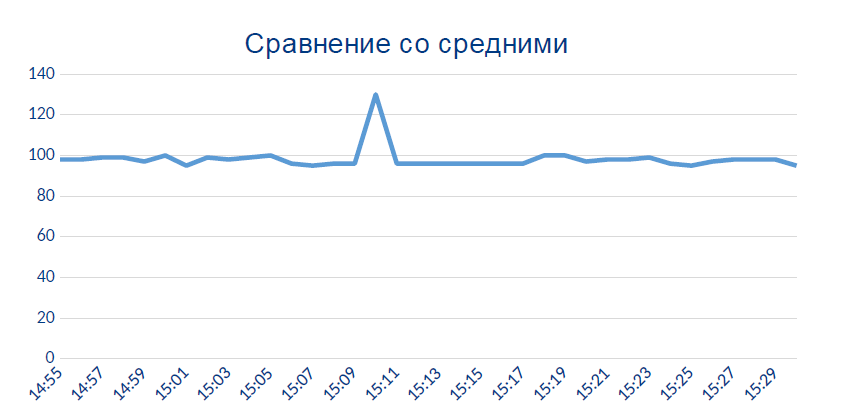
Très probablement, ce pic local est le moment où le capteur est devenu thermiquement ou chimiquement mauvais.
Il y a aussi un dépassement des limites de mesure admissibles (quand il y a une grandeur physique comme la température de l'eau de 0 à 100). A zéro, l'eau ne circule pas dans le système, et à 200 c'est de la vapeur, et nous l'aurions remarqué par l'absence de toit au-dessus de l'atelier.
Le deuxième cas est également presque insignifiant: les
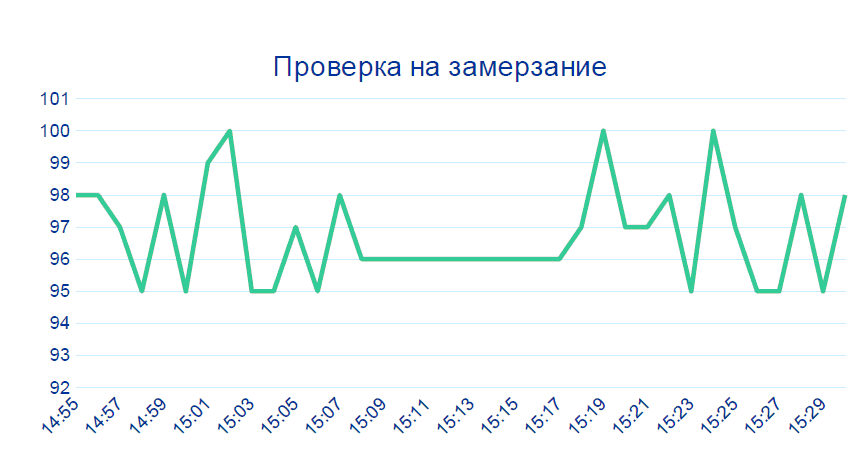
données du capteur ne changent pas pendant plusieurs minutes de suite - cela ne se produit pas dans une production en direct. Très probablement quelque chose avec l'appareil.
80% des problèmes sont résolus en suivant ces modèles sans Big Data, corrélations et historique des données. Mais pour une précision supérieure à 99%, il faut ajouter une autre comparaison avec d'autres capteurs aux nœuds voisins, en particulier, avant et après la section d'où provient la télémétrie douteuse: la
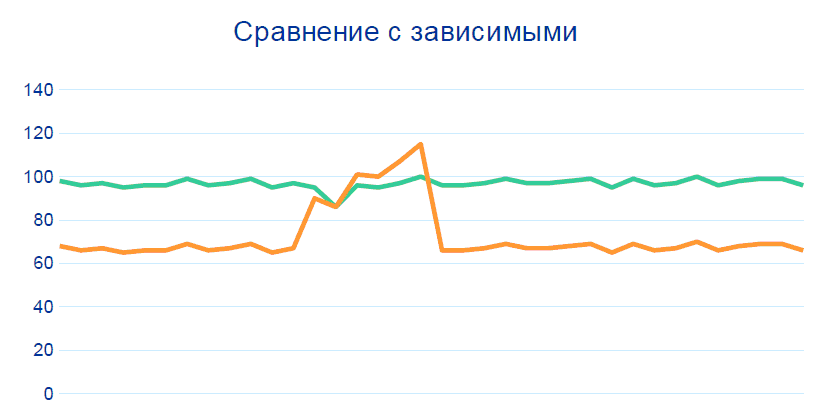
production est un système équilibré: si un indicateur change, l'autre doit également changer. Dans le cadre du projet, des règles ont été formées sur la relation des indicateurs, et ces relations ont été «normalisées» par les technologues. Sur la base de ces directives, un système basé sur Hadoop peut identifier des capteurs potentiellement inopérants.
Les exploitants de l'usine étaient heureux que les capteurs soient correctement détectés, car cela leur permettait d'envoyer rapidement un réparateur ou simplement de nettoyer le capteur souhaité.
En fait, le pilote a fini par lister des capteurs potentiellement inopérants dans l'atelier, qui affichent des informations incorrectes.
Vous pouvez demander comment la réponse aux conditions d'urgence et de pré-urgence a été mise en œuvre avant et comment elle est devenue après le projet. Je répondrai que la réaction à un accident ne ralentit pas, car dans une telle situation, plusieurs capteurs montrent le problème à la fois.
Soit le technologue, soit le chef de service est responsable de l'efficacité de l'installation (et des actions en cas d'accident). Ils comprennent parfaitement ce qui se passe avec leur équipement et comment, et savent ignorer certains capteurs. Les systèmes de contrôle de processus qui accompagnent l'installation sont responsables de la qualité des données. Normalement, lorsque le capteur est endommagé, il n'est pas mis en mode non fonctionnel. Pour le technologue, il reste un travailleur, le technologue doit réagir. Le technologue vérifie l'événement et découvre que rien ne s'est passé. Cela ressemble à ceci: «Nous n’analysons que la dynamique, nous ne regardons pas l’absolu, nous savons qu’ils sont incorrects, nous devons ajuster le capteur». Nous «soulignons» aux spécialistes du système de contrôle de processus automatisé que le capteur est erroné et où il est faux. Maintenant, au lieu d'une ronde formelle planifiée, il répare d'abord des appareils spécifiques de manière ciblée, puis il effectue des rondes, ne faisant pas confiance à la technologie.
Pour clarifier la durée d'une marche planifiée, je dirai simplement qu'il y a de trois à cinq mille capteurs sur chacun des sites. Nous avons fourni un outil d'analyse complet qui fournit des données traitées, sur la base desquelles un spécialiste doit prendre une décision sur la vérification. Sur la base de son expérience, nous «soulignons» exactement ce qui est nécessaire. Vous n'avez plus besoin de vérifier manuellement chaque capteur et la probabilité que quelque chose soit manqué est réduite.
Quel est le résultat
Reçu une confirmation commerciale indiquant que la pile peut être utilisée pour résoudre des problèmes de production. Nous stockons et traitons les données du site. L'entreprise doit maintenant choisir les processus suivants pour que les scientifiques des données puissent opérer. Pendant qu'ils nomment une personne responsable du contrôle de la qualité des données, rédigez des règlements à sa place et mettez-les en œuvre dans leur processus de production.
Voici comment nous avons implémenté ce cas: Les
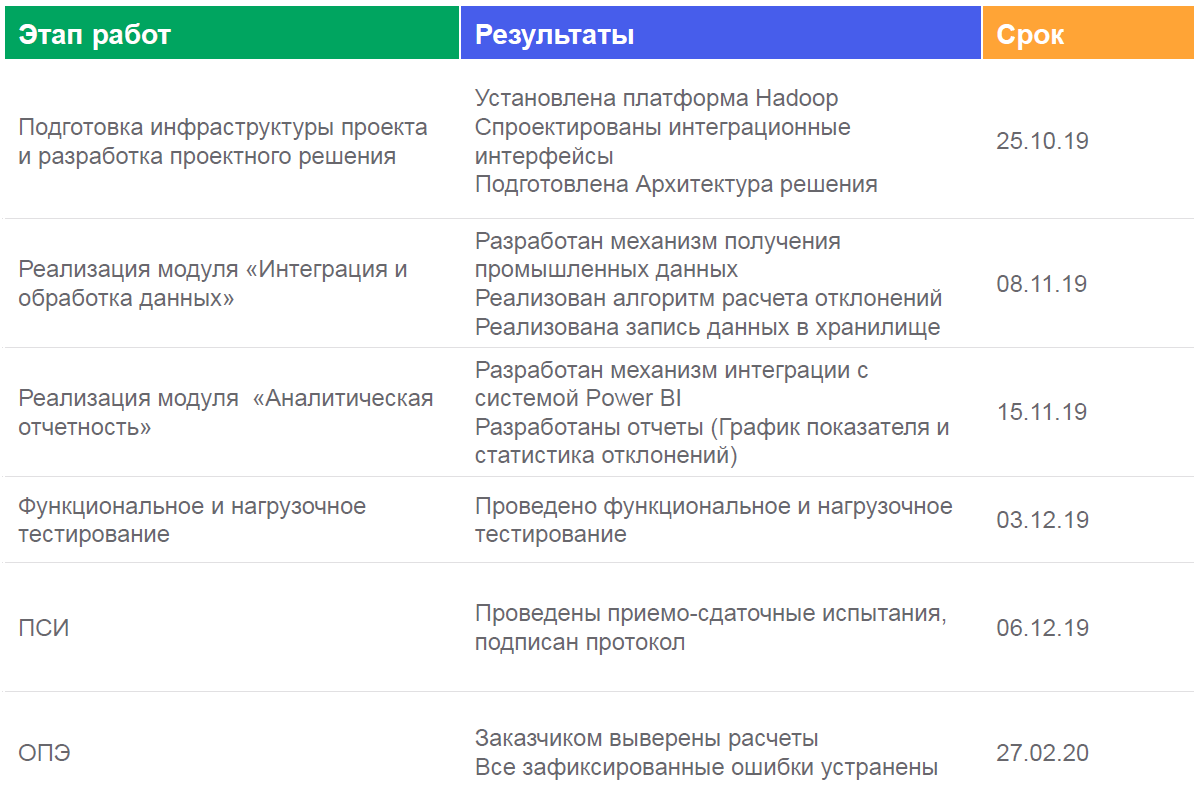
tableaux de bord ressemblent à ceci: Ils sont affichés
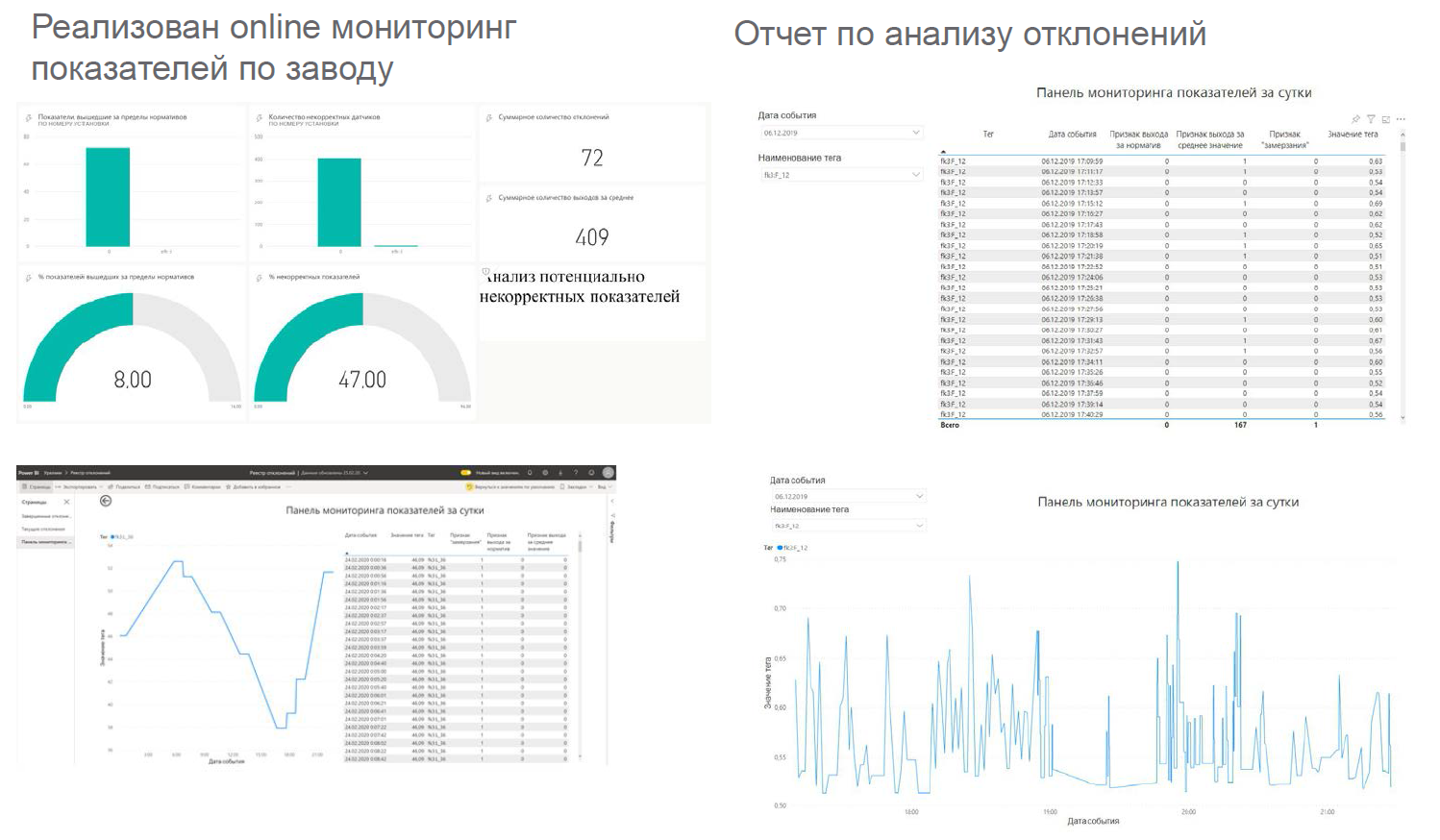
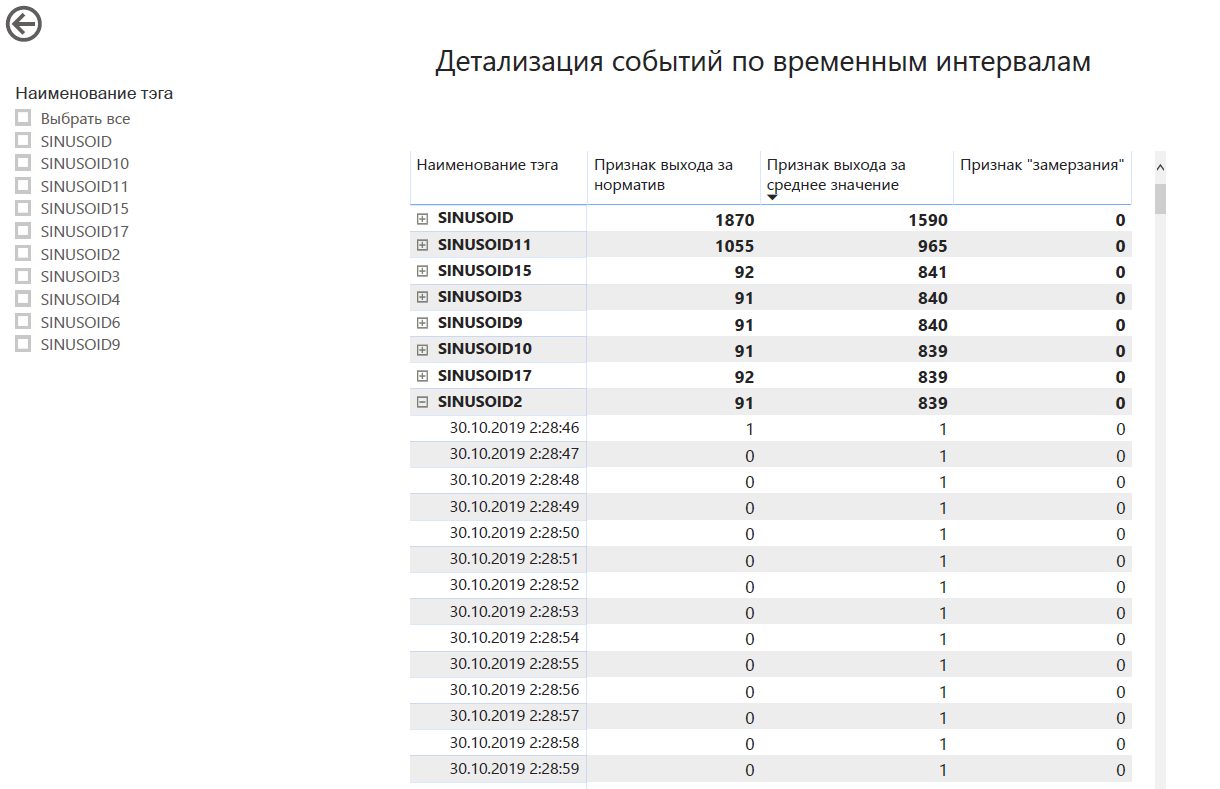
dans de tels endroits:

Ce que nous avons:
- un espace d'information a été créé au niveau technologique pour travailler avec les lectures des capteurs d'équipement;
- vérifié la capacité de stocker et de traiter des données basées sur la technologie Big Data;
- testé la capacité des systèmes de veille stratégique (par exemple, Power BI) à fonctionner avec un lac de données construit sur la plate-forme Arenadata Hadoop;
- un stockage analytique unifié a été mis en place pour collecter les informations de production à partir des capteurs de l'équipement avec la possibilité de stocker les informations à long terme (le volume prévu de données accumulées pendant un an est d'environ deux téraoctets);
- des mécanismes et des méthodes pour obtenir des données en temps quasi réel ont été développés;
- un algorithme pour déterminer les écarts et le fonctionnement incorrect des capteurs en mode temps quasi réel (calcul - une fois par minute) a été développé;
- des tests du fonctionnement du système et de la capacité à générer des rapports dans l'outil BI ont été réalisés.
L'essentiel est que nous avons résolu complètement un problème de production - nous avons automatisé un processus de routine. Nous avons distribué un outil de prévision et laissé du temps aux technologues pour résoudre des problèmes plus intelligents.
Et si vous avez encore des questions sans commentaires, voici le mail - chemistry@croc.ru