
Au début de cette année, Tenzor a organisé une rencontre dans la ville d'Ivanovo, où j'ai fait une présentation sur des expériences de test de fuzzing de l'interface. Voici une transcription de ce rapport.
Quand les singes remplaceront-ils tous les QA? Est-il possible d'abandonner les tests manuels et les autotests de l'interface utilisateur pour les remplacer par le fuzzing? À quoi ressemblerait un diagramme d'état et de transition complet pour une application TODO simple? Un exemple de mise en œuvre et comment ce fuzzing fonctionne plus loin sous la coupe.
salut! Je m'appelle Sergey Dokuchaev. Depuis 7 ans, je fais des tests sous toutes ses formes chez Tenzor.

Nous avons plus de 400 personnes responsables de la qualité de nos produits. 60 d'entre eux sont dédiés aux tests d'automatisation, de sécurité et de performance. Afin de prendre en charge des dizaines de milliers de tests E2E, de surveiller les indicateurs de performance de centaines de pages et d'identifier les vulnérabilités à l'échelle industrielle, vous devez utiliser des outils et des méthodes qui ont été testés et éprouvés au combat.

Et, en règle générale, ils parlent de tels cas lors de conférences. Mais à part cela, il y a beaucoup de choses intéressantes qui sont encore difficiles à appliquer à l'échelle industrielle. C'est intéressant et parlons-en.

Dans le film "The Matrix" dans l'une des scènes, Morpheus propose à Neo de choisir une pilule rouge ou bleue. Thomas Anderson a travaillé comme programmeur et on se souvient du choix qu'il a fait. S'il était un testeur notoire, il aurait dévoré les deux comprimés pour voir comment le système se comporterait dans des conditions non standard.
La combinaison des tests manuels et des autotests est devenue presque standard. Les développeurs savent le mieux comment leur code fonctionne et écrivent des tests unitaires, les testeurs fonctionnels vérifient les fonctionnalités nouvelles ou qui changent fréquemment, et toute la régression va vers divers autotests.
Cependant, lors de la création et de la maintenance des autotests, il n'y a pas beaucoup de travail automatique et beaucoup de travail manuel:
- Vous devez savoir quoi et comment tester.
- Vous devez trouver les éléments sur la page, conduire les localisateurs nécessaires dans les objets de page.
- Écrivez et déboguez le code.
- — . / , , ROI .
Heureusement, il n'y a pas deux ou trois comprimés dans le monde des tests. Et toute une dispersion: tests sémantiques, méthodes formelles, tests de fuzzing, solutions basées sur l'IA. Et encore plus de combinaisons.

L'affirmation selon laquelle tout singe qui tapera sur une machine à écrire pendant une durée infinie sera capable de taper un texte donné à l'avance a pris racine dans les tests. Cela semble bien, nous pouvons faire en sorte qu'un programme clique à l'infini sur l'écran à des endroits aléatoires et finalement nous pouvons trouver toutes les erreurs.
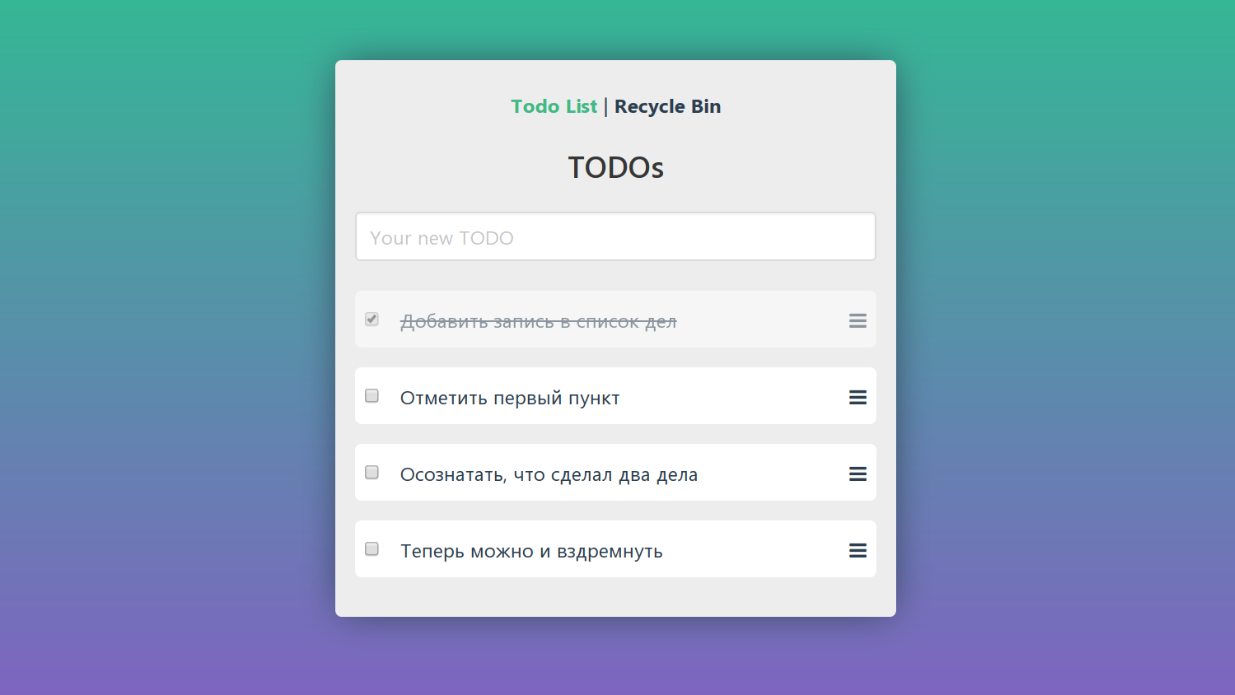
Disons que nous avons fait un tel TODO et que nous voulons le vérifier. Nous prenons un service ou un outil adapté et voyons les singes en action:
Par le même principe, mon chat en quelque sorte, allongé sur le clavier, a irrévocablement cassé la présentation et a dû le refaire:

Il est pratique qu'après 10 actions, l'application lève une exception. Ici, notre singe comprend immédiatement qu'une erreur s'est produite et nous pouvons comprendre à partir des journaux au moins approximativement comment elle se répète. Que faire si l'erreur s'est produite après 100 000 clics aléatoires et ressemble à une réponse valide? Le seul avantage significatif de cette approche est la simplicité maximale - vous appuyez sur un bouton et vous avez terminé.

Le contraire de cette approche est les méthodes formelles.

Il s'agit d'une photographie de New York en 2003. L'un des endroits les plus lumineux et les plus fréquentés de la planète, Times Square n'est éclairé que par les phares des voitures qui passent. Cette année-là, des millions de personnes au Canada et aux États-Unis se sont retrouvées à l'âge de pierre pendant trois jours en raison de l'arrêt d'une centrale électrique en cascade. L'une des principales raisons de l'incident était une erreur de condition de concurrence dans le logiciel.
Les systèmes critiques d'erreurs nécessitent une approche spéciale. Les méthodes qui ne reposent pas sur l'intuition et les compétences, mais sur les mathématiques sont appelées formelles. Et contrairement aux tests, ils vous permettent de prouver qu'il n'y a pas d'erreurs dans le code. Les modèles sont beaucoup plus difficiles à créer qu'à écrire le code qu'ils sont censés tester. Et leur utilisation ressemble plus à la démonstration d'un théorème dans une conférence sur le calcul.

La diapositive montre une partie du modèle de l'algorithme à deux prises de contact écrit en langage TLA +. Je pense qu'il est évident pour tout le monde que l'utilisation de ces outils lors de la vérification des moisissures sur le site est comparable à la construction d'un Boeing 787 pour tester les propriétés aérodynamiques d'une plante de maïs.

Même dans les industries médicales, aérospatiales et bancaires traditionnellement sujettes aux erreurs, il est très rare d'utiliser cette méthode de test. Mais l'approche elle-même est irremplaçable si le coût d'une erreur est calculé en millions de dollars ou en vies humaines.
Les tests de fuzzing sont désormais le plus souvent considérés dans le contexte des tests de sécurité. Et nous prendrons un schéma typique illustrant cette approche du guide OWASP :

Ici, nous avons un site qui doit être testé, il existe une base de données avec des données de test et des outils avec lesquels nous enverrons les données spécifiées au site. Les vecteurs sont des chaînes ordinaires obtenues de manière empirique. Ces chaînes sont les plus susceptibles de conduire à la découverte d'une vulnérabilité. C'est comme le guillemet que de nombreuses personnes mettent automatiquement à la place des nombres dans l'URL de la barre d'adresse.
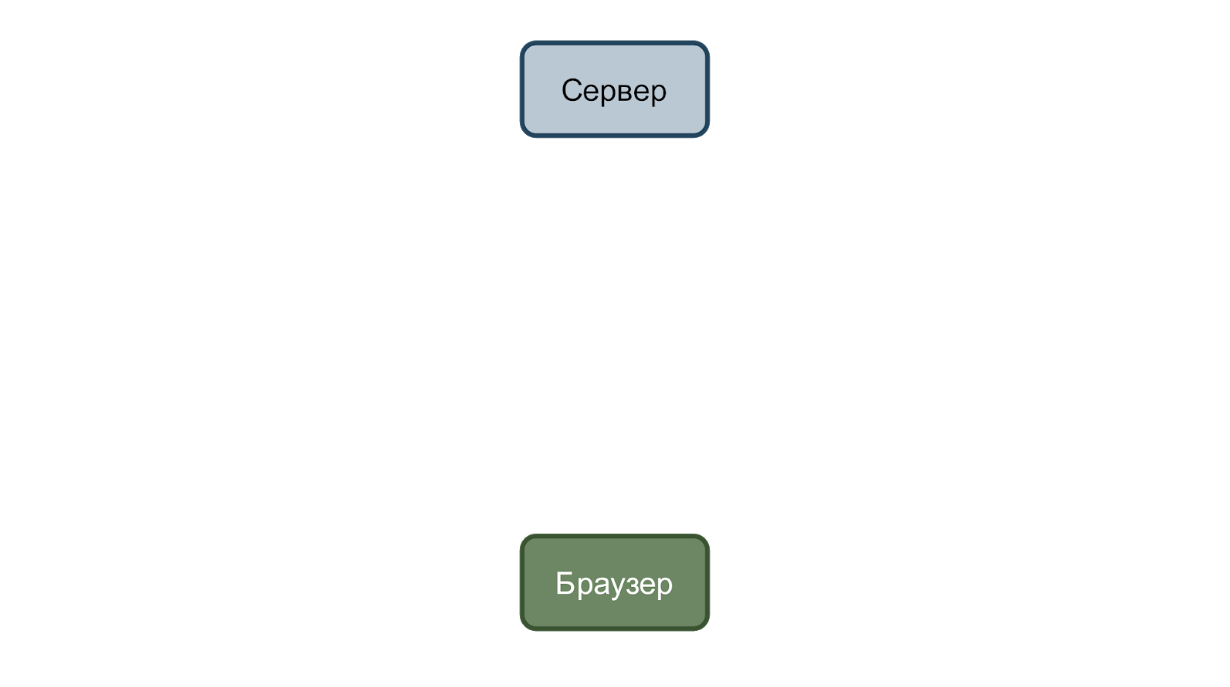
Dans le cas le plus simple, nous avons un service qui accepte les demandes et un navigateur qui les envoie. Prenons l'exemple d'un changement de la date de naissance de l'utilisateur.

L'utilisateur entre une nouvelle date et clique sur le bouton «Enregistrer». Une requête est envoyée au serveur avec des données au format json.
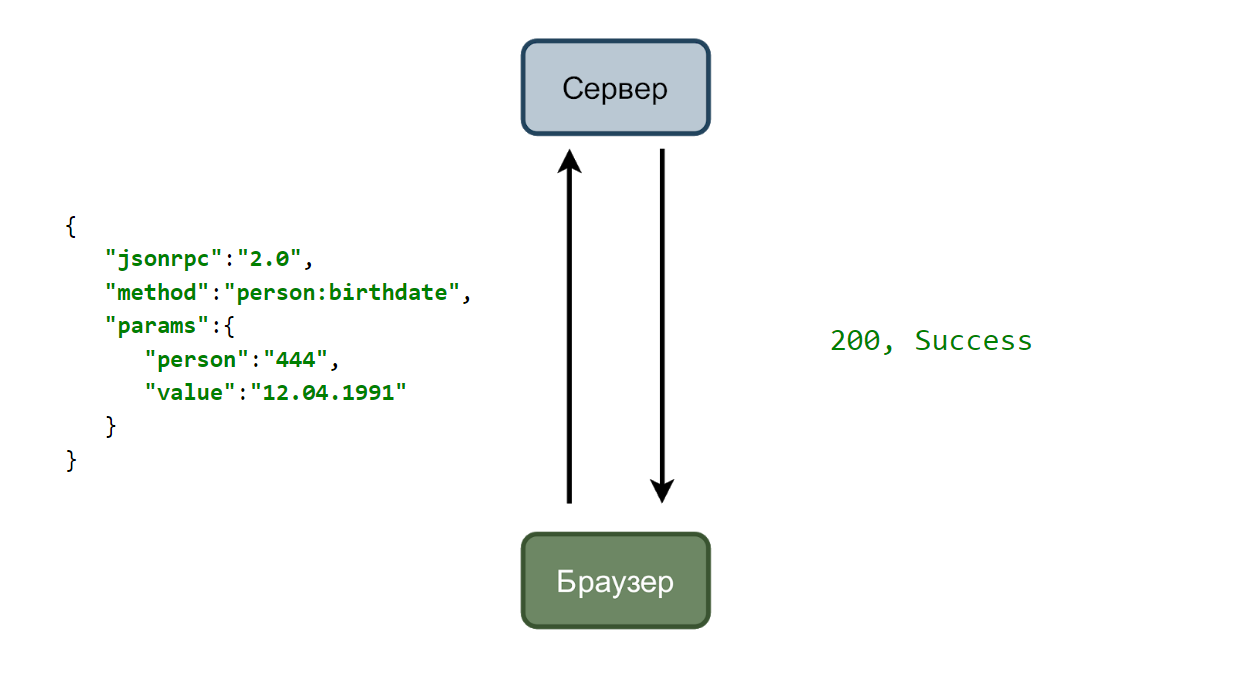
Et si tout va bien, le service répond avec 200 codes.

Il est pratique de travailler avec json par programmation et nous pouvons apprendre à notre outil de fuzzing à trouver et à déterminer les dates dans les données transmises. Et il commencera à leur substituer diverses valeurs, par exemple, il transmettra un mois inexistant.

Et si nous recevons une exception au lieu d'un message concernant une date non valide en réponse, nous corrigeons l'erreur.
Fuzzing une API n'est pas difficile. Ici, nous avons les paramètres transmis dans json, ici nous envoyons une requête, recevons une réponse et l'analysons. Qu'en est-il de l'interface graphique?
Jetons à nouveau un coup d'œil au programme à partir de l'exemple de test factice. Dans celui-ci, vous pouvez ajouter de nouvelles tâches, marquer comme terminé, supprimer et afficher le panier.
Si nous traitons de la décomposition, nous verrons que l'interface n'est pas un monolithe unique, elle est également constituée d'éléments séparés:
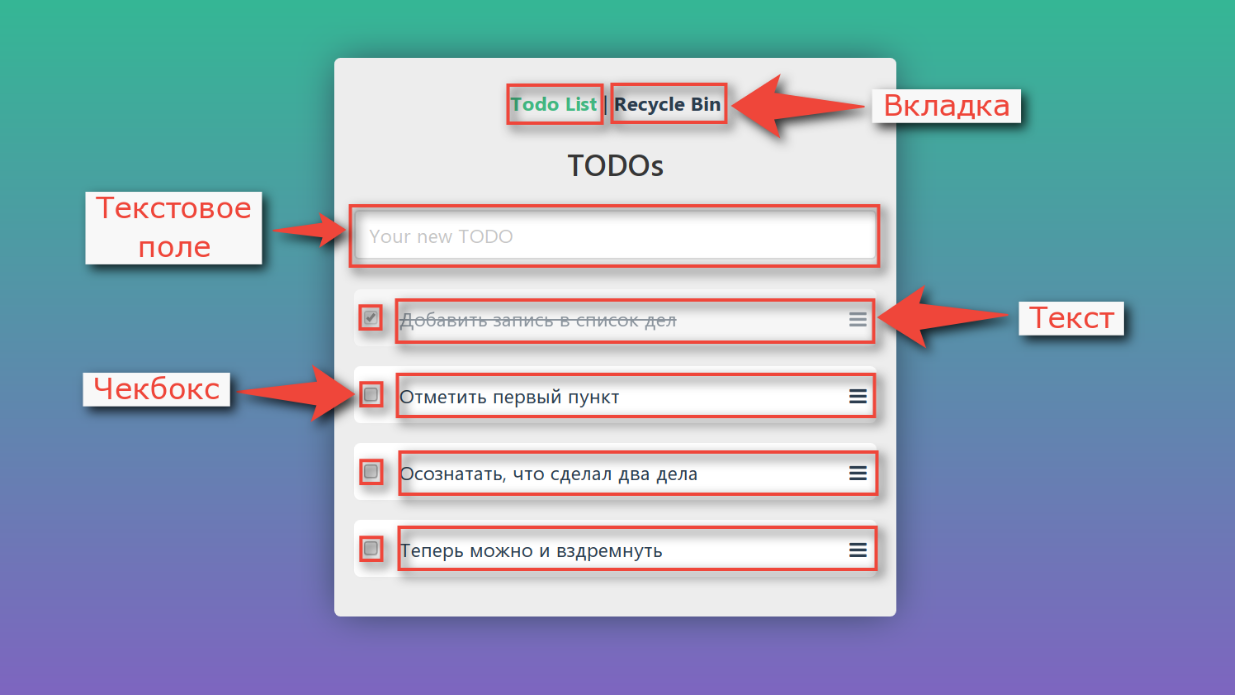
Nous ne pouvons pas faire grand-chose avec chacun des contrôles. Nous avons une souris avec deux boutons, une molette et un clavier. Vous pouvez cliquer sur un élément, déplacer le curseur de la souris dessus, vous pouvez saisir du texte dans les champs de texte.
Si nous saisissons du texte dans le champ de texte et appuyez sur Entrée, notre page passera d'un état à un autre:
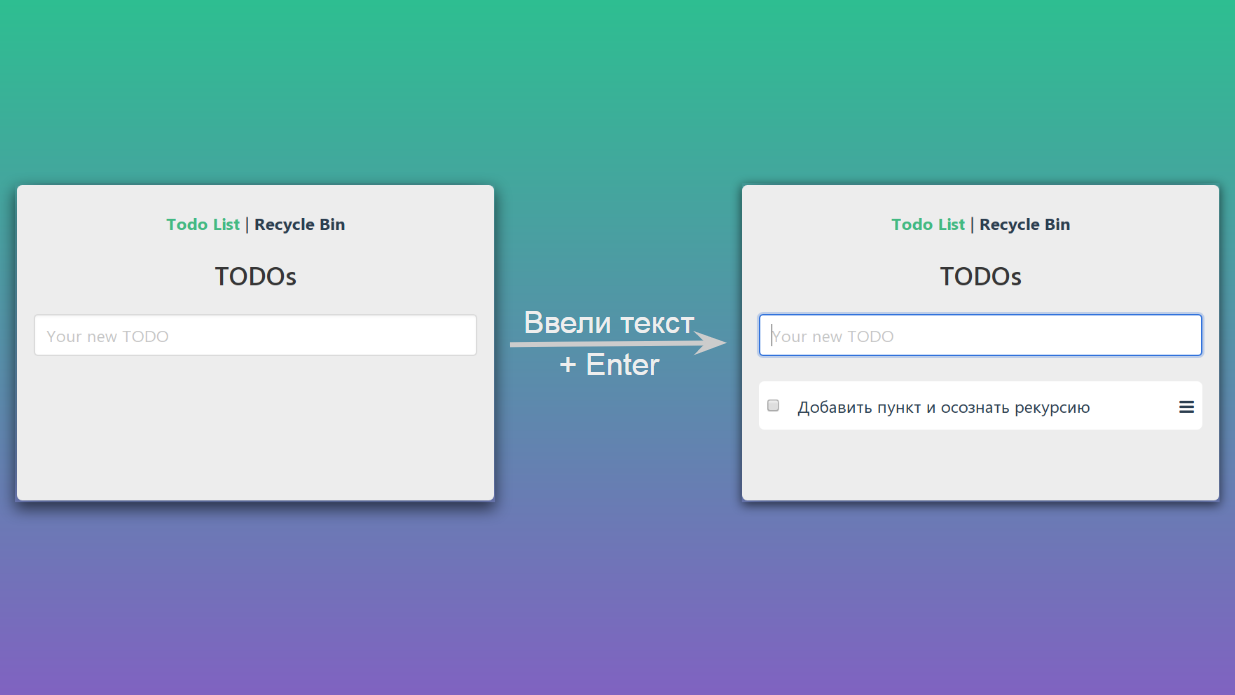
schématiquement, elle peut être représentée comme suit: à

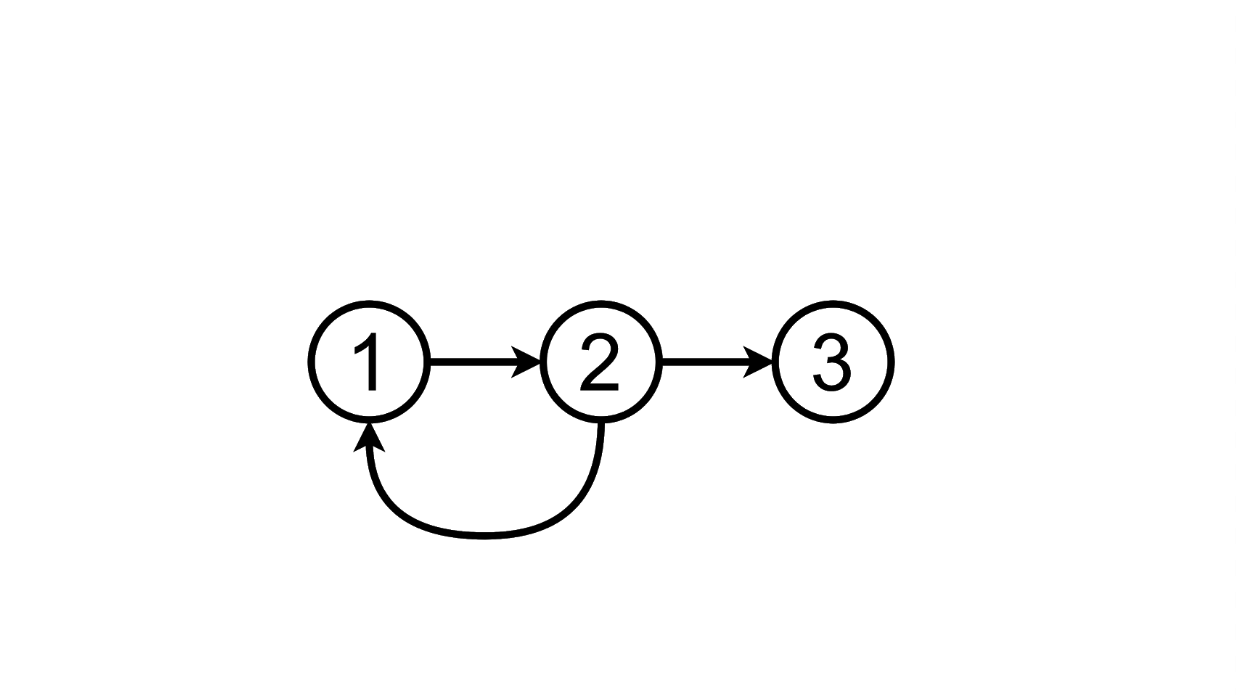
partir de cet état, nous pouvons aller au troisième en ajoutant une autre tâche à la liste:
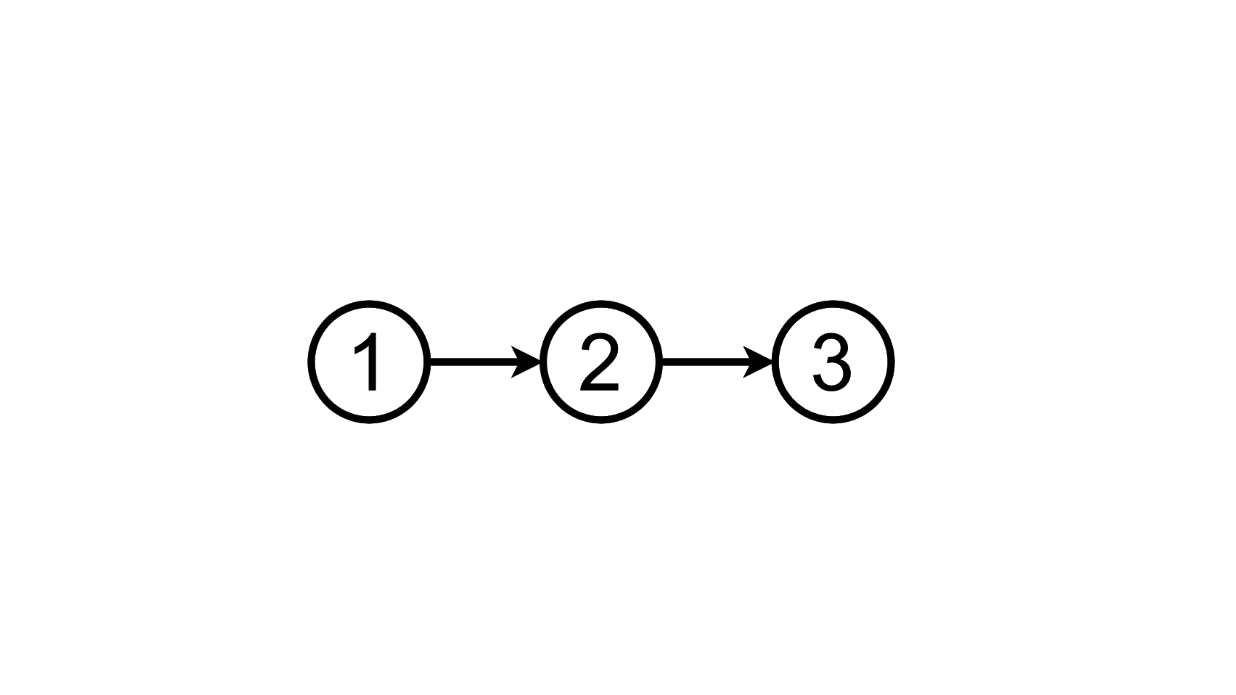
et nous pouvons supprimer l'ajout tâche, retour au premier état:
Ou cliquez sur l'étiquette TODOs et restez dans le deuxième état:
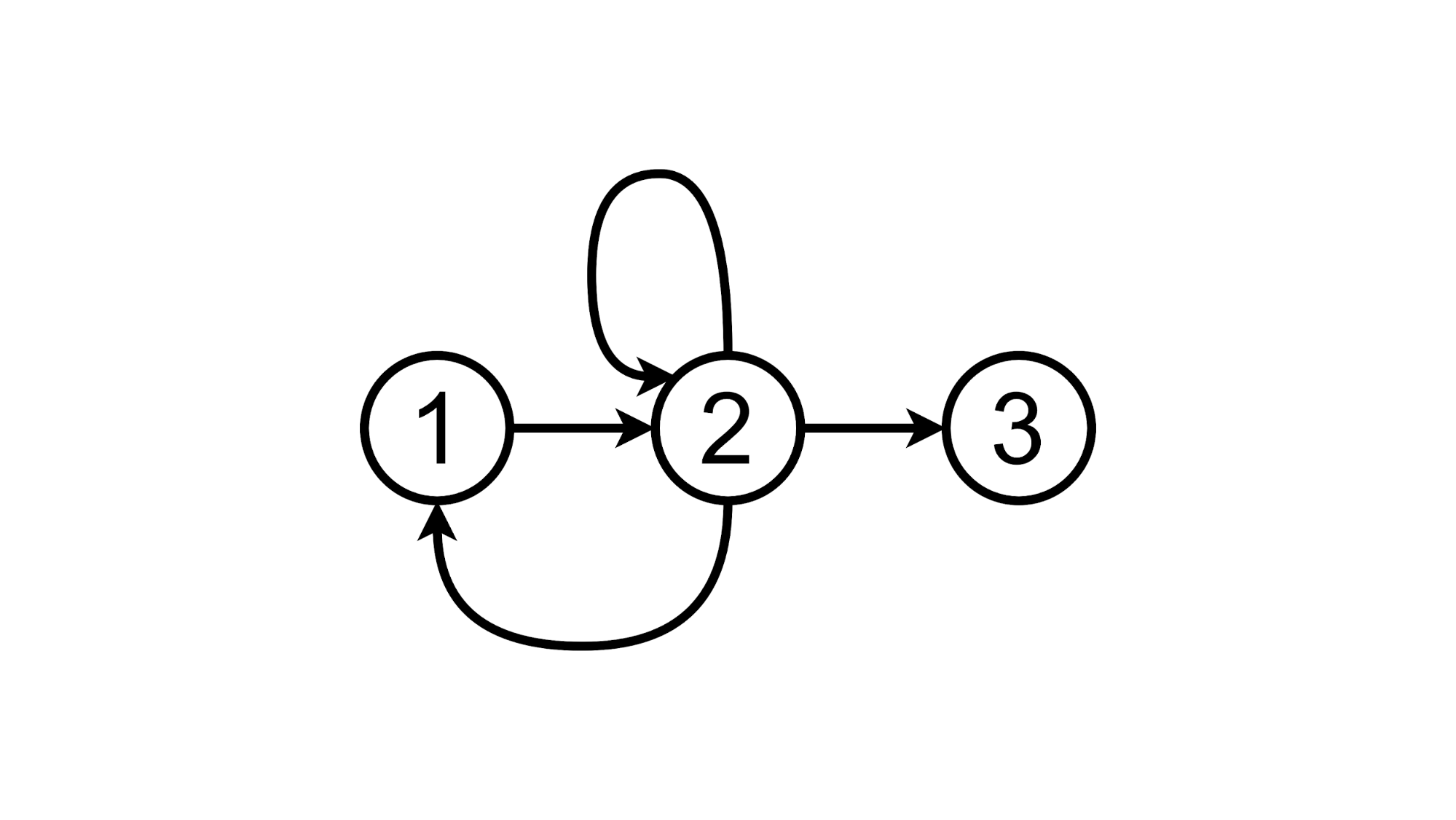
Et maintenant essayons d'implémenter la preuve de concept de cette approche.

Pour travailler avec le navigateur, nous prendrons un pilote chromé, nous travaillerons avec le diagramme d'état et les transitions via la bibliothèque python NetworkX, et nous allons dessiner à travers yEd.

Nous lançons le navigateur, créons une instance de graphe, dans laquelle il peut y avoir de nombreuses connexions avec des directions différentes entre deux sommets. Et nous ouvrons notre application.

Il faut maintenant décrire l'état de l'application. Grâce à l'algorithme de compression d'image, nous pouvons utiliser la taille de l'image PNG comme identifiant d'état et, via la méthode __eq__, implémenter une comparaison de cet état avec d'autres. Grâce à l'attribut itéré, nous enregistrons que tous les boutons ont été cliqués, que des valeurs ont été entrées dans tous les champs dans cet état, afin d'exclure le retraitement.

Nous écrivons un algorithme de base qui contournera toute l'application. Ici, nous fixons le premier état du graphe, dans la boucle nous cliquons sur tous les éléments dans cet état et fixons les états résultants. Ensuite, sélectionnez le prochain état non traité et répétez les étapes.

Lors du fuzzing de l'état actuel, il faut à chaque fois revenir à cet état à partir d'un nouvel état. Pour ce faire, nous utilisons la fonction nx.shortest_path, qui retournera une liste d'éléments sur lesquels il faut cliquer pour passer de l'état de base à l'état actuel.
Afin d'attendre la fin de la réponse de l'application à nos actions, la fonction d'attente utilise l'API Network Long Task, qui montre si JS est occupé par un travail.
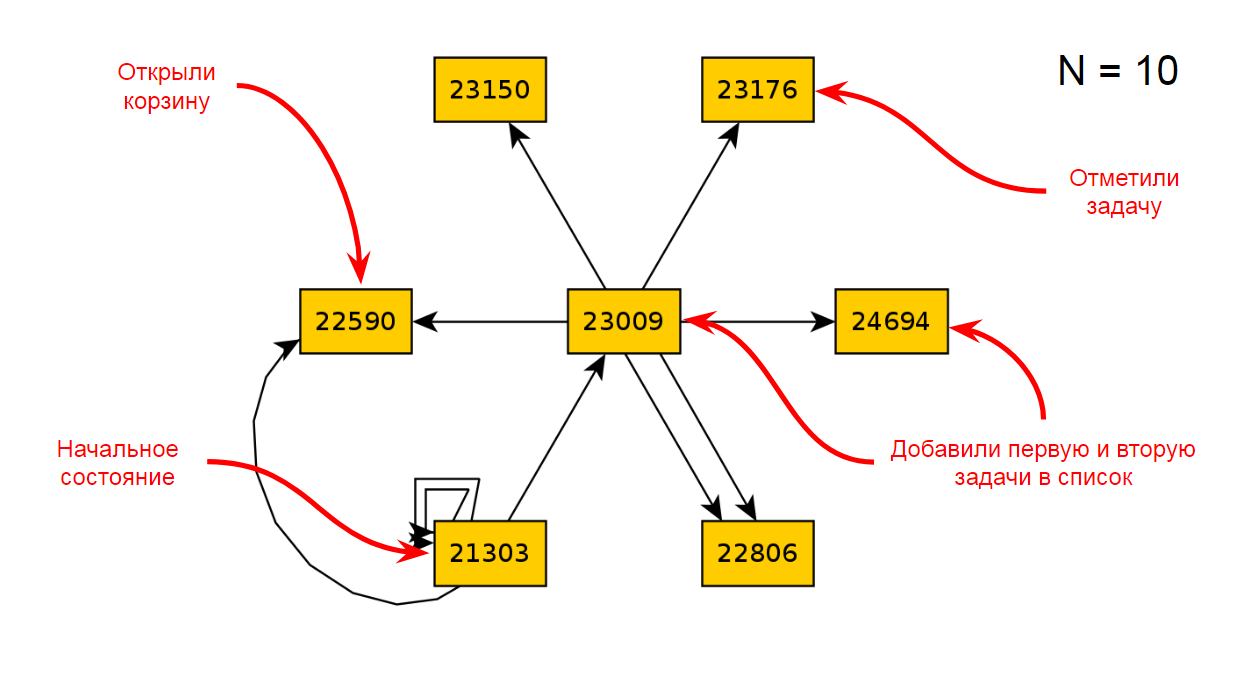
Revenons à notre application. L'état initial est le suivant:
Après dix itérations de l'application, nous obtiendrons le diagramme d'états et de transitions suivant:
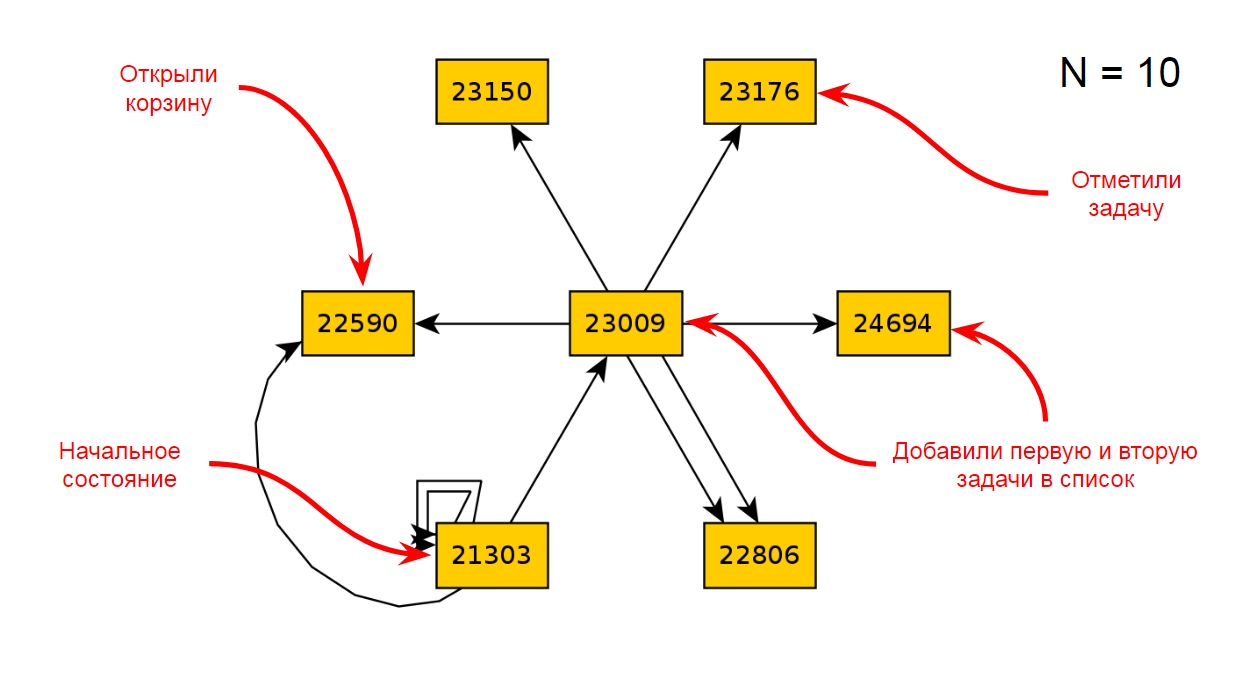
Après 22 itérations, c'est le suivant:
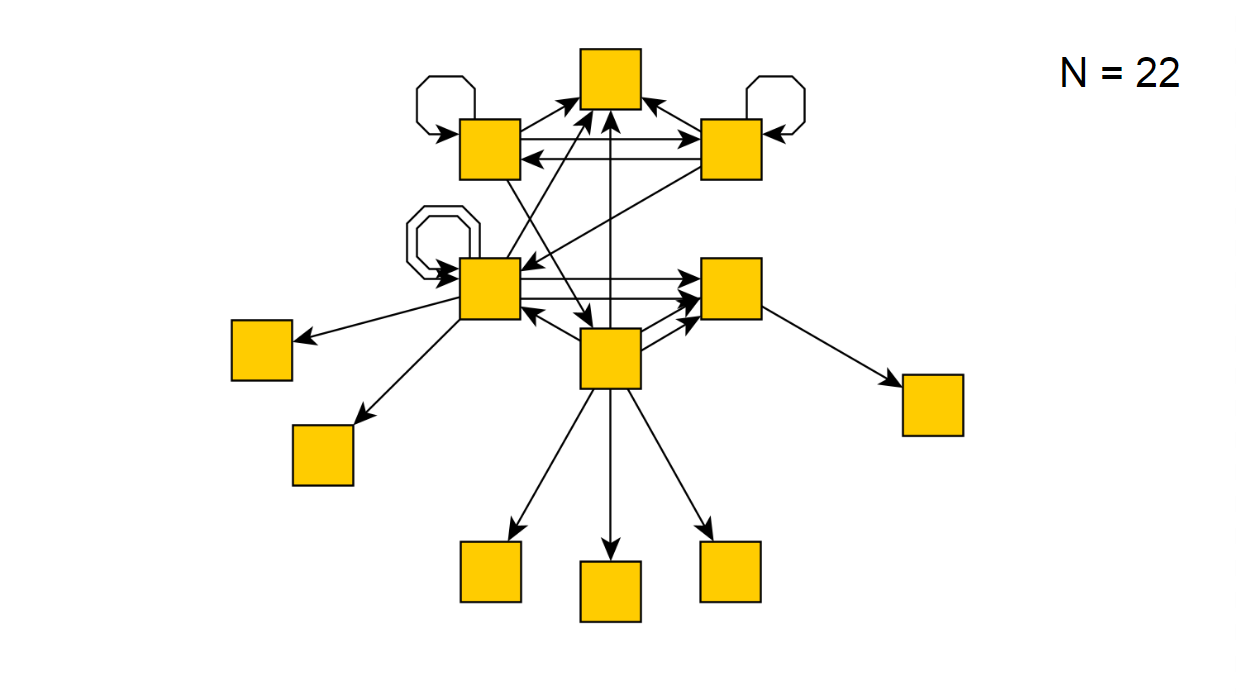
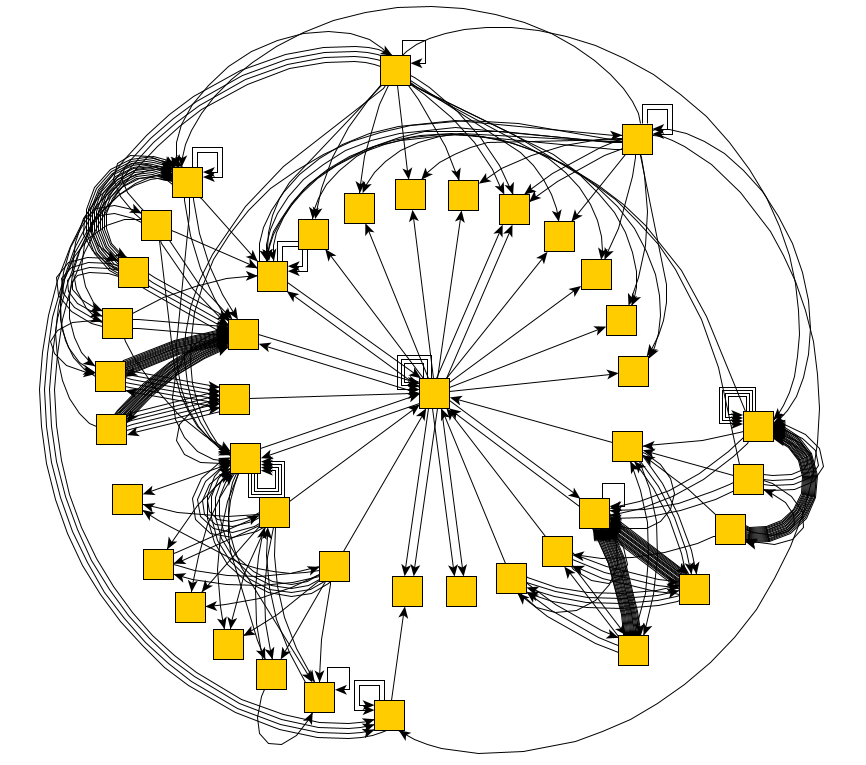
Si nous exécutons notre script pendant plusieurs heures, il signalera soudainement qu'il a contourné tous les états possibles, recevant le diagramme suivant:

Donc, avec une simple application de démonstration nous l'avons fait. Et que se passe-t-il si vous définissez ce script sur une vraie application Web. Et il y aura du chaos:
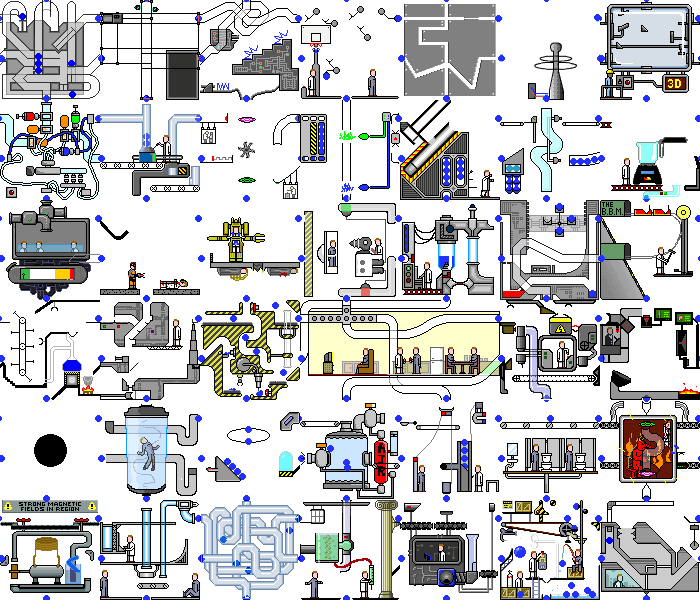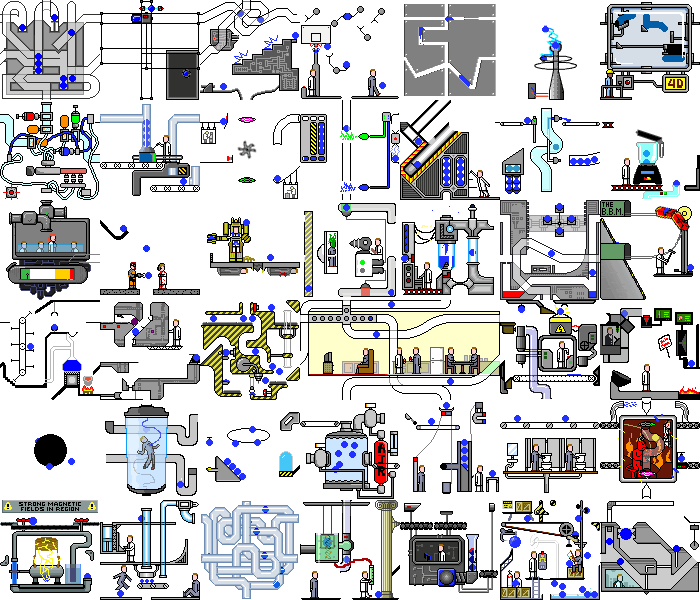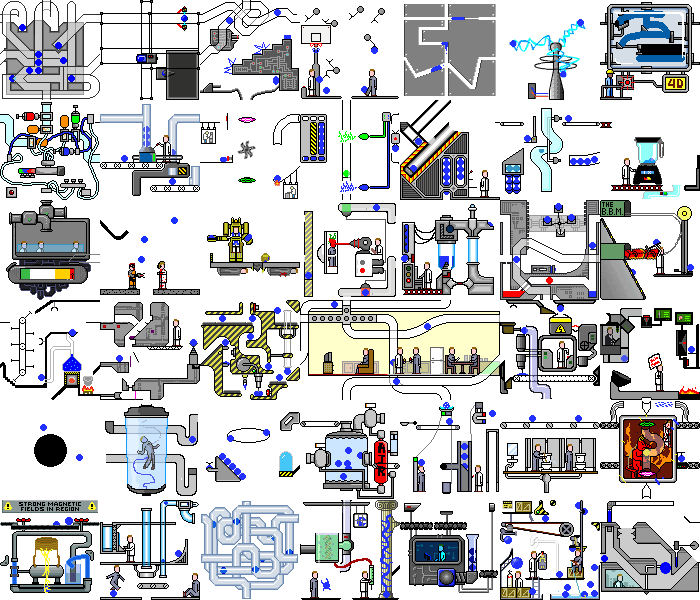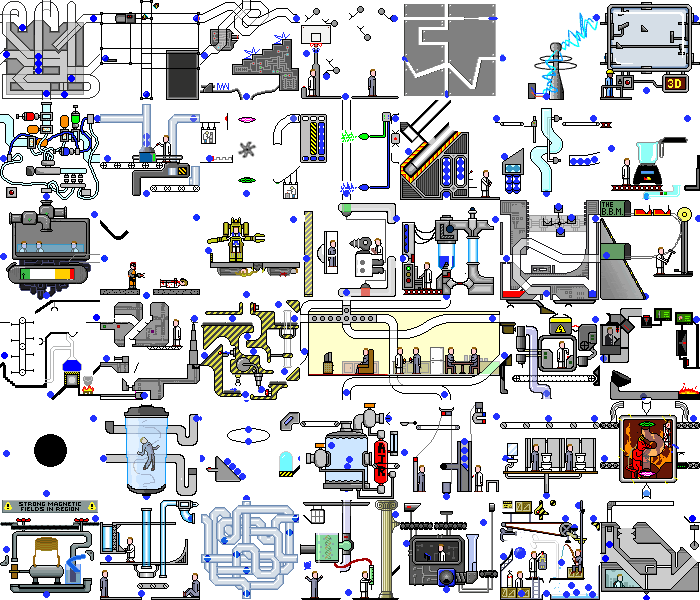
non seulement des changements se produisent sur le backend, mais la page elle-même est constamment redessinée lors de la réaction à des minuteries ou des événements, en effectuant les mêmes actions, nous pouvons obtenir des états différents. Mais même dans de telles applications, vous pouvez trouver des fonctionnalités que notre script peut gérer sans modifications importantes.
Prenons-le pour testerPage d'authentification VLSI:

Et pour cela, il s'est avéré assez rapidement de construire un diagramme complet des états et des transitions:

Excellent! Nous pouvons maintenant parcourir tous les états de l'application. Et purement en théorie, trouvez toutes les erreurs qui dépendent des actions. Mais comment apprendre à un programme à comprendre qu'il y a une erreur devant lui?
Lors des tests, les réponses du programme sont toujours comparées à une certaine norme appelée oracle. Il peut s'agir de spécifications techniques, de maquettes, d'analogues de programme, de versions précédentes, d'expérience de testeur, d'exigences formelles, de cas de test, etc. Nous pouvons également utiliser certains de ces oracles dans notre outil.

Considérons le dernier modèle «c'était différent avant». Les autotests sont engagés dans des tests de régression.
Revenons au graphique après 10 itérations de TODO:
Décomposons le code qui est responsable de l'ouverture du panier et exécutons à nouveau 10 itérations:
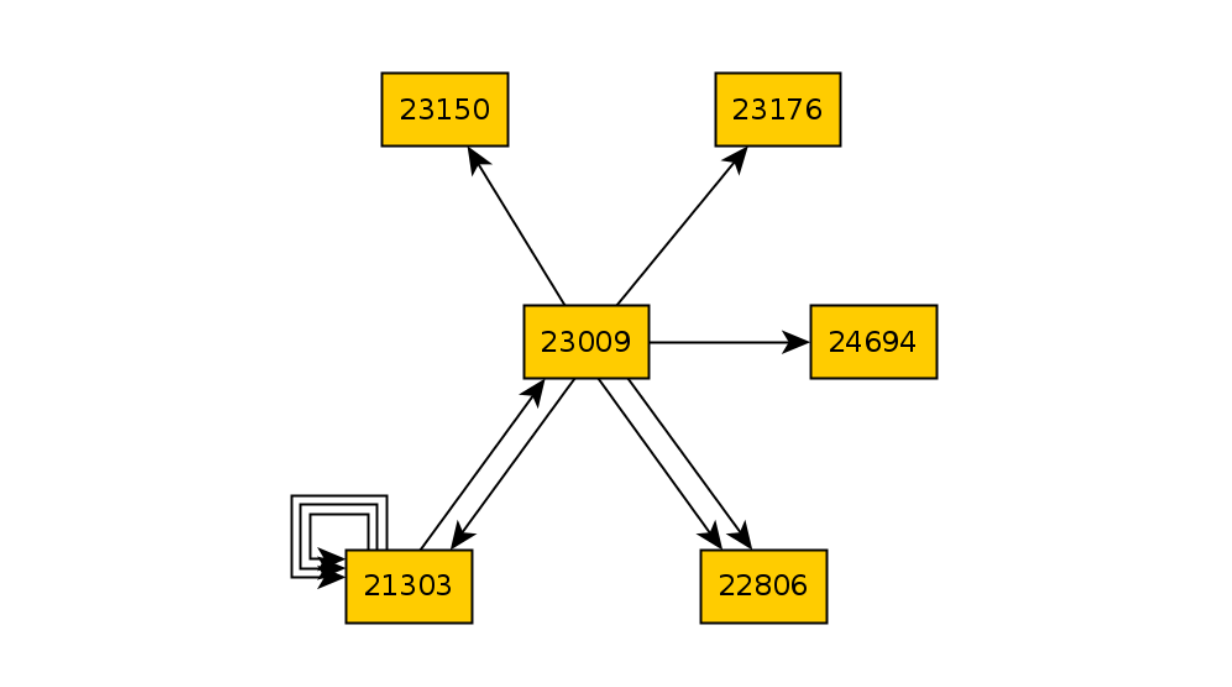
Et puis comparons les deux graphiques et trouvons la différence d'états:
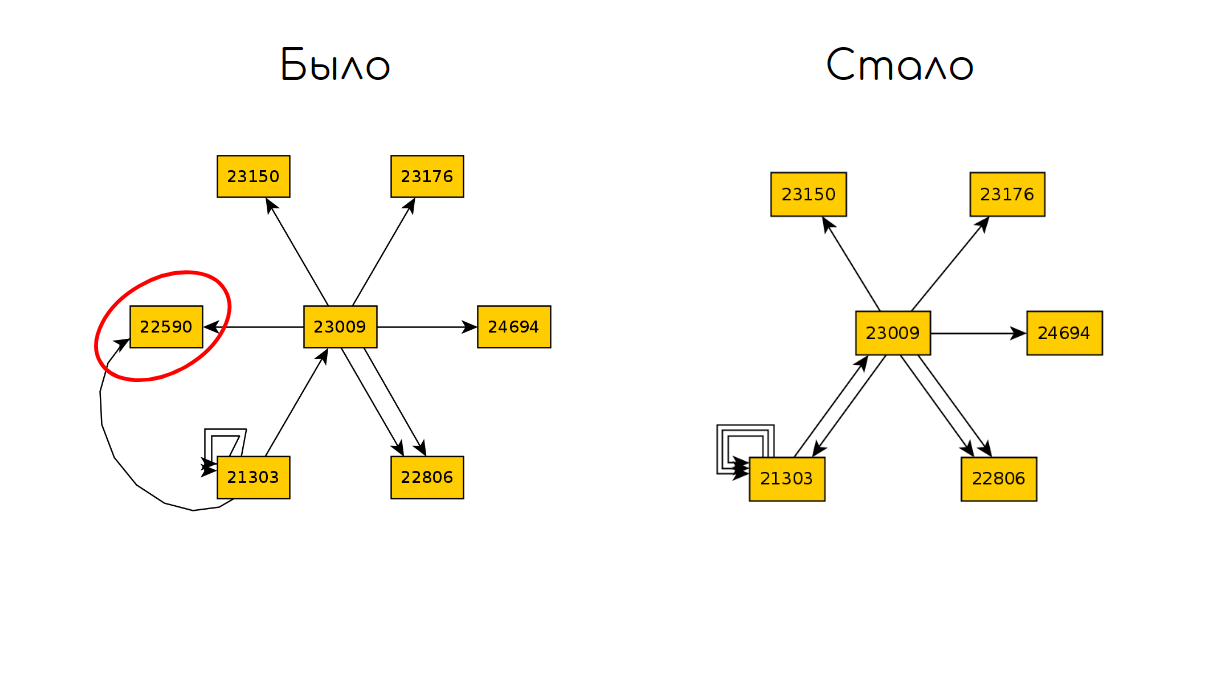
Nous pouvons résumer pour cette approche:

En l'état actuel, cette technique peut être utilisée pour tester une petite application et identifier des erreurs évidentes ou de régression. Pour que la technique décolle pour les applications volumineuses avec des interfaces graphiques instables, des améliorations significatives sont nécessaires.
Tout le code source et une liste des matériaux utilisés peuvent être trouvés dans le référentiel: https://github.com/svdokuchaev/venom . Pour ceux qui veulent comprendre l'utilisation du fuzzing dans les tests, je recommande vivement The Fuzzing Book . Là, dans l'une des parties, la même approche du fuzzing de formulaires HTML simples est décrite .
