
Par exemple, vous disposez d'une bibliothèque de documents SharePoint. Lorsque vous ajoutez un fichier à cette bibliothèque, vous fournissez souvent en plus le fichier avec certaines métadonnées. Créez plusieurs champs et écrivez-y des informations afin de classer les fichiers de cette bibliothèque. Mais cela se fait manuellement et pour chaque fichier, vous devez saisir des données à chaque fois, encore et encore. SharePoint Syntex est conçu pour automatiser ce processus en extrayant les données clés d'un fichier selon un modèle personnalisé et en enregistrant ces données dans les champs de la bibliothèque. Ça sonne bien. Voyons voir comment ça fonctionne?
Comment activer SharePoint Syntex?
Étant donné que SharePoint Syntex relève d'une licence distincte, nous devons obtenir cette licence. Accédez au site Web de Microsoft, recherchez le produit SharePoint Syntex et cliquez sur «Essai gratuit».

Après avoir entré votre compte Microsoft 365 et confirmé l'activation de la licence d'évaluation, accédez au centre d'administration Microsoft 365. Ensuite, accédez à la section «Configuration» dans le menu de gauche et sélectionnez l'élément Automatiser la compréhension du contenu. Dans le cas d'un environnement local russe, comme le mien, cela ressemblera à «Automatisation de la compréhension du contenu».
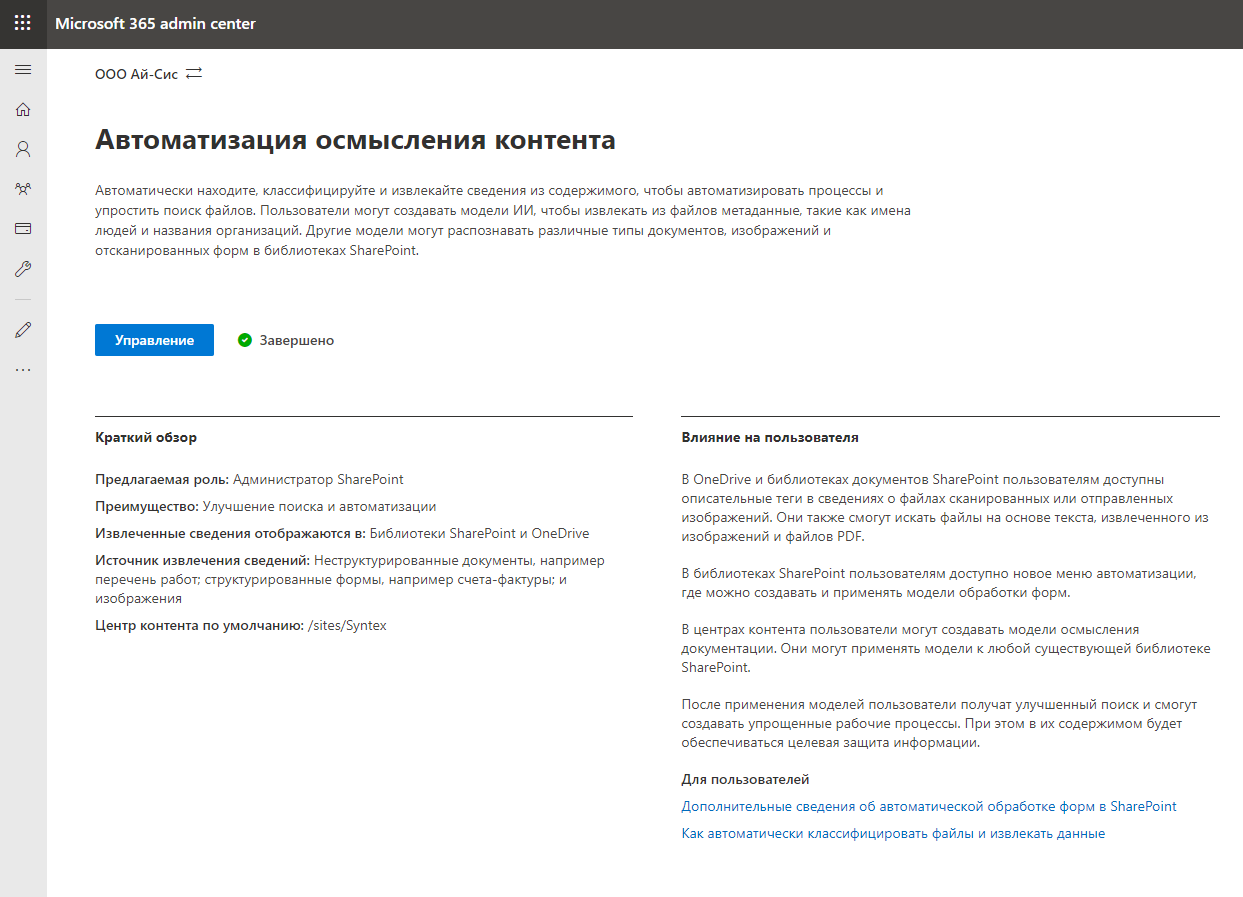
Nous allons dans "Gestion" et procédons à la mise en place du service. Tout d'abord, il est nécessaire d'indiquer quelles bibliothèques prendront en charge les fonctionnalités de SharePoint Syntex. Vous pouvez sélectionner des bibliothèques spécifiques ou autoriser toutes les bibliothèques. Allons-y pour rien.
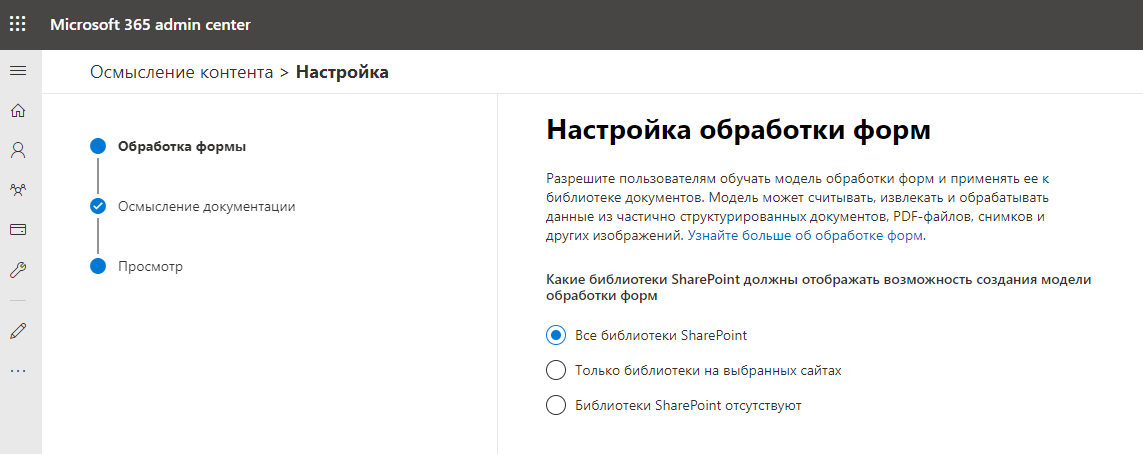
Ensuite, nous indiquons le nom et l'adresse du site, qui sera le centre de contenu et stockera les modèles de données formés. Il semble qu'un nouveau site de collection SharePoint Online est en cours de création. Cependant, c'est exactement ce qui se passe.
La création d'un site de centre de contenu prend quelques minutes. Cela m'a pris environ 5 minutes, j'ai juste réussi à me verser du thé. J'arrive, et ici la compréhension du contenu a déjà été activée, eh bien, wow.
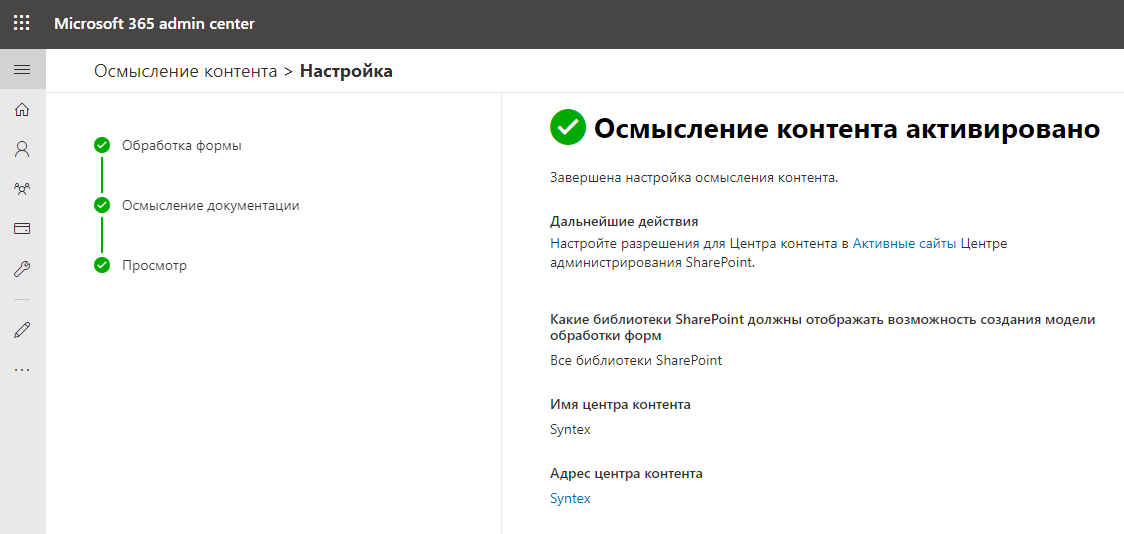
Configuration de SharePoint Syntex
Accédez au site SharePoint Syntex. Extérieurement, cela ressemble à un site SharePoint Online normal, mais ce n'est qu'à première vue. Sur ce site, nous mettrons en place et formerons des modèles de traitement et d'analyse des données.
Il est temps de commencer à configurer le modèle. Cliquez sur "Nouveau" et sélectionnez l'élément "Modèle de compréhension du document".
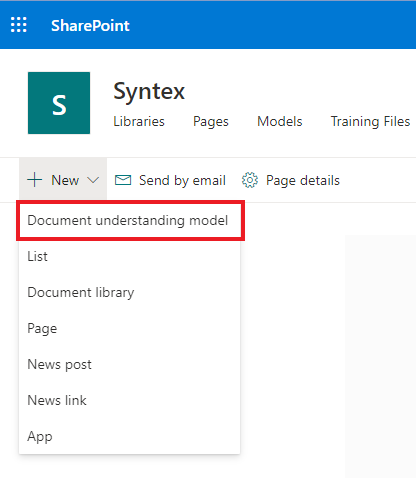
Nous écrivons le nom de notre futur modèle et indiquons la nécessité de créer un nouveau type de contenu pour celui-ci. J'ai déjà choisi un cas, qui vous est probablement familier des articles précédents, avec une demande de support technique. Ne supprimez pas le même ensemble de modèles pour de tels appels.
Ensuite, nous sommes accueillis par une page avec des instructions étape par étape décrivant ce que nous devons faire pour que le futur modèle fonctionne, et idéalement fonctionner correctement. Donc, vous devez d'abord télécharger quelques fichiers (au moins 5 est recommandé), aider SharePoint Syntex à les classer selon les besoins et configurer les soi-disant «extracteurs» - des modèles pour extraire les données des fichiers. Une fois que vous êtes allé jusqu'au bout, vous pouvez appliquer ce modèle aux bibliothèques SharePoint requises.
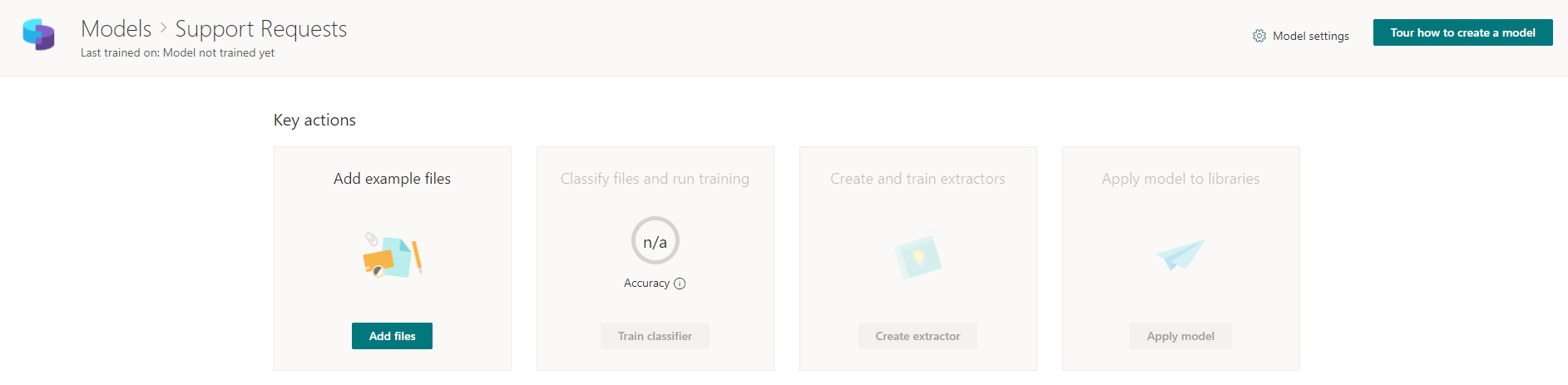
Ajoutez des fichiers modèles préparés qui seront utilisés pour classer les futurs fichiers réels.
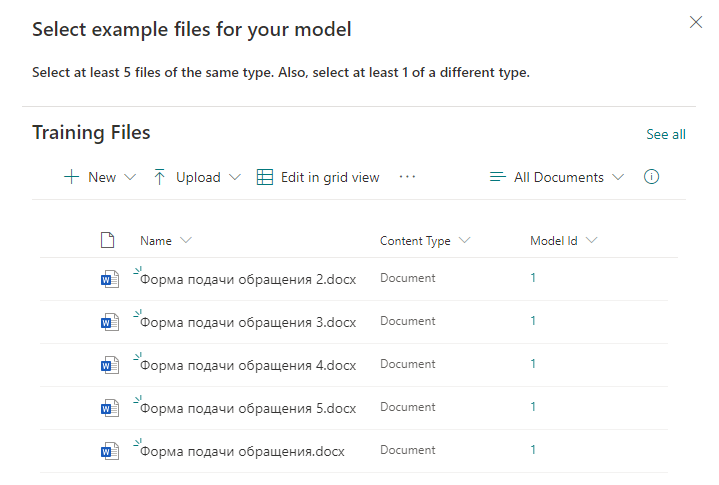
Ensuite, nous indiquons les mots-clés par lesquels la recherche d'informations dans le document sera effectuée. Dans chaque ligne, nous indiquons un nouveau mot ou une nouvelle phrase qui sera utilisé pour la recherche.
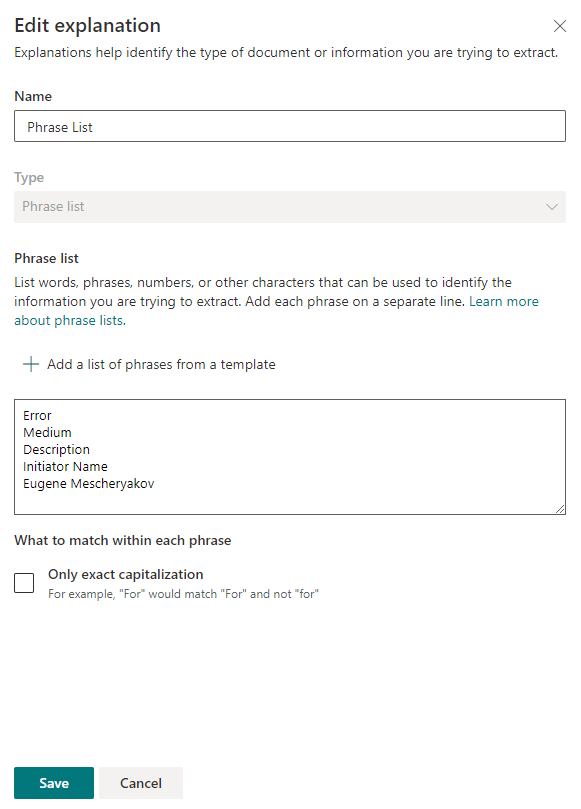
Après avoir enregistré les paramètres, vous pouvez essayer de scanner les fichiers existants à la recherche de phrases clés. Si une correspondance est trouvée, alors à côté du fichier sera "Match".
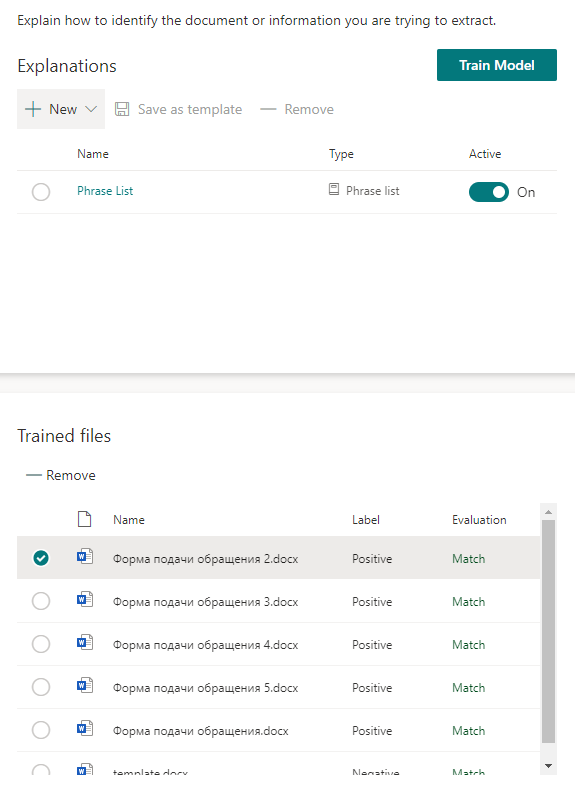
Nous commençons à former le modèle et allons verser le thé. Cela prendra du temps.
Une fois le modèle entraîné, il est nécessaire de configurer les "Extracteurs" - modèles d'extraction de données. Chaque extracteur est essentiellement un type spécifique de champ SharePoint qui sera automatiquement généré dans la bibliothèque cible. Après avoir ajouté un fichier à cette bibliothèque, les informations extraites du fichier seront écrites dans ce champ.
Lors de la création d'un extracteur, vous devez spécifier son nom et son type. Actuellement, 4 types sont pris en charge:
- Texte sur une seule ligne
- Texte multiligne
- date et l'heure
- Nombre
Vous pouvez également utiliser des champs existants dans une bibliothèque SharePoint.
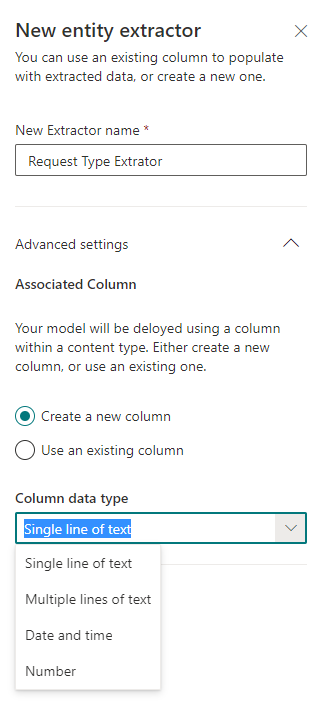
Lors de la mise en place de l'extracteur dans le modèle du fichier téléchargé, double-cliquez sur les informations que nous voulons extraire, reconnues à l'étape précédente.
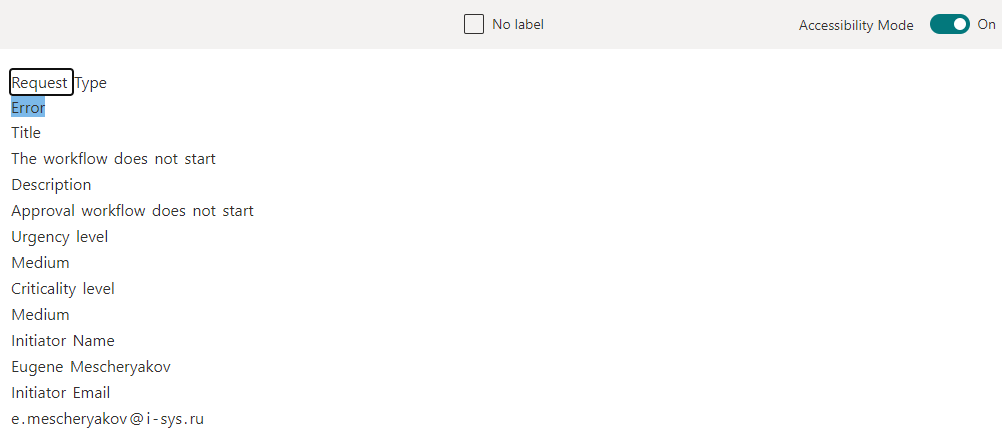
Nous créons plusieurs extracteurs de ce type, marquons les données nécessaires et, après cela, passons à la dernière partie: appliquer le modèle entraîné à la bibliothèque SharePoint et vérifier si tout fonctionne.

Sélectionnez le site SharePoint requis et spécifiez la bibliothèque cible. J'ai créé la bibliothèque de requêtes HelpDesk à l'avance et je n'y ai apporté aucune modification, la laissant dans sa forme d'origine. Nous enregistrons les paramètres et allons à la bibliothèque. Après avoir enregistré les paramètres SharePoint Syntex, de nouveaux champs SharePoint apparaissent dans la bibliothèque, correspondant par nom et par type aux extracteurs créés.
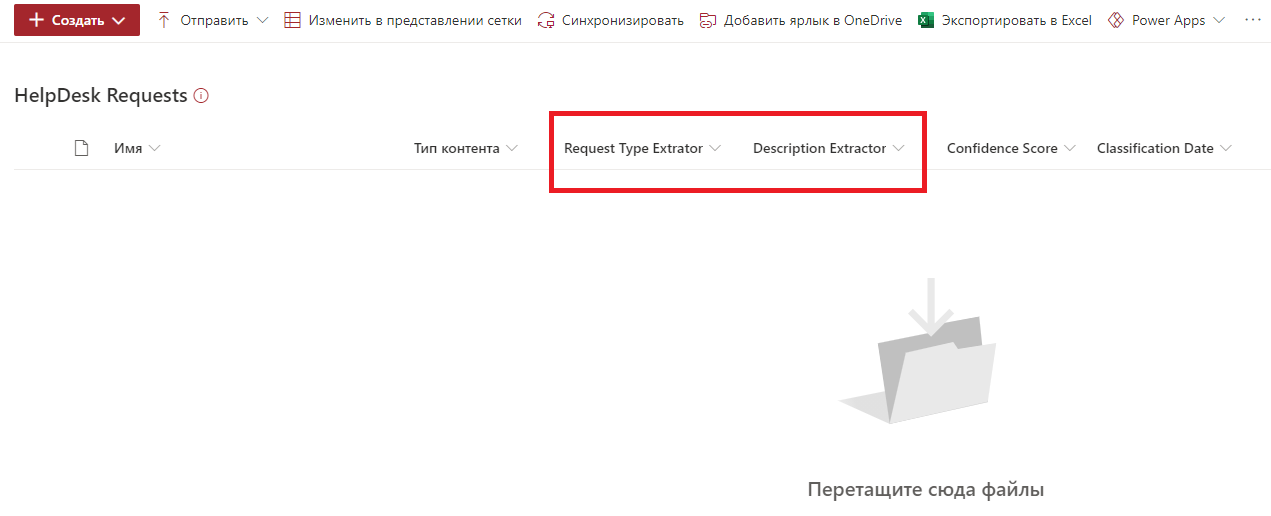
Il reste à ajouter le fichier à la bibliothèque et à vérifier. Ajoutez un autre fichier de modèle de demande.

SharePoint Syntex a reconnu le type et la description du cas. Les données sont stockées dans des champs. Tout semble être en ordre.
Total
La configuration du modèle de données SharePoint Syntex m'a pris très peu de temps, tout est assez intuitif et facile à configurer et à utiliser. Des pros, je vois une capacité vraiment utile d'extraire automatiquement les informations clés du contenu du fichier et de les écrire dans les champs SharePoint. Cette fonctionnalité peut considérablement accélérer le travail et supprimer les étapes inutiles du travail de l'utilisateur lorsque, après l'ajout d'un fichier, il est nécessaire de remplir manuellement un certain nombre de conditions requises dans la bibliothèque. Inconvénients - Je voudrais plus de types de champs pour les extracteurs et une intégration plus étroite avec Microsoft Power Platform. Mais je suis sûr que cela sera ajouté prochainement dans le cadre des prochaines mises à jour.
De plus, SharePoint Syntex nécessite une licence distincte (5 $ par utilisateur et par mois) et, pour le moment, n'est pas inclus dans les licences Entreprise de Microsoft 365. Mais à l'avenir, tout peut changer et peut-être que SharePoint Syntex fera partie des services de base de Microsoft 365. Essayez d'activer la version d'essai pendant un mois et découvrez les capacités de ce service. Très bonne journée à tous!