
le flux de données dans ce tableau est un peu difficile à suivre, voici donc un graphique équivalent qui représente le tableau sous forme de graphique:

Arrondissez le coût du burrito super vegi El Farolito à 8 $, donc à la livraison d'une valeur de 2 $, le montant total sera de 20 $.
Oh, j'ai complètement oublié! Un de mes amis ne suffit pas pour un burrito, il en a besoin de deux. Alors je veux vraiment en commander trois. S'il est mis à jour
Num Burritos
, le moteur de feuille de calcul naïf peut recalculer le document entier en recalculant d'abord les cellules sans entrée, puis en recalculant chaque cellule avec l'entrée prête jusqu'à ce que les cellules soient épuisées. Dans ce cas, nous calculerons d'abord le prix et la quantité du burrito, puis le prix d'expédition du burrito, puis un nouveau total de 30 $.

Cette stratégie simple de recalculer un document entier peut sembler inutile, mais c'est en fait mieux que VisiCalc, les premières feuilles de calcul de l'histoire et la première application dite tueur qui a rendu les ordinateurs Apple II populaires. VisiCalc a recalculé les cellules de gauche à droite et de haut en bas à plusieurs reprises, les analysant encore et encore, bien qu'aucune d'elles n'ait changé. Malgré cet algorithme «intéressant», VisiCalc est resté le tableur dominant pendant quatre ans. Son règne a pris fin en 1983, lorsque Lotus 1-2-3 a repris le marché du recalcul d'ordre naturel. C'est ainsi que Tracy Robnett Licklider l'a décrit dans le magazine Byte :
Lotus 1-2-3 utilisait un ordre naturel, bien qu'il prenne également en charge les modes de ligne et de colonne VisiCalc. Le recalcul naturel a maintenu une liste de dépendances de cellules et de cellules recalculées en fonction des dépendances.
Lotus 1-2-3 a implémenté la stratégie de recalculer tout indiquée ci-dessus. Au cours de la première décennie de développement du tableur, c'était l'approche la plus optimale. Oui, nous recalculons chaque cellule du document, mais une seule fois.
Mais qu'en est-il du prix d'un burrito de livraison
Vraiment. Dans mon exemple de trois burritos, il n'y a aucune raison de recalculer le prix d'un burrito avec livraison, car changer la quantité de burritos dans la commande ne peut pas affecter le prix du burrito. En 1989, l'un des concurrents de Lotus a compris cela et a créé SuperCalc5, en le nommant probablement d'après la théorie du super burrito derrière l'algorithme. SuperCalc5 a recalculé "uniquement les cellules qui dépendent des cellules modifiées", de sorte que la mise à jour du nombre de burrito ressemblait à ceci:
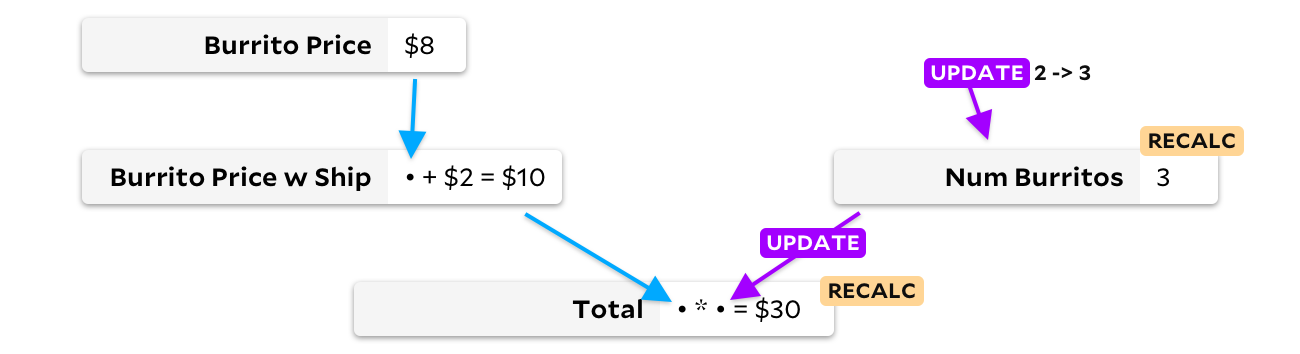
En mettant à jour la cellule uniquement lorsque les données d'entrée changent, nous pouvons éviter de recalculer le prix du burrito avec livraison. Dans ce cas, nous n'enregistrerons qu'un seul ajout, mais dans les grandes feuilles de calcul, les économies peuvent être beaucoup plus importantes! Malheureusement, nous avons un problème différent maintenant. Disons que mes amis veulent maintenant des burritos à la viande, qui sont un dollar plus chers, et El Farolito ajoute 2 $ à leur commande quel que soit le nombre de burritos. Avant de recalculer quelque chose, regardons le graphique:
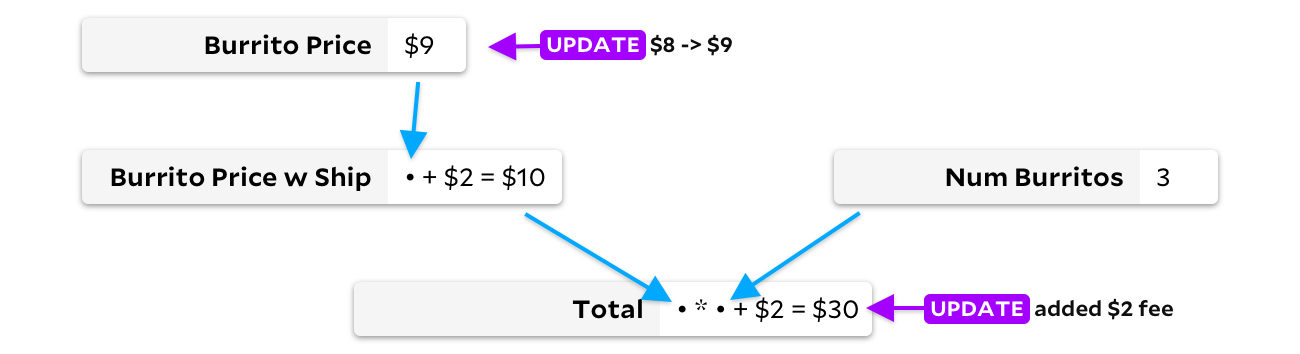
Puisqu'il y a deux cellules mises à jour ici, nous avons un problème. Devez-vous recalculer d'abord le prix d'un burrito ou le total? Idéalement, nous calculons d'abord le prix du burrito, notons le changement, puis recalculons le prix du burrito de livraison, et enfin recalculons le total. Cependant, si nous recalculons d'abord le total, nous devrons le recalculer une deuxième fois une fois que le nouveau prix du burrito à 9 $ se propage dans les cellules. Si nous ne calculons pas les cellules dans le bon ordre, cet algorithme ne vaut pas mieux que recalculer l'ensemble du document. Aussi lent que VisiCalc dans certains cas!
De toute évidence, il est important pour nous de déterminer le bon ordre de mise à jour des cellules. En général, il existe deux solutions à ce problème: le marquage sale et le tri topologique.
La première solution consiste à étiqueter toutes les cellules en aval de la cellule mise à jour. Ils sont marqués comme sales. Par exemple, lorsque nous mettons à jour le prix d'un burrito, nous marquons les cellules en aval
Burrito Price w Ship
et
Total
, avant de faire tout recalcul:
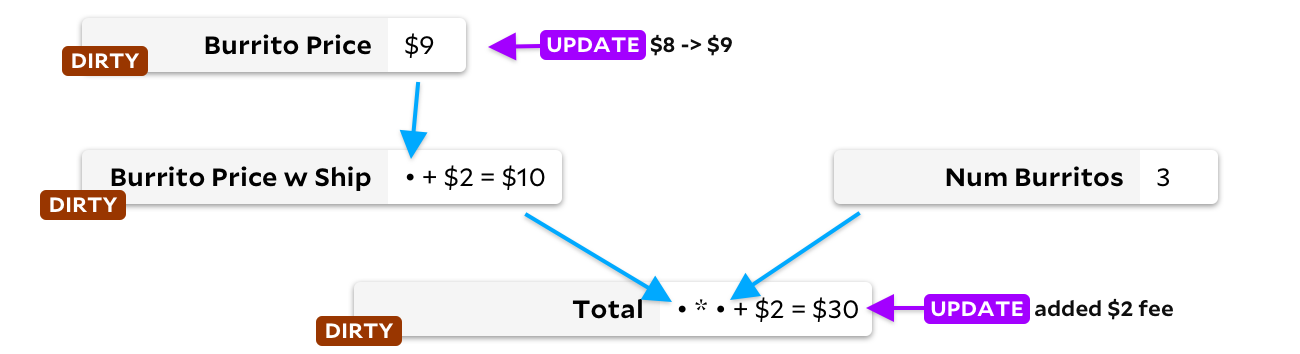
Ensuite, dans une boucle, nous trouvons une cellule sale sans entrées sales - et la recalculons. Quand il n'y a plus de cellules sales, c'est fini! Cela résout notre problème de dépendance. Cependant, il y a un inconvénient - si la cellule est recalculée et que nous constatons que le nouveau résultat est le même que le précédent, nous recalculerons toujours les cellules subordonnées! Un peu de logique supplémentaire aidera à éviter le problème, mais malheureusement, nous passons encore du temps à marquer les cellules et à supprimer les marques.
La deuxième solution est le tri topologique. Si une cellule n'a pas d'entrée, nous marquons sa hauteur comme 0. Si c'est le cas, nous marquons la hauteur comme le maximum des cellules d'entrée plus un. Cela garantit que chaque cellule a une valeur de hauteur plus grande que n'importe laquelle des cellules entrantes, donc nous gardons simplement une trace de toutes les cellules avec l'entrée modifiée, en choisissant toujours la cellule avec la hauteur la plus basse pour recalculer en premier:
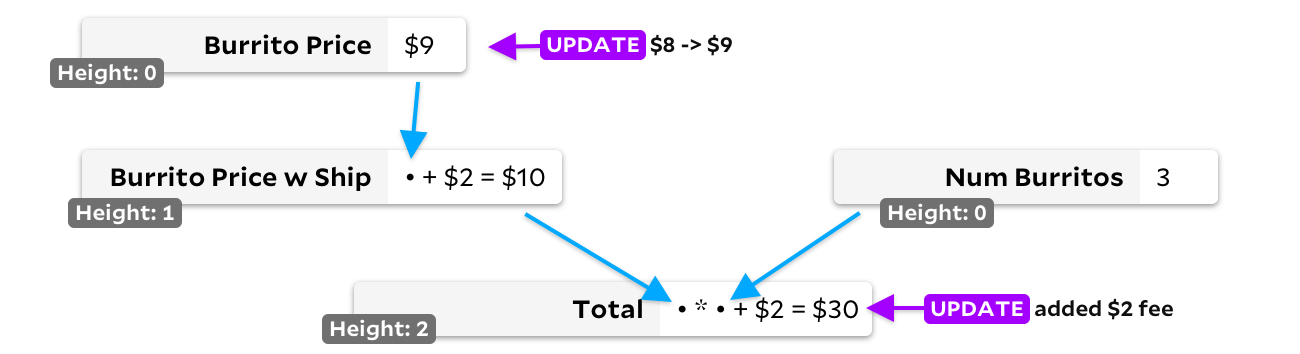
Dans notre exemple de double mise à jour, le prix du burrito et le montant total sera initialement ajouté au tas de conversion. Le prix du burrito est inférieur et sera recalculé en premier. Comme son résultat a changé, nous ajouterons alors le prix du burrito de livraison au tas de recalcul, et comme il a également une hauteur plus courte que
Total
puis il sera recalculé avant que nous ne racontions enfin
Total
.
C'est bien mieux que la première solution: aucune cellule n'est marquée comme sale à moins qu'une des cellules entrantes ne change vraiment. Cependant, cela nécessite que les cellules soient conservées dans un ordre trié en attendant le recalcul. Lorsqu'il est utilisé sur le tas, cela conduit à un ralentissement
O(n log n)
, qui est asymptotiquement plus lent dans le pire des cas que la stratégie recalculée Lotus 1-2-3.
Modern Excel utilise une combinaison de contamination et de tri topologique , consultez leur documentation pour plus de détails.
Évaluation paresseuse
Nous avons maintenant plus ou moins réalisé les algorithmes de recalcul dans les feuilles de calcul modernes. Je soupçonne qu'en principe, il n'y a aucune justification commerciale pour de nouvelles améliorations, malheureusement. Les gens ont déjà écrit suffisamment de formules Excel pour rendre impossible la migration vers une autre plate-forme. Heureusement, je ne suis pas un spécialiste des affaires, nous envisagerons donc d’autres améliorations de toute façon.
Outre la mise en cache, l'un des aspects intéressants d'un graphe de calcul de type feuille de calcul est que nous ne pouvons calculer que les cellules qui nous intéressent. Ceci est parfois appelé évaluation paresseuse ou calcul basé sur la demande. À titre d'exemple plus spécifique, voici un graphique de feuille de calcul de burrito légèrement développé. L'exemple est le même que précédemment, mais nous avons ajouté ce qui est mieux décrit comme «calcul de salsa». Chaque burrito contient 40 grammes de salsa et nous faisons une multiplication rapide pour savoir combien il y a de salsa dans toute la commande. Puisque nous avons trois burritos dans notre commande, il y aura un total de 120 grammes de salsa.

Bien sûr, les lecteurs avertis ont déjà remarqué le problème: le poids total de la salsa dans une commande est une métrique assez inutile. Qui se soucie si c'est 120 grammes? Que dois-je faire avec ces informations? Malheureusement, une feuille de calcul typique passera des cycles sur les calculs de salsa, même si nous n'avons pas besoin de ces calculs la plupart du temps.
C'est là que le recalcul paresseux peut aider. Si nous indiquons d'une manière ou d'une autre que nous ne sommes intéressés que par le résultat
Total
, nous pourrions recalculer cette cellule, ses dépendances et ne pas toucher à la salsa. Appelons cela une cellule
Total
observée lorsque nous essayons de regarder son résultat. Nous pouvons également appeler
Total
trois de ses dépendances nécessaires.cellules, car elles sont nécessaires pour calculer une cellule observée.
Salsa In Order
et
Salsa Per Burrito
appelez cela inutile .
Pour résoudre ce problème, certains des coéquipiers de Rust ont créé le framework Salsa , en le nommant explicitement d'après le calcul de salsa inutile qui a gaspillé leurs cycles informatiques. Ils peuvent sûrement mieux expliquer que moi comment cela fonctionne. Très grosso modo, le framework utilise des numéros de révision pour savoir si une cellule doit être recalculée. Toute mutation dans une formule ou une entrée augmente le numéro de révision global, et chaque cellule suit deux révisions:
verified_at
pour la révision dont le résultat a été mis à jour et
changed_at
pour la révision dont le résultat a effectivement été modifié.
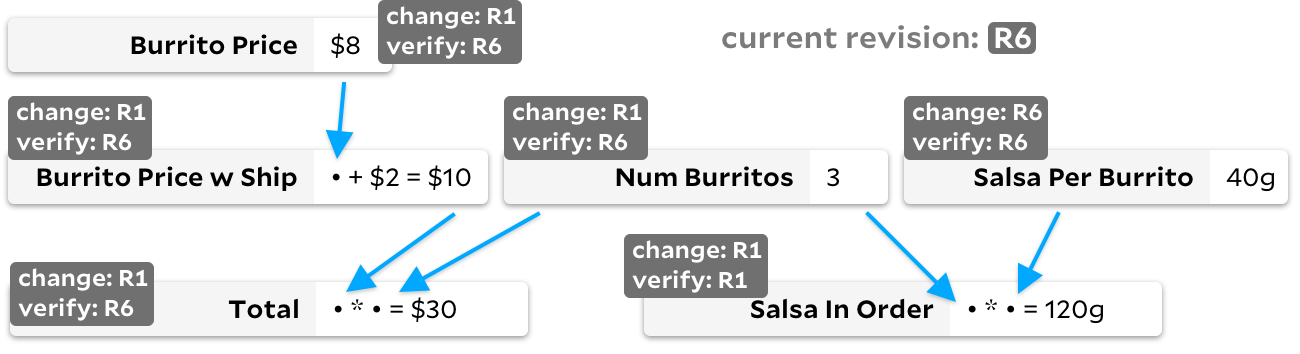
Lorsque l'utilisateur indique qu'il a besoin d'une nouvelle valeur
Total
, nous recalculons d'abord récursivement toutes les cellules nécessaires pour
Total
, en ignorant les cellules où la révision
last_updated
est égale à la révision globale. Une fois les dépendances
Total
mises à jour, nous réexécutons la formule réelle
Total
uniquement si Burrito Price w Ship ou a une
Num Burrito
révision
changed_at
supérieure à la révision vérifiée
Total
... C'est parfait pour Salsa dans l'analyseur de rouille, où la simplicité est importante et où chaque cellule prend du temps à calculer. Cependant, dans le graphique avec le burrito ci-dessus, vous pouvez remarquer les inconvénients - s'il
Salsa Per Burrito
change constamment, notre numéro de révision global augmentera souvent. En conséquence, chaque observation
Total
nécessiterait de parcourir trois cellules, même si aucune d'entre elles n'a changé. Aucune formule ne sera recalculée, mais si le graphique est volumineux, l'itération de toutes les dépendances de cellule peut être coûteuse.
Options plus rapides pour une évaluation paresseuse
Au lieu d'inventer de nouveaux algorithmes paresseux, essayons les deux algorithmes classiques de tableur mentionnés précédemment: l'étiquetage et le tri topologique. Comme vous pouvez l'imaginer, le modèle paresseux complique ces deux tâches, mais les deux sont toujours viables.
Regardons d'abord les marques. Comme précédemment, lorsque nous modifions la formule d'une cellule, nous marquons toutes les cellules en aval comme sales. Ainsi, lors de la mise à jour,
Salsa Per Burrito
cela ressemblera à quelque chose comme ceci:

mais au lieu de recalculer immédiatement toutes les cellules sales, nous attendons que l'utilisateur observe la cellule. Ensuite, nous exécutons l'algorithme Salsa dessus, mais au lieu de revérifier les dépendances avec des numéros de version obsolètes
verified_at
, nous ne revérifions que les cellules marquées comme sales. Adapton utilise cette technique . Dans une telle situation, l'observation de la cellule
Total
révèle qu'elle n'est pas sale, et donc on peut sauter le passage du graphe que Salsa aurait effectué!
Si vous l'observez
Salsa In Order
, alors il est marqué comme sale, et par conséquent, nous allons revérifier et recalculer et
Salsa Per Burrito
, et
Salsa In Order
. Même ici, il y a des avantages à utiliser uniquement des numéros de révision, car nous pouvons passer récursivement à travers une cellule encore vide
Num Burritos
.
L'étiquetage sale paresseux fonctionne de manière fantastique pour changer fréquemment l'ensemble de cellules que nous essayons d'observer. Malheureusement, il présente les mêmes inconvénients que l'algorithme de marquage sale précédent. Si une cellule avec de nombreuses cellules en aval change, alors nous passons beaucoup de temps à marquer les cellules et à décocher, même si l'entrée ne change pas réellement lorsque nous procédons au recalcul. Dans le pire des cas, chaque changement conduit au fait que nous marquons le graphe entier comme sale, ce qui nous donne à peu près le même ordre de performance que l'algorithme Salsa.
En plus d'un étiquetage désordonné, nous pouvons également adapter le tri topologique pour une évaluation paresseuse. Cette méthode utilise la bibliothèque incrémentiellede Jane Street, et il faut quelques astuces sérieuses pour le faire fonctionner correctement. Avant d'implémenter l'évaluation paresseuse, notre algorithme de tri topologique a utilisé un tas pour déterminer la cellule à recalculer ensuite. Mais maintenant, nous voulons recalculer uniquement les cellules nécessaires. Comment? Nous ne voulons pas parcourir l'arbre entier à partir des cellules observées comme Adapton, car une promenade complète à travers l'arbre détruit tout le but du tri topologique et nous donne des caractéristiques de performance similaires à Adapton.
Au lieu de cela, Incremental gère un ensemble de cellules que l'utilisateur a marqué comme surveillé, ainsi que l'ensemble de cellules requis pour toute cellule surveillée. Chaque fois qu'une cellule est marquée comme observable ou non observable, Incremental parcourt les dépendances de cette cellule pour s'assurer que les étiquettes requises sont appliquées correctement. Ensuite, nous ajoutons des cellules au tas de recalcul uniquement si elles sont marquées comme nécessaires. Dans notre graphe burrito, tant qu'il
Total
fait partie d'un ensemble observable, le changement
Salsa in Order
n'entraînera aucun passage dans le graphe, puisque seules les cellules nécessaires sont recalculées:

cela résout notre problème sans ardemment parcourir le graphe pour marquer les cellules comme sales! Nous devons encore nous rappeler que la cellule
Salsa per Burrito
est compliqué de raconter plus tard si nécessaire. Mais contrairement à l'algorithme d'Adapton, nous n'avons pas besoin de pousser cette seule étiquette sale sur tout le graphique.
Anchors, une solution hybride
Adapton et Incremental parcourent le graphique même s'ils ne recalculent pas les cellules. Incrémental parcourt le graphique lorsque l'ensemble de cellules observées change et Adapton parcourt le graphique lorsque la formule change. Avec de petits graphiques, le coût élevé de ces passes peut ne pas être immédiatement apparent. Mais si le graphique est volumineux et que les cellules sont relativement peu coûteuses à calculer - c'est souvent le cas avec les feuilles de calcul - vous constaterez que la majeure partie du calcul est gaspillée en marchant inutilement autour du graphique! Lorsque les cellules sont bon marché, marquer un peu sur une cellule peut coûter à peu près le même prix que simplement recalculer une cellule à partir de zéro. Par conséquent, idéalement, si nous voulons que notre algorithme soit beaucoup plus rapide qu'un simple calcul, nous devrions éviter autant que possible de marcher inutilement autour du graphique.
Plus je réfléchissais à ce problème, plus je me rendais compte qu'ils perdaient du temps à parcourir le graphique dans des situations à peu près opposées. Dans notre graphe burrito, imaginons que les formules des cellules changent rarement, mais que nous basculons rapidement, en observant d'abord
Total
et ensuite
Salsa in Order
.
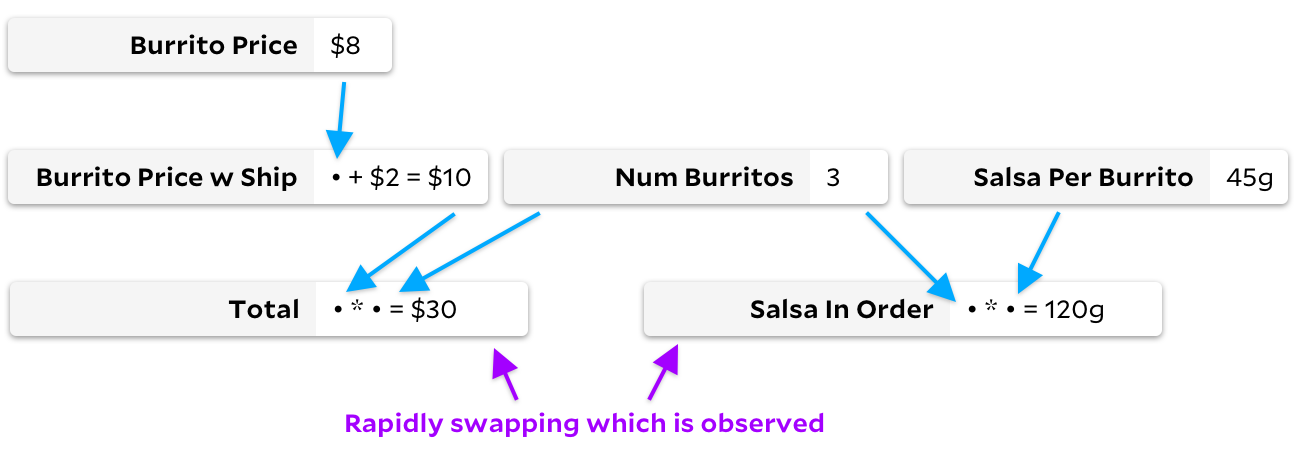
Dans ce cas, Adapton ne marchera pas dans l'arbre. Aucune des données d'entrée ne change et nous n'avons donc pas besoin de marquer de cellule. Puisque rien n'est marqué, chaque observation est bon marché car nous pouvons simplement renvoyer immédiatement la valeur mise en cache à partir d'une cellule vide. Cependant, Incremental ne fonctionne pas bien dans cet exemple. Bien qu'aucune valeur ne soit recalculée, Incremental marquera et décochera à plusieurs reprises de nombreuses cellules si nécessaire ou inutile.
Sinon, imaginons un graphique où nos formules changent rapidement, mais nous ne changeons pas la liste des cellules observées. Par exemple, nous pourrions nous imaginer observer
Total
en changeant rapidement le prix d'un burrito de
4+4
à
2*4
.
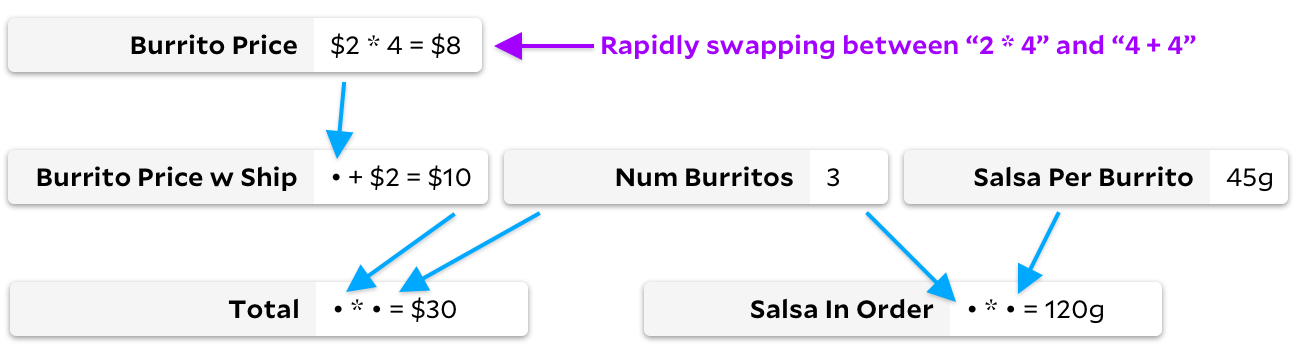
Comme dans l'exemple précédent, nous ne recalculons pas réellement de nombreuses cellules:
4+4
et
2*4
égal
8
, donc idéalement, nous ne recalculons cette arithmétique que lorsque l'utilisateur effectue ce changement. Mais contrairement à l'exemple précédent, Incremental évite désormais de marcher dans les arbres. Avec Incremental, nous avons mis en cache le fait que le prix du burrito est une cellule nécessaire, donc quand il change, nous pouvons le recalculer sans passer par le graphique. Avec Adapton, nous perdons du temps à marquer
Burrito Price w Ship
et à
Total
quel point il est compliqué, même si le résultat
Burrito Price
ne change pas.
Étant donné que chaque algorithme fonctionne bien dans les cas dégénérés de l'autre, pourquoi ne pas idéalement détecter ces cas dégénérés et passer à un algorithme plus rapide? C'est ce que j'ai essayé d'implémenter dans ma propre bibliothèque Ancres . Il exécute les deux algorithmes simultanément sur le même graphe! Si cela semble fou, inutile et trop compliqué, c'est probablement parce que c'est le cas.
Dans de nombreux cas, les ancres suivent exactement l'algorithme incrémental, évitant ainsi le cas dégénéré d'Adapton ci-dessus. Mais lorsque les cellules sont marquées comme non observables, leur comportement diverge légèrement. Voyons ce qui se passe. Commençons par la marquer
Total
comme une cellule observée:
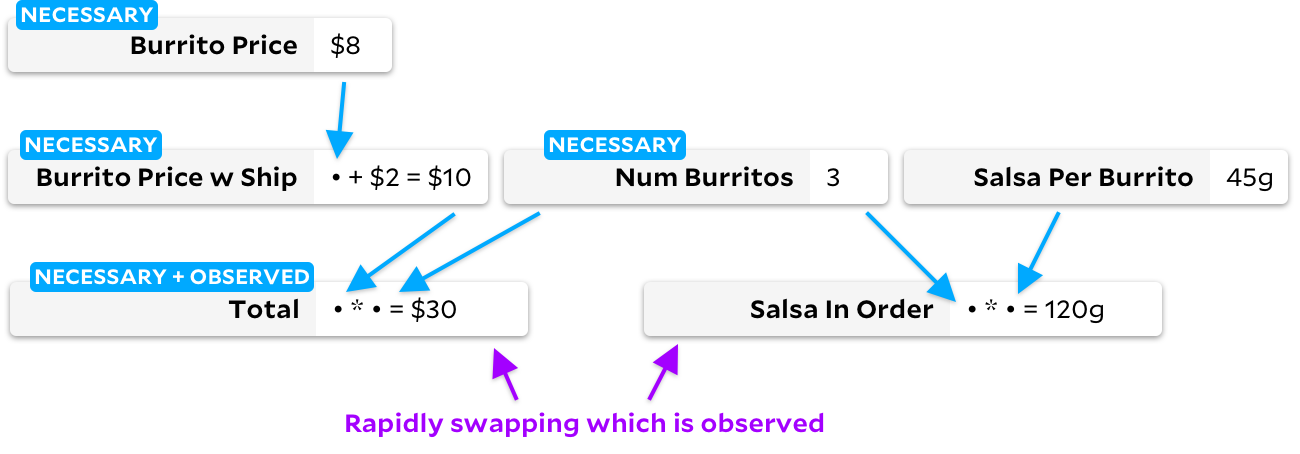
si vous la marquez ensuite
Total
comme une cellule non observable, et
Salsa in Order
comme observable, l'algorithme incrémental traditionnel changera le graphique, en passant par toutes les cellules du processus: Les
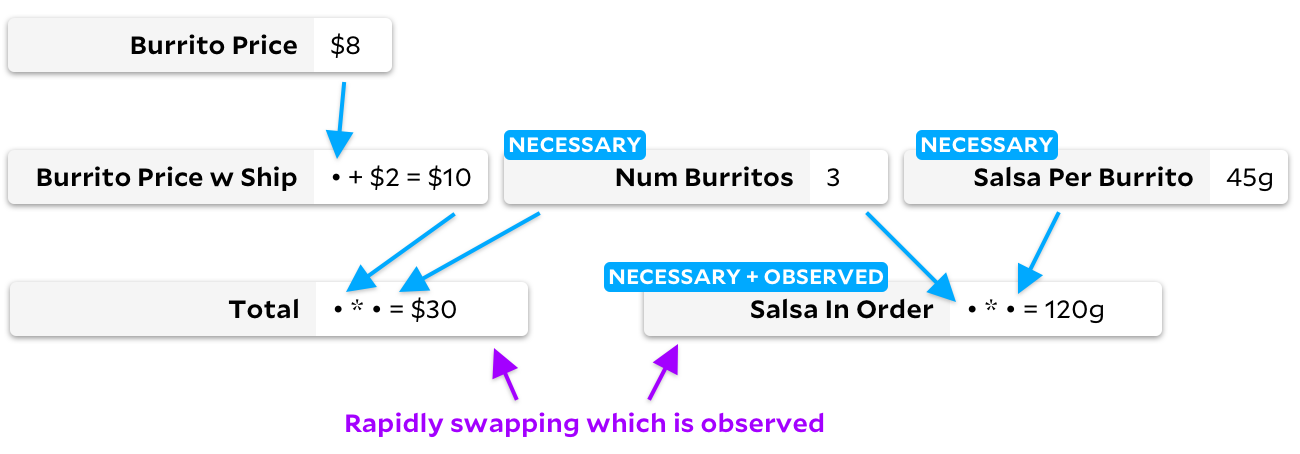
ancres pour ce changement contourne également toutes les cellules, mais crée un autre graphique:
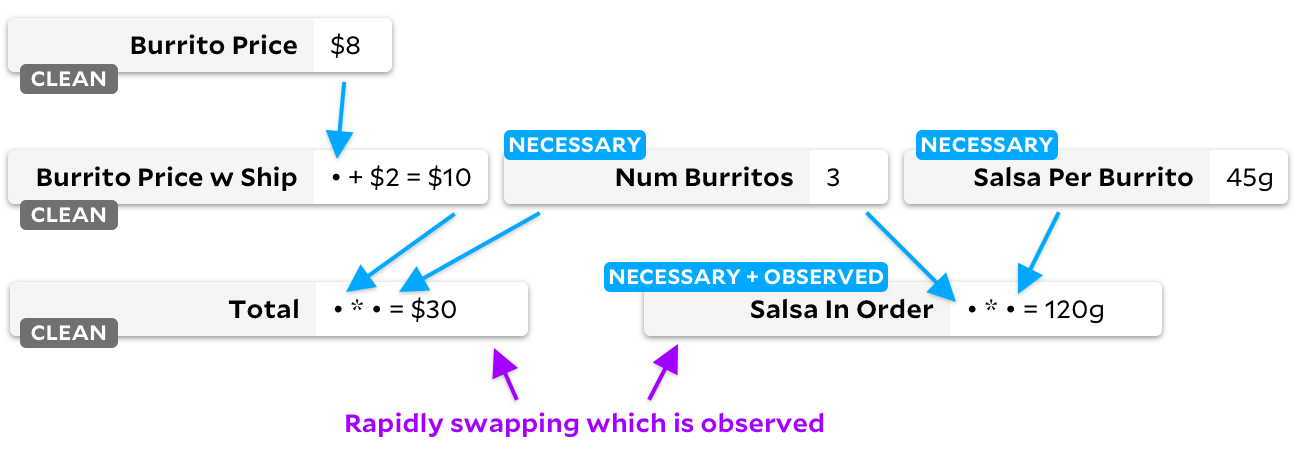
Faites attention aux drapeaux des cellules "propres"! Lorsqu'une cellule n'est plus nécessaire, nous la marquons comme vide. Voyons ce qui se passe lorsque nous passons de l'observation
Salsa in Order
à
Total
:
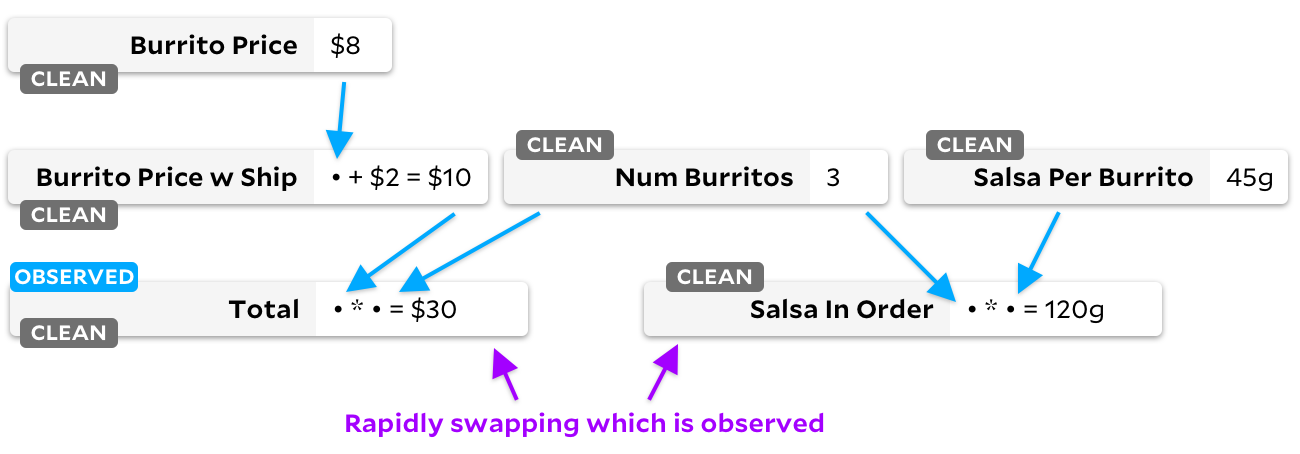
Droite - notre graphe n'a plus de cellules "nécessaires". Si une cellule a un drapeau "propre", nous ne la marquons jamais comme observable. À partir de maintenant, quelle que soit la cellule que nous marquons comme observée ou non observée, Anchors ne perdra jamais de temps à parcourir le graphique - elle sait qu'aucune des entrées n'a changé.
On dirait qu'El Farolito a annoncé une réduction! Réduisons le prix du burrito d'un dollar. Comment Anchors sait-il qu'il faut recalculer le montant? Avant tout recalcul, voyons comment Anchors voit le graphique immédiatement après les changements de prix du burrito:

si la cellule a un indicateur clair, nous exécutons l'algorithme traditionnel d'Adapton dessus, marquant volontiers les cellules en aval comme sales. Lorsque nous exécutons plus tard l'algorithme incrémental, nous pouvons rapidement dire qu'il existe une cellule observable marquée comme sale, et nous savons que nous devons recalculer ses dépendances. Le graphique final ressemblera à ceci:
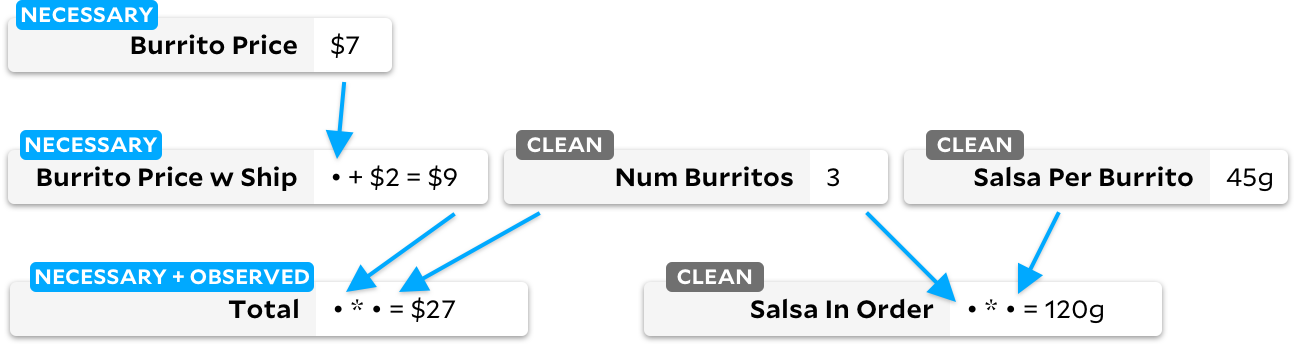
Nous ne recalculons les cellules que lorsque cela est nécessaire, donc chaque fois que nous recalculons une cellule sale, nous la marquons également comme nécessaire. À un niveau élevé, vous pouvez considérer ces trois états de cellules comme une machine à états cyclique:

Sur les cellules requises, exécutez l'algorithme de tri topologique incrémental. Sur le reste, nous exécutons l'algorithme Adapton.
Syntaxe du burrito
En conclusion, je voudrais répondre à la dernière question: jusqu'à présent, nous avons discuté de nombreux problèmes qu'un modèle paresseux pose pour notre stratégie de recalcul de table. Mais les problèmes ne sont pas seulement dans l'algorithme: il y a aussi des problèmes syntaxiques. Par exemple, préparons un tableau pour sélectionner un burrito emoji pour notre client. Nous aimerions écrire une déclaration
IF
dans un tableau comme celui-ci:

puisque les feuilles de calcul traditionnelles ne sont pas paresseuses, nous pouvons calculer
B1
,
B2
et
B3
dans n'importe quel ordre, puis calculer la cellule
IF
... Cependant, dans un monde paresseux, si nous pouvons d'abord calculer la valeur de B1, nous pouvons regarder le résultat pour savoir quelle valeur doit être recalculée - B2 ou B3. Malheureusement, les feuilles de calcul traditionnelles
IF
ne peuvent pas exprimer cela!
Problème:
B2
référence simultanément une cellule
B2
et récupère sa valeur. La plupart des bibliothèques paresseuses mentionnées dans l'article font plutôt une distinction explicite entre une référence à une cellule et le fait de récupérer sa valeur réelle. Dans Anchors, nous appelons cette ancre de référence de cellule. Tout comme dans la vraie vie, un burrito enveloppe un tas d'ingrédients, un type
Anchor<T>
s'enroule
T
. Donc je suppose que notre cellule de burrito végétalienne devient
Anchor<Burrito>
, une sorte de ridicule burrito burrito. Les fonctions peuvent transférer les nôtres
Anchor<Burrito>
autant qu'elles le souhaitent. Mais lorsqu'ils déballent réellement le burrito pour accéder à l'
Burrito
intérieur, nous créons un bord de dépendance dans notre graphique, indiquant à l'algorithme de recalcul que la cellule peut être nécessaire et doit être recalculée.
L'approche adoptée par Salsa et Adapton consiste à utiliser des appels de fonction et un flux de contrôle normal comme moyen d'élargir ces valeurs. Par exemple, dans Adapton, nous pourrions écrire la cellule Burrito for Customer quelque chose comme ceci:
let burrito_for_customer = cell!({
if get!(is_vegetarian) {
get!(vegi_burrito)
} else {
get!(meat_burrito)
}
});
En faisant la distinction entre une référence de cellule (ici
vegi_burrito
) et le fait d'étendre sa valeur (
get!
), Adapton peut s'exécuter au-dessus des instructions de flux de contrôle Rust telles que
if
. C'est une excellente solution! Cependant, il faut un peu d'état global magique pour câbler correctement les appels
get!
aux cellules
cell!
lors d'un changement
is_vegetarian
. La bibliothèque d'ancres d'influence incrémentale adopte une approche moins magique. Comme async-pre / await
Future
, Anchors permet de lancer des
Anchor<T>
opérations telles que
map
et
then
. Ainsi, l'exemple ci-dessus ressemblerait à ceci:
let burrito_for_customer: Anchor<Burrito> = is_vegetarian.then(|is_vegetarian: bool| -> Anchor<Burrito> {
if is_vegetarian {
vegi_burrito
} else {
meat_burrito
}
});
Lectures complémentaires
Dans cet article déjà long et fleuri, il n'y avait pas assez de place pour autant de sujets. Espérons que ces ressources pourront éclairer un peu plus ce problème très intéressant.
- Sept implémentations d'Incremental , un excellent regard en profondeur sur les éléments internes de l'Incremental, ainsi qu'un tas d'optimisations telles que des hauteurs en constante augmentation dont je n'ai pas eu le temps de parler, ainsi que des moyens intelligents de gérer les cellules qui changent de dépendance. À lire également par Ron Minsky: Analyse FRP .
- Vidéo expliquant le fonctionnement de la Salsa.
- Il s'agit d' un ticket Salsa où Matthew Hammer, créateur d'Adapton, explique patiemment les seuils à un passant au hasard (moi) qui n'a aucune idée de leur fonctionnement.
- Rustlab . , « » «: DX CS» — .
- , « », Materialize. , . , (!) « », , . Noira .
- Adapton .
- Il s'avère que cette façon de penser s'applique également à la construction de systèmes . Il s'agit de l'un des premiers articles scientifiques sur les similitudes entre les systèmes de construction et les feuilles de calcul.
- Le lancer de rayons légèrement incrémental est un traceur de rayons légèrement incrémental écrit en Ocaml.
- Je viens de regarder "État partiel dans les vues matérialisées basées sur le flux de données" et cela semble pertinent.
- Skip et Imp semblent également très intéressants.
Et bien sûr, vous pouvez toujours consulter mon framework Anchors .