L'utilisation de l'addition au lieu de la multiplication pour la convolution entraîne moins de latence que CNN standard


AdderNet: ?, (AdderNet), , Huawei Noah's Ark Lab .
?
AdderNet
: BN, ,
1. AdderNet
1.1.
, Y :
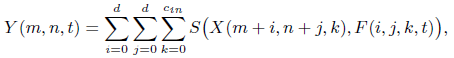
S - .
1.2.

, . .
1.3. AdderNet

, l1- :

l1- .
, .
, , - , .
2. : BN, ,
2.1. (Batch Normalization - BN)
, (BN) Y , , CNN, AdderNets.
BN , , , .
( - BN, ?)
2.2.
l1- . , l2-:

.
, X [-1,1].
Y X :

HT - HardTanh:
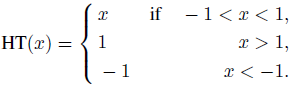
2.3.

, AdderNets , CNN, AdderNets.
AdderNets :
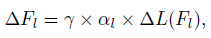
γ - (, BN ), ΔL(Fl) - l, αl - .
,

k Fl, η - .
3.
3.1. MNIST
CNN 99,4% 435K 435K .
, AdderNet 99,4%, CNN, 870K .
, .
, VIA Nano 2000 4 2 . AdderNet LeNet-5 1.7M, CNN 2.6M CPU.
3.2. CIFAR


(Binary neural networks - BNN): XNOR , .
VGG-small, AdderNets (93,72% CIFAR-10 72,64% CIFAR-100) CNNs (93,80% CIFAR-10 72,73% CIFAR-100).
BNN , AdderNet CNN, (89,80% CIFAR-10 65,41% CIFAR-100).
ResNet-20, CNN (.. 92,25% CIFAR-10 68,14% CIFAR-100), (41,17M).
AdderNets 91,84% CIFAR-10 67,60% CIFAR-100 , CNN.
, BNN 84,87% 54,14% CIFAR-10 CIFAR-100.
ResNet-32 , AdderNets CNN.
3.3. ImageNet

CNN 69,8% top-1 89,1% top-5 RESNET-18. , 1.8G .
AdderNet 66,8% top-1 87,4% top-5 ResNet-18, , .
, BNN , 51,2% top-1 73,2% top-5 ResNet-18.
ResNet-50.
3.4.

LeNet++ MNIST, 3D .
32, 32, 64, 64, 128, 128 2 .
AdderNets l1- . .
, AdderNets CNN.

adderNets - .
, AdderNets .
 et CNN (à droite).")
AdderNets , CNN . , l1- .
3.5.

AdderNets, (adaptive learning rate - ALR) (increased learning rate - ILR), 97,99% 97,72% , , CNN (99,40%) .
AdderNets.
AdderNet ILR 98,99% . (ALR), AdderNet 99,40%, .
[2020 CVPR] [AdderNet]
AdderNet: Do We Really Need Multiplications in Deep Learning?
1989–1998: [LeNet]
2012–2014: [AlexNet & CaffeNet] [Dropout] [Maxout] [NIN] [ZFNet] [SPPNet] [Distillation]
2015: [VGGNet] [Highway] [PReLU-Net] [STN] [DeepImage] [GoogLeNet / Inception-v1] [BN-Inception / Inception-v2]
2016: [SqueezeNet] [Inception-v3] [ResNet] [Pre-Activation ResNet] [RiR] [Stochastic Depth] [WRN] [Trimps-Soushen]
2017: [Inception-v4] [Xception] [MobileNetV1] [Shake-Shake] [Cutout] [FractalNet] [PolyNet] [ResNeXt] [DenseNet] [PyramidNet] [DRN] [DPN] [Residual Attention Network] [IGCNet / IGCV1] [Deep Roots]
2018: [RoR] [DMRNet / DFN-MR] [MSDNet] [ShuffleNet V1] [SENet] [NASNet] [MobileNetV2] [CondenseNet] [IGCV2] [IGCV3] [FishNet] [SqueezeNext] [ENAS] [PNASNet] [ShuffleNet V2] [BAM] [CBAM] [MorphNet] [NetAdapt] [mixup] [DropBlock] [Group Norm (GN)]
2019: [ResNet-38] [AmoebaNet] [ESPNetv2] [MnasNet] [Single-Path NAS] [DARTS] [ProxylessNAS] [MobileNetV3] [FBNet] [ShakeDrop] [CutMix] [MixConv] [EfficientNet] [ABN] [SKNet] [CB Loss]
2020: [Random Erasing (RE)] [SAOL] [AdderNet]
- : "Knowledge distillation: ".
- -