
Chez Playrix, une quantité importante de ressources est allouée à la préparation et à l'analyse des données, nous essayons d'utiliser des technologies de pointe et prenons la formation des employés au sérieux. La société est l'un des 3 premiers développeurs de jeux mobiles au monde, nous essayons donc de maintenir le niveau approprié dans l'analyse des données et plus particulièrement dans la Business Intelligence. Plus de 27 millions d'utilisateurs jouent à nos jeux chaque jour, et ce chiffre peut donner une idée approximative de la quantité de données générées chaque jour par les appareils mobiles. De plus, les données sont extraites de dizaines de services dans différents formats, après quoi elles sont agrégées et chargées dans nos stockages. Nous travaillons avec AWS S3 en tant que Data Lake, tandis que Data Warehouse sur AWS Redshift et PostgreSQL a une utilisation limitée. Nous utilisons ces bases de données à des fins d'analyse. Redshift est plus rapide mais plus cherc'est pourquoi nous y stockons les données les plus demandées. PostgreSQL est moins cher et plus lent, il stocke soit de petites quantités de données, soit des données dont la vitesse de lecture n'est pas critique. Pour les données pré-agrégées, nous utilisons le cluster Hadoop et Impala.
Le principal outil BI de Playrix est Tableau. Ce produit est bien connu dans le monde, il offre de nombreuses possibilités d'analyse et de visualisation de données, fonctionne avec diverses sources. De plus, vous n'avez pas à écrire de code pour des tâches d'analyse simples, vous pouvez donc former les utilisateurs de différents services à analyser eux-mêmes leurs données commerciales. Le fournisseur de l'outil Tableau Software positionne également son produit comme un outil d'auto-analyse des données, c'est-à-dire en libre-service.
Il existe deux approches principales de l'analyse des données en BI:
- Reporting Factory . Cette approche a un département et / ou des personnes développant des rapports pour les utilisateurs métier.
- Self-Service. - .
La première approche est traditionnelle, et la plupart des entreprises ont une usine de reporting à l'échelle de l'entreprise comme celle-ci. La deuxième approche est relativement nouvelle, en particulier pour la Russie. C'est bien parce que les données sont recherchées par les utilisateurs professionnels eux-mêmes - ils connaissent beaucoup mieux leurs processus locaux. Cela aide à décharger les développeurs, les évite de se plonger dans les spécificités des processus d'équipe et de créer à chaque fois les rapports les plus basiques. Cela aide à résoudre ce qui est probablement le plus gros problème - combler le fossé entre les utilisateurs professionnels et les développeurs. Après tout, le principal problème de l'approche Reporting Factory est précisément que la plupart des rapports peuvent rester non réclamés uniquement du fait que les programmeurs-développeurs comprennent mal les problèmes des utilisateurs professionnels et, par conséquent, créent des rapports inutiles.qui sont soit retravaillés plus tard, soit simplement non utilisés.
Chez Playrix, les programmeurs et les analystes ont été initialement impliqués dans le développement de rapports dans l'entreprise, c'est-à-dire des spécialistes qui travaillent quotidiennement avec des données. Mais l'entreprise se développe très rapidement, et à mesure que les besoins des utilisateurs en rapports augmentent, les développeurs de rapports ont cessé d'être à temps pour résoudre toutes les tâches de leur création et de leur support. Ensuite, la question s'est posée soit d'élargir le groupe de développement BI, soit de transférer des compétences vers d'autres départements. La direction du Self Service nous paraissait prometteuse, nous avons donc décidé d'apprendre aux utilisateurs métier à créer leurs propres projets et à analyser eux-mêmes les données.
Dans Playrix, la division Business Intelligence (BI Team) travaille sur les tâches suivantes:
- Collecte, préparation et stockage des données.
- Développement de services d'analyse interne.
- Intégration avec des services externes.
- Développement d'interfaces web.
- Développement de rapports dans Tableau.
Nous sommes engagés dans l'automatisation des processus internes et des analyses. De manière simplifiée, notre structure peut être représentée à l'aide du diagramme:

Mini-équipes BI Team Les
rectangles ici représentent des mini-équipes. Sur les équipes arrière gauche, sur les équipes avant droit. Chacun d'eux possède des compétences suffisantes pour travailler avec les tâches des équipes liées et les assumer lorsque les autres équipes sont surchargées.
L'équipe BI a un cycle de développement complet: de la collecte des exigences au déploiement sur un environnement de produit et au support ultérieur. Chaque mini-équipe dispose de son propre analyste système, de ses développeurs et de ses ingénieurs de test. Ils servent de Reporting Factory , préparant des données et des rapports à usage interne.
Il est important de noter ici que dans la plupart des projets Tableau, nous ne développons pas de simples rapports, qui sont généralement présentés dans des démos, mais des outils avec des fonctionnalités riches, un grand ensemble de contrôles, des capacités étendues et une connexion de modules externes. Ces outils sont constamment révisés, de nouvelles fonctionnalités sont ajoutées.
Cependant, de simples problèmes locaux surviennent également, qui peuvent être résolus par le client lui-même.
Transfert de compétences et lancement d'un projet pilote
D'après notre expérience de travail et de communication avec d'autres entreprises, les principaux problèmes lors du transfert de compétences en données aux utilisateurs métier sont:
- La réticence des utilisateurs eux-mêmes à apprendre de nouveaux outils et à travailler avec des données.
- Manque de soutien de la direction (investissement en formation, licences, etc.).
Nous avons un soutien colossal de la direction, de plus, la direction a proposé d'introduire le libre-service. Les utilisateurs souhaitent également apprendre à travailler avec les données et Tableau - c'est intéressant pour les gars, et l'analyse des données est maintenant une compétence très importante qui sera certainement utile à l'avenir.
La mise en œuvre d'une nouvelle idéologie dans toute l'entreprise nécessite généralement beaucoup de ressources et de nerfs, nous avons donc commencé avec un pilote. Le projet pilote de libre-service a été lancé dans le département d'acquisition d'utilisateurs il y a un an et demi, et au cours du processus pilote, des erreurs et de l'expérience ont été accumulées pour les transmettre à d'autres départements à l'avenir.
La direction Acquisition d'utilisateurs travaille sur les tâches d'augmenter l'audience de nos produits, analyse les modes d'achat de trafic et choisit dans quelles directions pour attirer les utilisateurs il vaut la peine d'investir les fonds de l'entreprise. Auparavant, pour cette direction, les rapports étaient préparés par l'équipe BI, ou les gars eux-mêmes traitaient les téléchargements de la base de données à l'aide d'Excel ou de Google Sheets. Mais dans un environnement de développement dynamique, une telle analyse entraîne des retards et le nombre de données analysées est limité par les capacités de ces outils.
Au début du pilote, nous avons organisé une formation de base pour que les employés travaillent avec Tableau, créé la première source de données commune - une table dans la base de données Redshift, dans laquelle il y avait plus de 500 millions de lignes et les métriques nécessaires. Il convient de noter que Redshift est une base de données en colonnes (ou en colonnes), et cette base de données sert les données beaucoup plus rapidement que les bases de données relationnelles. La table pilote dans Redshift était vraiment grande pour les personnes qui n'ont jamais travaillé avec plus d'un million de lignes en même temps. Mais c'était un défi pour les gars d'apprendre à travailler avec des données de tels volumes.
Nous savions que les problèmes de performances commenceraient à mesure que ces rapports deviendraient plus complexes. Nous n'avons pas donné aux utilisateurs l'accès à la base de données elle-même, mais une source a été implémentée sur le serveur Tableau, connecté en mode direct à une table dans Redshift. Les utilisateurs disposaient de licences Creator et pouvaient se connecter à cette source soit à partir du serveur Tableau, y développant des rapports, soit à partir de Tableau Desktop. Je dois dire que lors du développement de rapports sur le Web (Tableau a un mode d'édition Web), il existe certaines limitations sur le serveur. Tableau Desktop n'a pas de telles restrictions, nous développons donc principalement sur le bureau. De plus, si un seul utilisateur métier a besoin d'une analyse, il n'est pas nécessaire de publier de tels projets sur le serveur - vous pouvez travailler localement.
Formation
Dans notre entreprise, il est d'usage de mener des webinaires et un partage de connaissances, dans lesquels chaque employé peut parler des nouveaux produits, fonctionnalités ou capacités des outils avec lesquels il travaille ou qu'il recherche. Toutes ces activités sont enregistrées et stockées dans notre base de connaissances. Ce processus fonctionne également dans notre équipe, nous partageons donc périodiquement des connaissances ou préparons des webinaires de formation fondamentale.
Pour tous les utilisateurs disposant de licences Tableau, nous avons organisé et enregistré un webinaire d'une demi-heure sur l'utilisation du serveur et des tableaux de bord. Ils ont parlé de projets sur le serveur, travaillant avec les contrôles natifs de tous les tableaux de bord - c'est le panneau supérieur (rafraîchir, pause, ...). Il est impératif d'en informer tous les utilisateurs de Tableau afin qu'ils puissent travailler pleinement avec les fonctionnalités natives et ne pas faire de demandes de développement de fonctionnalités qui répètent le travail des contrôles natifs.
Le principal obstacle à la maîtrise d'un outil (et même de quelque chose de nouveau) est généralement la crainte qu'il ne soit pas possible de comprendre et de travailler avec cette fonctionnalité. Par conséquent, la formation est peut-être l'étape la plus importante dans la mise en œuvre de l'approche BI en libre-service. Le résultat de la mise en œuvre de ce modèle dépendra grandement de lui - s'il prendra racine dans l'entreprise et, dans l'affirmative, à quelle vitesse. Lors du lancement des webinaires, les obstacles à l'utilisation de Tableau doivent être supprimés.
Nous avons organisé deux groupes de webinaires pour les personnes qui ne sont pas familiarisées avec le travail des bases de données:
- Kit de connaissances pour débutants:
- Connexion de données, types de connexion, types de données, transformations de données de base, normalisation des données (1 heure).
- Visualisations de base, agrégation de données, calculs de base (1 heure).
- /, (2 ).
Dans ce premier webinaire de lancement, nous couvrons tout ce qui concerne la connectivité des données et la transformation des données dans Tableau. Étant donné que les gens ont généralement un niveau de maîtrise de base de MS Excel, il est important d'expliquer ici en quoi le travail dans Excel est fondamentalement différent de travailler dans Tableau. C'est un point très important, car vous devez faire passer une personne de la logique des tableaux avec des cellules colorées à la logique des données de base de données normalisées. Lors du même webinaire, nous expliquons le travail de JOIN, UNION, PIVOT, et abordons également le Blending. Dans le premier webinaire, on aborde à peine la visualisation des données, son objectif est d'expliquer comment travailler et transformer vos données pour Tableau. Il est important que les gens comprennent que les données sont primordiales et que la plupart des problèmes surviennent au niveau des données, et non au niveau de la visualisation.
Le deuxième webinaire sur le libre-service vise à parler de la logique de création de visualisations dans Tableau. Tableau est très différent des autres outils de BI précisément en ce qu'il possède son propre moteur et sa propre logique. Dans d'autres systèmes, par exemple, dans PowerBI, il existe un ensemble de visuels prêts à l'emploi (vous pouvez télécharger des modules supplémentaires dans le magasin), mais ces modules ne sont pas personnalisables. Dans Tableau, vous disposez en fait d'une ardoise vierge sur laquelle vous pouvez créer tout ce que vous voulez. Bien sûr, Tableau a ShowMe - un menu de visualisations de base, mais tous ces graphiques et diagrammes peuvent et doivent être construits selon la logique de Tableau. À notre avis, si vous voulez apprendre à quelqu'un à travailler avec Tableau, vous n'avez pas besoin d'utiliser ShowMe pour créer des graphiques - la plupart d'entre eux ne seront pas utiles aux gens au début, mais vous devez enseigner exactement la logique de la construction. visualisations. Pour les tableaux de bord d'entreprise, il suffit de savoircomment construire:
- Des séries chronologiques. Graphiques linéaires / surfaciques (graphiques linéaires),
- Diagramme à barres
- Nuage de points,
- les tables
Cet ensemble de visualisations est suffisant pour l'auto-analyse des données.
Séries temporelles: elles sont très souvent utilisées en entreprise car il est intéressant de comparer des métriques à différentes périodes de temps. Probablement, tous les employés de l'entreprise examinent la dynamique des résultats commerciaux dans notre pays. Nous utilisons des graphiques à barres pour comparer les métriques par catégorie. Les nuages de points sont rarement utilisés, généralement pour trouver des corrélations entre les métriques. Les tableaux: quelque chose dont les tableaux de bord d'entreprise ne peuvent pas se débarrasser complètement, mais chaque fois que possible, nous essayons de minimiser leur nombre. Dans les tableaux, nous collectons les valeurs numériques des métriques par catégorie.
Autrement dit, nous envoyons les gens sur un flottant gratuit après 1 heure de formation au travail avec les données et 1 heure de formation aux calculs et visualisations de base. Ensuite, les gars eux-mêmes travaillent avec leurs données pendant un certain temps, font face à des problèmes, acquièrent de l'expérience, mettent la main dessus. Cette étape dure en moyenne 2 à 4 semaines. Naturellement, pendant cette période, il est possible de consulter l'équipe BI si quelque chose ne fonctionne pas.
Après la première étape, les collègues doivent améliorer leurs compétences et explorer de nouvelles opportunités. Pour cela, nous avons préparé des webinaires de formation approfondie. En eux, nous montrons comment travailler avec les fonctions LOD, les fonctions de table, les scripts Python pour TabPy. Nous travaillons avec des données d'entreprise en direct, qui sont toujours plus intéressantes que les fausses ou les données de l'ensemble de données de base de Tableau - Superstore. Dans les mêmes webinaires, nous parlons des principales fonctionnalités et astuces de Tableau qui sont utilisées sur les tableaux de bord propriétaires, par exemple:
- Echange de feuilles (remplacement de feuilles),
- Agrégation de graphiques à l'aide de paramètres,
- Formats de date et métrique
- Rejeter les périodes incomplètes pour les agrégations hebdomadaires / mensuelles.
Toutes ces astuces et fonctionnalités étaient habituelles à utiliser il y a quelques années, donc tout le monde dans l'entreprise s'y est habitué et nous les avons adoptées dans les normes de développement du tableau de bord. Nous utilisons des scripts Python pour calculer certaines métriques internes, tous les scripts sont déjà prêts, et pour le libre-service, nous devons comprendre comment les insérer dans nos calculs.
Ainsi, nous n'organisons que 4 heures de webinaires pour démarrer le libre-service, ce qui suffit généralement à une personne motivée pour commencer à travailler avec Tableau et analyser les données par elle-même. De plus, pour les analystes de données, nous avons nos propres webinaires, ils sont accessibles au public et vous pouvez vous familiariser avec eux.
Développement de sources de données pour le libre-service
Une fois le projet pilote réalisé, nous l'avons considéré comme un succès et avons augmenté le nombre d'utilisateurs du libre-service. L'un des grands défis consistait à préparer les sources de données pour différentes équipes. Les gars de Self-Service peuvent travailler avec plus de 200 millions de lignes, donc l'équipe d'ingénierie des données a dû trouver comment implémenter de telles sources de données. Pour la plupart des tâches analytiques, nous utilisons Redshift en raison de la vitesse de lecture des données et de la facilité d'utilisation. Mais donner accès à la base de données à chaque personne depuis le Self-Service était risqué du point de vue de la sécurité de l'information.
La première idée était de créer des sources avec une connexion en direct à la base de données, c'est-à-dire que plusieurs sources ont été publiées sur Tableau Server qui se présentaient soit dans des tables, soit dans des vues préparées de Redshift. Dans ce cas, nous n'avons pas stocké de données sur le serveur Tableau, et les utilisateurs via ces sources sont eux-mêmes passés de leur Tableau Desktop (clients) à la base de données. Cela fonctionne lorsque les tables sont petites (des millions) ou que les requêtes Tableau ne sont pas trop complexes. Au fur et à mesure de leur développement, les gars ont commencé à compliquer leurs tableaux de bord dans Tableau, à utiliser des LOD, des tris personnalisés et des scripts Python. Naturellement, cela a conduit à un ralentissement du travail de certains tableaux de bord en libre-service. Par conséquent, quelques mois après le lancement du Self-Service, nous avons revu l'approche du travail avec les sources.
La nouvelle approche que nous avons utilisée jusqu'à présent a implémenté des extraits publiés sur Tableau Server. Je dois dire que Self-Service a constamment de nouvelles tâches, et qu'ils reçoivent des demandes d'ajout de nouveaux champs à la source, bien sûr, les sources de données sont constamment modifiées. Nous avons développé la stratégie suivante pour travailler avec les sources:
- Selon le mandat de la source du côté libre-service, les données sont collectées dans les tables de la base de données.
- Une vue non matérialisée est créée dans le schéma de test de la base de données Redshift.
- La soumission est testée pour l'exactitude des données par l'équipe d'assurance qualité.
- En cas de résultat positif de la vérification, la vue est élevée sur le schéma de redshift prod.
- L'équipe d'ingénierie des données prend une vue pour le support - les scripts d'analyse de la validité des données sont connectés, les alarmes ETL sont connectées et les droits de lecture sont accordés à l'équipe en libre-service.
- Tableau Server (), .
- ETL .
- .
- , Self-Service.
Un peu sur le point 7. Nativement, Tableau vous permet de créer des extraits selon un calendrier avec une différence minimale de 5 minutes. Si vous savez avec certitude que vos tables dans la base de données sont toujours mises à jour à 4 heures du matin, vous pouvez simplement définir l'extrait à 5 heures du matin pour que vos données soient collectées. Cela couvre une gamme de tâches. Dans notre cas, les tableaux sont collectés en fonction des données de différents fournisseurs, y compris. En conséquence, si un fournisseur ou notre service interne n'a pas réussi à mettre à jour sa partie des données, alors la table entière est considérée comme invalide. Autrement dit, vous ne pouvez pas simplement définir un horaire pour une heure fixe. Par conséquent, nous utilisons l'API Tableau pour exécuter des extraits lorsque les tables sont prêtes. Les extraits de signaux de lancement sont générés par notre service ETL après s'être assuré que toutes les nouvelles données sont arrivées et sont valides.
Cette approche vous permet d'avoir des données valides fraîches dans l'extrait avec une latence minimale.
Publication de tableaux de bord en libre-service sur Tableau Server
Nous ne limitons délibérément pas les personnes à expérimenter leurs données et nous permettons de publier et de partager nos classeurs. Au sein de chaque équipe, si une personne pense que son tableau de bord est utile aux autres, ou que l'employé a besoin d'un tableau de bord sur le serveur, il peut le publier. L'équipe BI n'interfère pas dans les expérimentations internes des équipes, respectivement, elle élabore toute la logique des tableaux de bord et des calculs eux-mêmes. Il y a des cas où un projet intéressant sort du Self-Service, qui est ensuite complètement transféré au support de l'équipe BI et passe en production. C'est exactement l'effet même du Self-Service, lorsque les gens, ayant une bonne compréhension de leurs tâches commerciales, commencent à travailler avec leurs données et forment une nouvelle stratégie pour leur travail. Sur cette base, nous avons créé le schéma de projets suivant sur le serveur:
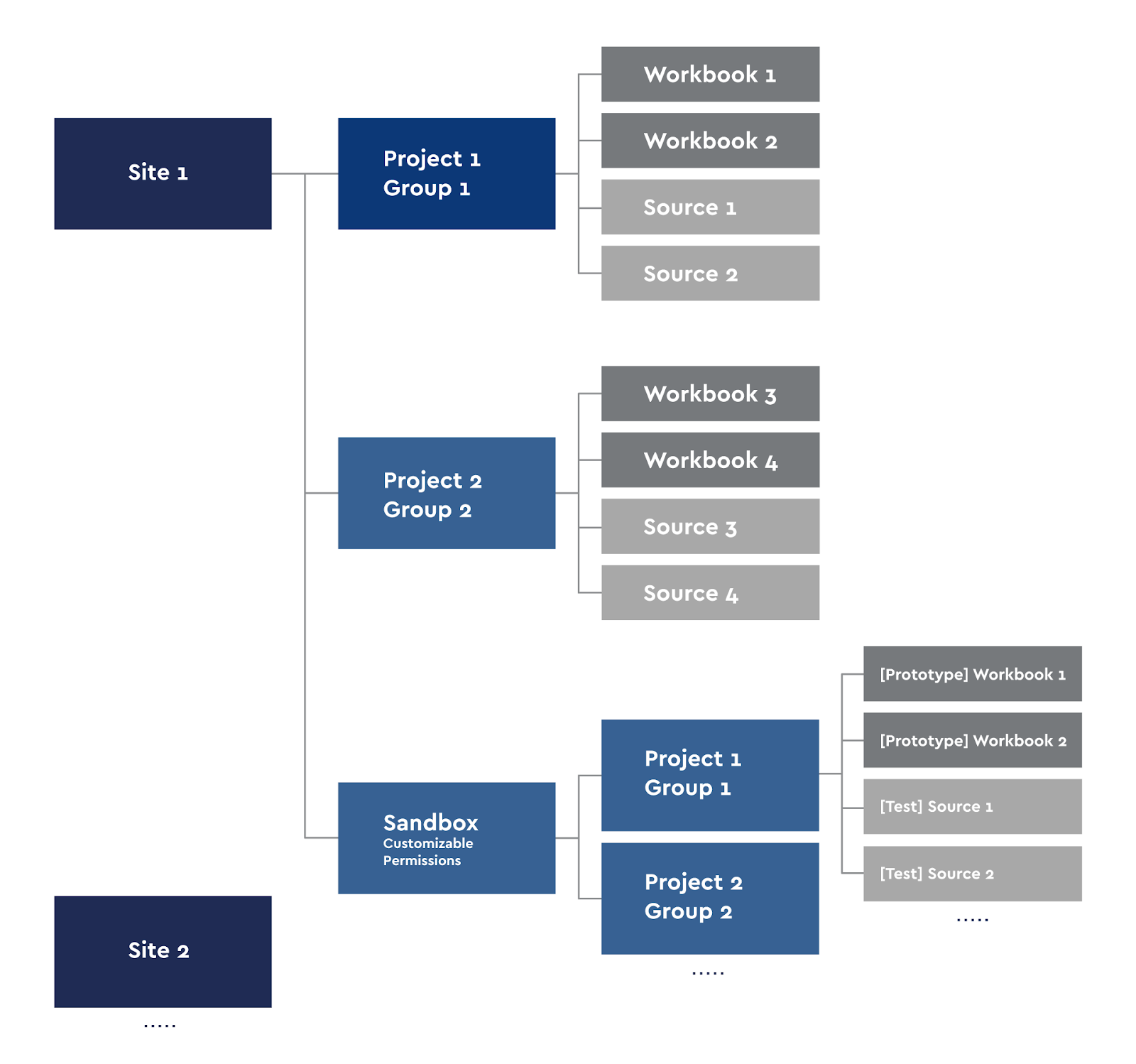
Diagramme de projet Tableau Server
Chaque utilisateur Creator peut publier ses classeurs sur le serveur ou effectuer l'analyse localement. Pour le Self-Service, nous avons créé notre propre Sandbox avec nos groupes de projets.
Les sites de Tableau sont divisés idéologiquement afin que les utilisateurs d'un site ne voient pas le contenu d'un autre.Nous avons donc divisé le serveur en sites dans des zones qui ne se chevauchent pas: par exemple, l'analyse des jeux et la finance. Nous utilisons l'accès de groupe. Chaque site a des projets dans lesquels les droits sur leurs classeurs et sources sont hérités. Autrement dit, le groupe d'utilisateurs du groupe 1 ne voit que leurs classeurs et sources de données. L'exception à cette règle est le site Sandbox, qui comporte également des sous-projets. Nous utilisons Sandbox pour le prototypage, le développement de nouveaux tableaux de bord, les tester et pour les besoins du Self-Service. Toute personne disposant d'un accès de publication à son projet Sandbox peut publier ses prototypes.
Surveillance des sources et des tableaux de bord sur Tableau Server
Depuis que nous avons transféré la charge des demandes de tableaux de bord en libre-service de la base de données vers Tableau Server, nous travaillons avec de grandes sources de données et ne limitons pas les personnes aux demandes aux sources publiées, un autre problème est survenu: surveiller les performances de ces tableaux de bord et surveiller les sources.
Surveiller les performances des tableaux de bord et les performances des serveurs Tableau est une tâche à laquelle sont confrontées les moyennes et grandes entreprises.Par conséquent, de nombreux articles ont été écrits sur les performances des tableaux de bord et leur réglage. Nous ne sommes pas devenus des pionniers dans ce domaine, notre surveillance repose sur plusieurs tableaux de bord basés sur la base de données PostgreSQL Tableau Server interne. Cette surveillance fonctionne avec tout le contenu, mais vous pouvez sélectionner des tableaux de bord en libre-service et voir leurs performances.
L'équipe BI résout de temps à autre les problèmes d'optimisation du tableau de bord. Les utilisateurs se posent parfois la question «Pourquoi le tableau de bord est-il lent?», Et nous devons comprendre ce qu'est «lent» du point de vue de l'utilisateur et quels critères numériques peuvent caractériser ce «lent». Afin de ne pas interroger l'utilisateur et de ne pas lui enlever son temps de travail pour un récit détaillé des problèmes, nous surveillons et analysons les requêtes http, trouvons les plus lentes et recherchons les raisons. Après cela, nous optimiserons les tableaux de bord, si cela peut conduire à une augmentation des performances. Il est clair qu'avec une connexion en direct aux sources, il y aura des retards associés à la formation d'une vue dans la base de données, des retards dans la réception des données. Il existe également des retards de réseau que nous étudions avec notre équipe de support pour l'ensemble de l'infrastructure informatique, mais nous ne nous attarderons pas sur eux dans cet article.
Un peu sur les requêtes http
Chaque interaction de l'utilisateur avec le tableau de bord dans le navigateur lance sa propre requête http, transmise à Tableau Server. L'historique complet de ces requêtes est stocké dans la base de données PostgreSQL Tableau Server interne, la période de stockage par défaut est de 7 jours. Cette période peut être augmentée en modifiant les paramètres de Tableau Server, mais nous ne voulions pas augmenter le tableau des requêtes http, nous recueillons donc simplement un extrait incrémentiel qui ne contient que des données fraîches chaque jour, tandis que les anciennes ne sont pas écrasées. C'est un bon moyen avec un minimum de ressources à conserver dans l'extrait sur les données historiques du serveur qui ne sont plus dans la base de données.
Chaque requête http a son propre type (action_type). Par exemple, _bootstrap est le chargement initial de la vue, relative-date-filter est le filtre de date (curseur). La plupart des types peuvent être identifiés par le nom, de sorte que ce que chaque utilisateur fait avec le tableau de bord est clair: quelqu'un regarde plus les info-bulles, quelqu'un change les paramètres, quelqu'un crée ses propres vues personnalisées et quelqu'un décharge les données.
Vous trouverez ci-dessous notre tableau de bord de service qui nous permet de définir des tableaux de bord lents, des types de demandes lentes et des utilisateurs qui doivent attendre.
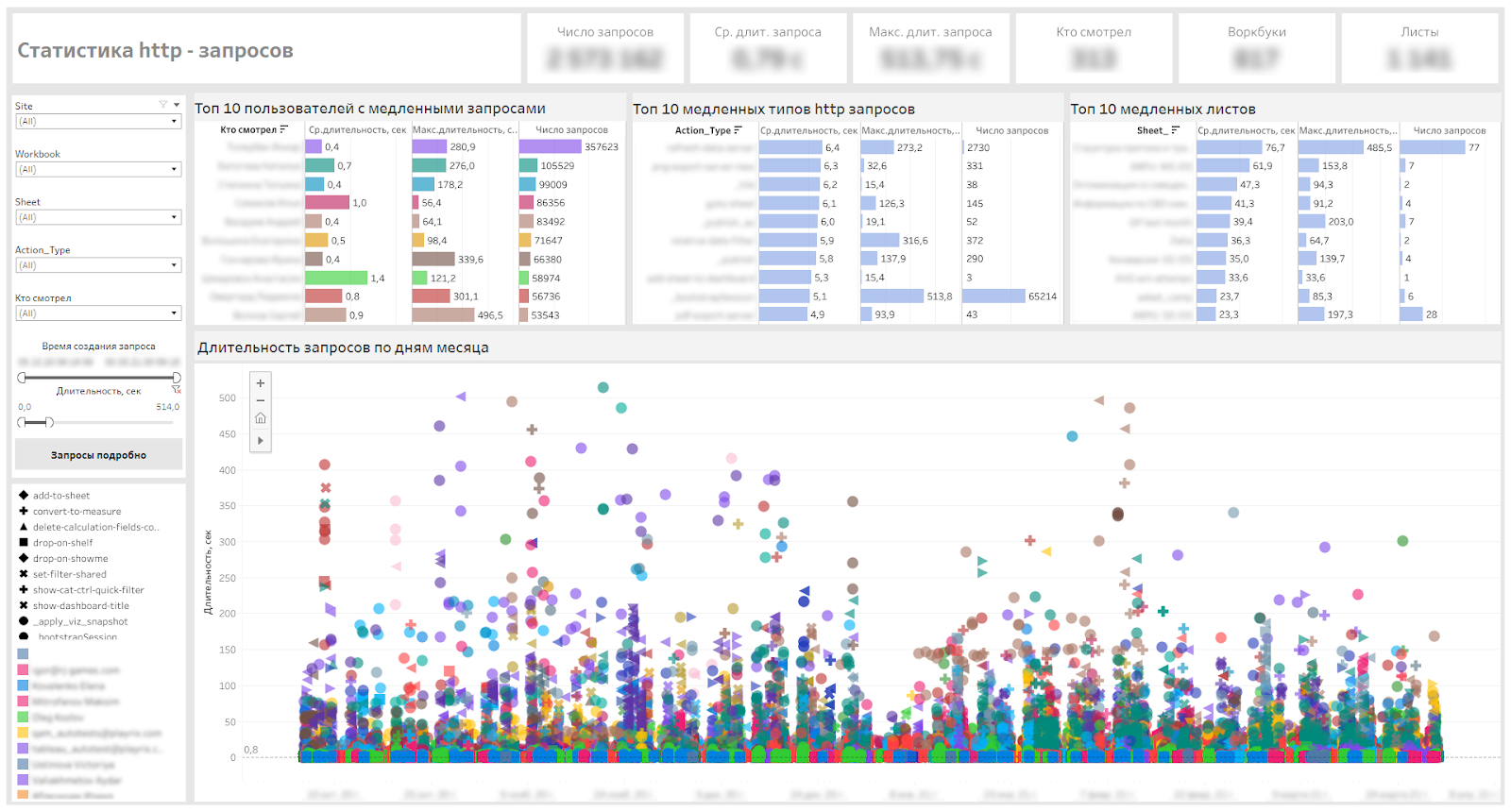
Tableau de bord pour le suivi des requêtes http
Surveillance des sessions VizQL
Lorsqu'un tableau de bord est ouvert dans le navigateur, une session VizQL est lancée sur le serveur Tableau, dans lequel les visualisations sont rendues, des ressources sont également allouées pour maintenir la session. Ces sessions sont abandonnées après 30 minutes d'inactivité par défaut.
Au fur et à mesure que le nombre d'utilisateurs sur le serveur augmentait et que le libre-service était introduit, nous avons reçu plusieurs demandes d'augmentation des limites de session VizQL. Le problème pour les utilisateurs était qu'ils ouvraient des tableaux de bord, définissaient des filtres, regardaient quelque chose et passaient à leurs autres tâches en dehors de Tableau Server, après un certain temps, ils sont revenus aux tableaux de bord ouverts, mais ils ont été réinitialisés à la vue par défaut, et ils ont dû être un morceau réutilisé. Notre tâche était de rendre l'expérience utilisateur plus confortable et de nous assurer que la charge sur le serveur n'augmente pas de manière critique.
Les deux paramètres suivants sur le serveur peuvent être modifiés, mais vous devez comprendre que la charge sur le serveur peut augmenter.
vizqlserver.session.expiry.minimum 5
Nombre de minutes d'inactivité après lesquelles une session VizQL peut être supprimée si le processus VizQL commence à manquer de mémoire.
vizqlserver.session.expiry.timeout 30 Nombre de minutes d'inactivité après lesquelles une session VizQL est supprimée.
Par conséquent, nous avons décidé de surveiller les sessions VizQL et de suivre:
- Nombre de séances,
- Nombre de sessions par utilisateur,
- Durée moyenne des séances,
- La durée maximale des sessions.
De plus, nous devions comprendre les jours et les heures d'ouverture du plus grand nombre de sessions.
Le résultat est un tableau de bord comme celui-ci:

Tableau de bord de suivi des sessions VizQL
Depuis début janvier de cette année, nous avons commencé à augmenter progressivement les limites et à surveiller la durée des sessions et la charge. La durée moyenne des sessions est passée de 13 à 35 minutes - cela se voit sur les graphiques de la durée moyenne des sessions. Les paramètres finaux sont les suivants:
vizqlserver.session.expiry.minimum 120 vizqlserver.session.expiry.timeout 240
Après cela, nous avons reçu des commentaires positifs des utilisateurs, ce qui est devenu beaucoup plus agréable à travailler - les sessions ont cessé de s'estomper.
Les cartes thermiques de ce tableau de bord nous permettent également de planifier les travaux de maintenance pendant les heures de demande minimale du serveur.
Nous surveillons l'évolution de la charge sur le cluster - CPU et RAM - dans Zabbix et AWS console. Nous n'avons pas enregistré de changements significatifs dans la charge lors de l'augmentation des délais d'attente.
Si nous parlons de ce qui peut beaucoup plier votre serveur Tableau, il peut s'agir, par exemple, d'un tableau de bord non optimisé. Par exemple, créez une table dans Tableau avec des dizaines de milliers de lignes par catégories et identifiant de certains événements, et dans Mesure, utilisez les calculs LOD au niveau de l'identifiant. Avec une probabilité élevée, l'affichage de la table sur le serveur ne fonctionnera pas et vous obtiendrez un plantage avec une erreur inattendue, car tous les LOD en granulation minimale consommeront beaucoup de mémoire et très bientôt le processus fonctionnera à 100%. de la consommation de mémoire.
Cet exemple est donné ici afin de préciser qu'un tableau de bord non optimal peut consommer toutes les ressources du serveur, et même 100 sessions VizQL des tableaux de bord optimaux ne consommeront pas autant de ressources.
Surveillance des sources de données du serveur
Ci-dessus, nous avons noté que pour le libre-service, nous avons préparé et publié plusieurs sources de données sur le serveur. Toutes les sources sont des extraits de données. Les sources publiées sont enregistrées sur le serveur et mises à la disposition des personnes qui travaillent avec Tableau Desktop.
Tableau a la capacité de marquer les sources comme certifiées. C'est ce que fait l'équipe BI lors de la préparation des sources de données pour le libre-service. Cela garantit que la source elle-même a été testée.
Les sources publiées peuvent atteindre 200 millions de lignes et 100 champs. Pour le libre-service, il s'agit d'un volume très important, car peu d'entreprises disposent de sources de tels volumes pour des analyses indépendantes.
Naturellement, lors de la collecte des exigences pour générer une source, nous examinons comment nous pouvons réduire la quantité de données dans la source en regroupant des catégories, en divisant les sources par projet ou en limitant les périodes. Mais toujours, en règle générale, les sources sont obtenues à partir de 10 millions de lignes.
Étant donné que les sources sont volumineuses, occupent de l'espace sur le serveur, utilisez les ressources du serveur pour mettre à jour les extraits, puis toutes doivent être surveillées, pour voir à quelle fréquence elles sont utilisées et à quelle vitesse elles augmentent en volume. Pour cela, nous avons fait de la surveillance des sources de données publiées. Il montre les utilisateurs se connectant aux sources, les classeurs qui utilisent ces sources. Cela vous permet de trouver des sources non pertinentes ou des sources problématiques que l'extrait ne peut pas collecter.
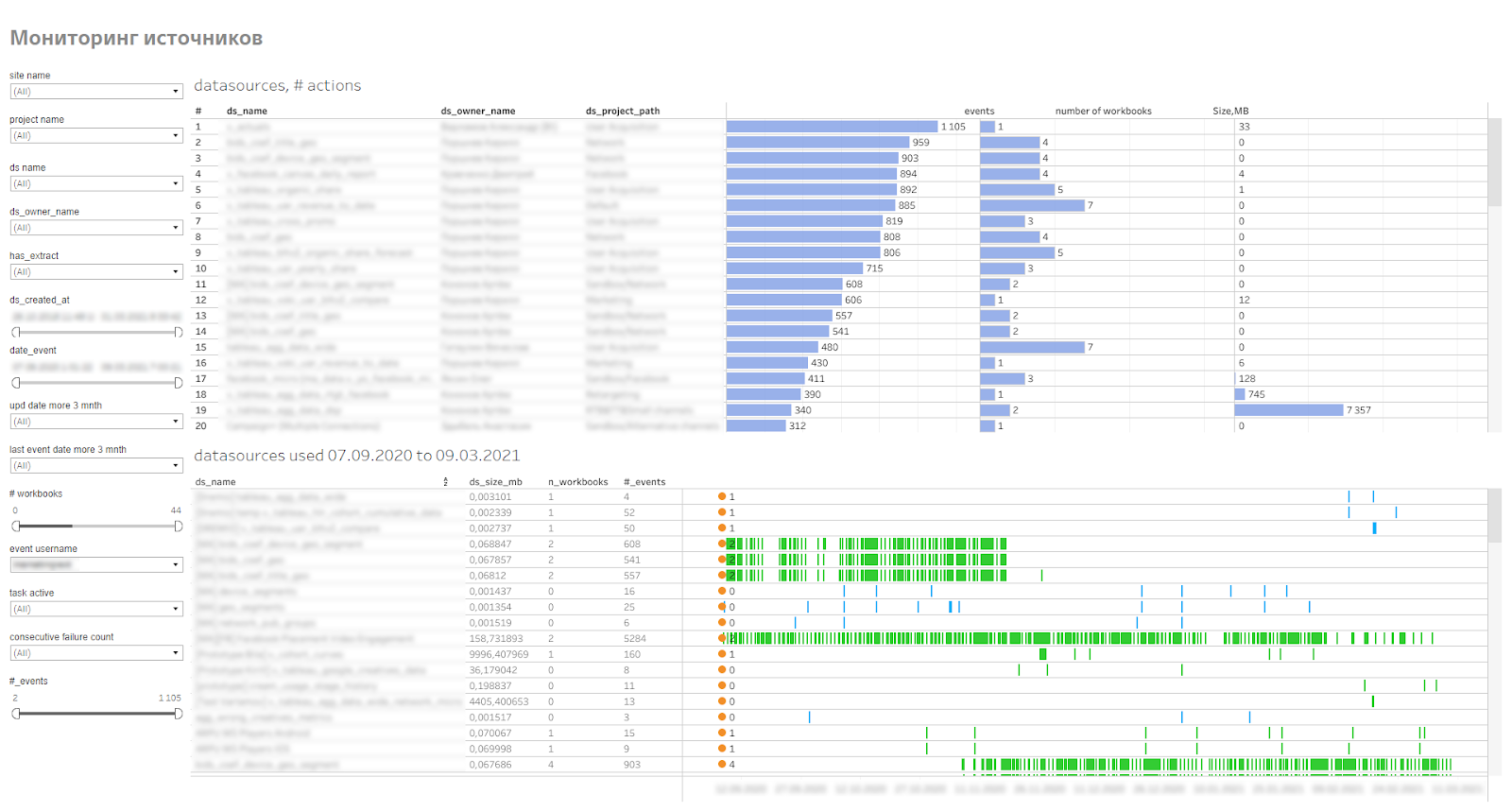
Tableau de bord de surveillance de la source
Résultat
Nous utilisons l'approche Self-Service depuis 1 an et demi. Pendant ce temps, 50 utilisateurs ont commencé à travailler de manière indépendante avec des données. Cela a réduit la charge sur l'équipe de BI et a permis aux gars de ne pas attendre que l'équipe de BI arrive à leur tâche spécifique de développer un tableau de bord. Il y a environ 5 mois, nous avons commencé à connecter d'autres domaines à l'auto-analyse.
Nous prévoyons de dispenser une formation sur les meilleures pratiques de maîtrise des données et de visualisation.
Il est important de comprendre que le processus de libre-service ne peut pas être mis en œuvre rapidement dans toute l'entreprise; cela prendra du temps. Si le processus de transition est organique, sans choquer les employés, après quelques années de mise en œuvre, vous pouvez obtenir des processus fondamentalement différents pour travailler avec des données dans différents services et domaines de l'entreprise.