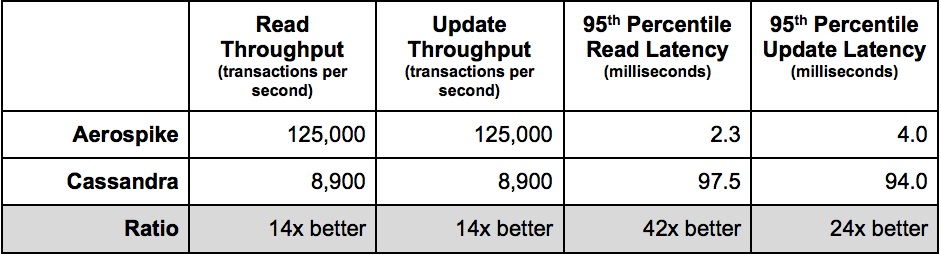
Par une étonnante coïncidence, Scylla (ci-après SC) bat également CS facilement, qui annonce fièrement sur sa page d'accueil:

Ainsi, la question se pose naturellement, qui clôturera qui, la baleine ou l'éléphant?
Dans mon test, la version optimisée de HBase (ci-après dénommée HB) fonctionne avec CS sur un pied d'égalité, donc ici ce ne sera pas un prétendant à la victoire, mais seulement dans la mesure où tout notre traitement est basé sur HB et je veux comprendre ses capacités par rapport aux leaders.
Il est clair que HB et CS sont gratuits, mais d'un autre côté, si vous avez besoin de X fois plus de matériel pour obtenir les mêmes performances, il est plus rentable de payer pour des logiciels que d'allouer un étage dans le centre de données pour un coût élevé. coussins chauffants. D'autant plus que si nous parlons de performances, alors que les disques durs, en principe, ne sont pas en mesure de donner au moins une vitesse acceptable de lecture aléatoire (voir « Pourquoi les lectures HDD et Fast Random Access sont incompatibles »), ce qui signifie à son tour acheter un SSD, qui dans les volumes requis pour un vrai BigData, est un plaisir assez coûteux.
Ainsi, ce qui suit a été fait. J'ai loué 4 serveurs dans le cloud AWS dans la configuration i3en.6xlarge où chacun à bord:
CPU - 24 vcpu
MEM - 192 Go
SSD - 2 x 7500 Go
Si quelqu'un veut le répéter, on constate tout de suite qu'il est très important pour la reproductibilité de prendre des configurations où le volume total des disques (7500 Go). Sinon, les disques devront être partagés avec des voisins imprévisibles, ce qui ruinera sûrement vos tests, car ils semblent probablement être une charge très précieuse.
Ensuite, j'ai déployé SC en utilisant le constructeur , qui a été aimablement fourni par le fabricant sur son propre site Web. Ensuite, j'ai téléchargé l'utilitaire YCSB (qui est presque une norme pour les tests de base de données comparatifs) pour chaque nœud de cluster.
Il n'y a qu'une nuance importante, dans presque tous les cas, nous utilisons le modèle suivant: lire l'enregistrement avant de changer + écrire la nouvelle valeur.
J'ai donc modifié la mise à jour comme suit:
@Override
public Status update(String table, String key,
Map<String, ByteIterator> values) {
read(table, key, null, null); // << added read before write
return write(table, key, updatePolicy, values);
}
Ensuite, j'ai commencé la charge simultanément à partir des 4 hôtes (les mêmes où se trouvent les serveurs de base de données). Ceci est fait délibérément, car parfois les clients de certaines bases de données consomment plus de CPU que d'autres. Étant donné que la taille du cluster est limitée, je voudrais comprendre l'efficacité globale de la mise en œuvre des parties serveur et client.
Les résultats des tests seront présentés ci-dessous, mais avant de passer à eux, il convient de considérer quelques nuances plus importantes.
Quant à AS, il s'agit d'une base de données très attractive, leader dans la catégorie satisfaction client selon la ressource g2.
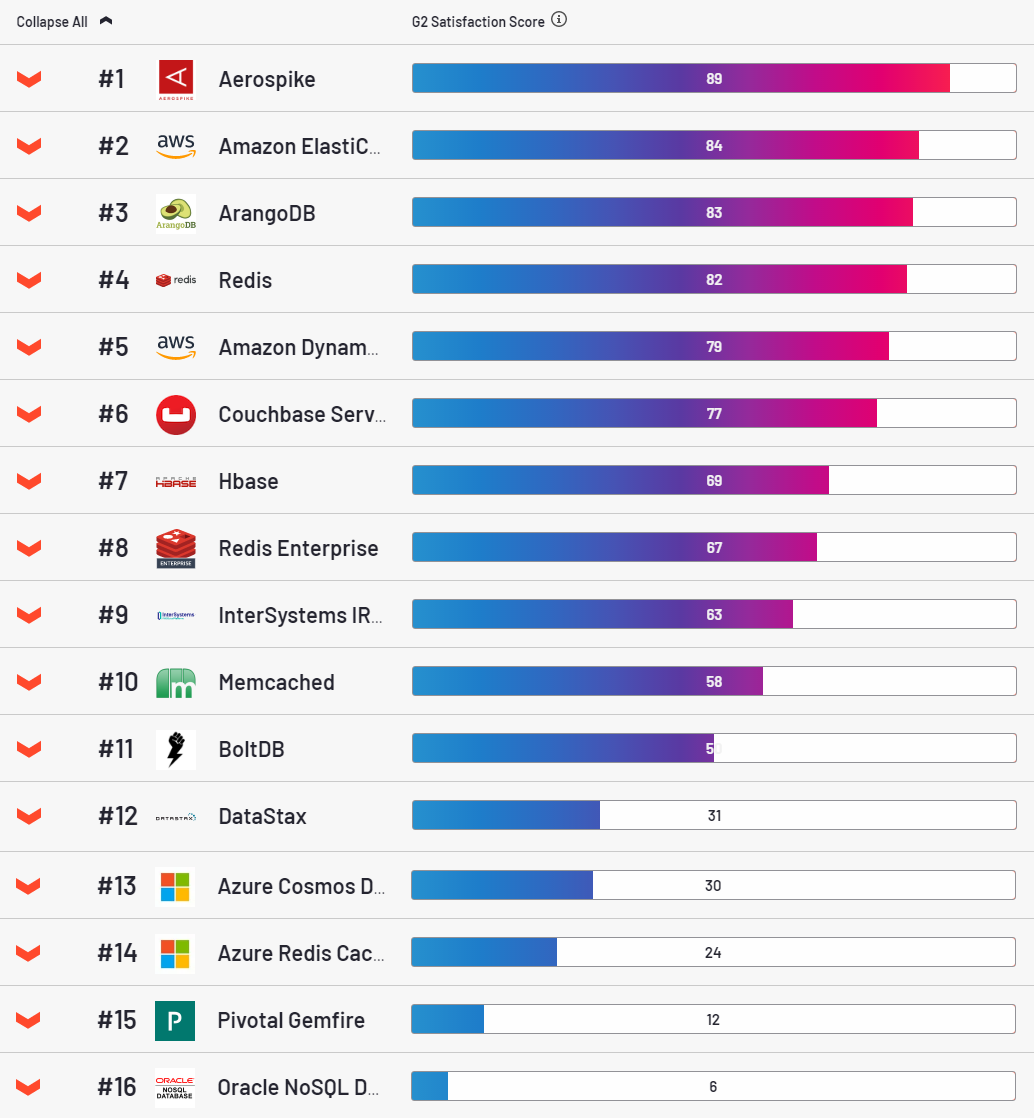
Franchement, j'aimais ça aussi. C'est simple, avec ce scriptse déploie assez facilement dans le cloud. Stable, c'est un plaisir à configurer. Cependant, il présente un très gros inconvénient. Pour chaque clé, il alloue 64 octets de RAM. Cela semble un peu, mais dans les volumes industriels, cela devient un problème. Une entrée typique dans nos tables est de 500 octets. C'est cette quantité de valeur que j'ai utilisée dans presque * tous les tests (* pourquoi presque sera dit ci-dessous).
Puisque nous stockons 3 copies de chaque enregistrement, il s'avère que pour stocker 1 Po de données propres (3 Po de données sales), nous devrons allouer seulement 400 To de RAM. Passer à autre chose ... non quoi?! Attendez une seconde, pouvez-vous y faire quelque chose? - nous avons demandé au vendeur.
Ha, bien sûr, vous pouvez faire beaucoup de choses, plier les doigts:
Ok, maintenant traitons HB et nous pouvons déjà considérer les résultats des tests. Pour installer Hadoop, Amazon fournit la plate-forme EMR, qui facilite le déploiement du cluster dont vous avez besoin. Je n'ai eu qu'à augmenter les limites du nombre de processus et de fichiers ouverts, sinon il s'est écrasé sous la charge et a remplacé hbase-server par mon assemblage optimisé (voir les détails ici ). Le deuxième point, HB ralentit sans vergogne lorsqu'on travaille avec des requêtes uniques, c'est un fait. Par conséquent, nous ne travaillons que par lots. Dans ce test, batch = 100. Il y a 100 régions dans le tableau.
Eh bien, et au dernier moment, toutes les bases de données ont été testées en mode «forte cohérence». Pour HB, c'est hors de la boîte. AS n'est disponible que dans la version entreprise (c'est-à-dire qu'il a été activé dans ce test). SC a fonctionné en mode de cohérence d'écriture = tout. Le facteur de réplication est partout 3.
Alors, allons-y. Insérer en AS:
10 sec: 360554 opérations; 36055,4 opérations actuelles / s;
20 sec: 698872 opérations; 33831,8 opérations actuelles / s;
...
230 sec: 7412626 opérations; 22938,8 opérations actuelles / s;
240 sec: 7542091 opérations; 12946,5 opérations actuelles / s;
250 sec: 7589682 opérations; 4759,1 opérations actuelles / s;
260 sec: 7599525 opérations; 984,3 opérations actuelles / s;
270 sec: 7602150 opérations; 262,5 opérations actuelles / s;
280 sec: 7602752 opérations; 60,2 opérations actuelles / s;
290 sec: 7602918 opérations; 16,6 opérations actuelles / s;
300 sec: 7603269 opérations; 35,1 opérations courantes / s;
310 sec: 7603674 opérations; 40,5 opérations actuelles / s;
Erreur lors de l'écriture de la clé user4809083164780879263: com.aerospike.client.AerospikeException $ Timeout: Client timeout: timeout = 10000 iterations = 1 failedNodes = 0 failedConns = 0 lastNode = 5600000A 127.0.0.1:3000
Erreur lors de l'insertion, sans réessayer. nombre de tentatives: 1 Limite de tentatives d'insertion: 0
Oups, vous êtes définitivement un
D'accord, continuons. Nous commençons à charger 200 millions d'enregistrements (INSERT), puis UPDATE, puis GET. Voici ce qui s'est passé (opérations - opérations par seconde):

IMPORTANT! C'est la vitesse d'un nœud! Il y en a 4 au total, c'est-à-dire pour obtenir la vitesse totale, vous devez multiplier par 4.
La première colonne contient 10 champs, ce n'est pas un test tout à fait juste. Ceux. c'est lorsque l'index est en mémoire, ce qui est inaccessible dans une vraie situation BigData.
La deuxième colonne regroupe 10 enregistrements en 1. il y a déjà de réelles économies de mémoire, exactement 10 fois. Comme vous pouvez le voir clairement sur le test, cette astuce n'est pas vaine, les performances diminuent considérablement. La raison est évidente, chaque fois que pour traiter un enregistrement, vous devez traiter 9 enregistrements adjacents. Les frais généraux sont plus courts.
Et enfin all-flush, voici à peu près la même image. Les insertions de rinçage sont pires, mais l'opération de mise à jour de la clé est plus rapide, donc nous ne comparerons plus qu'avec tout-flush.
En fait, ne tirons pas le chat tout de suite:

tout est généralement clair, mais que faut-il ajouter ici.
- AS , .
- SC - , :

Peut-être que quelque part il y a un montant avec les paramètres ou ce bogue avec le noyau a fait surface, je ne sais pas. Mais j'ai tout mis en place depuis et vers le script du vendeur, donc le cyclomoteur n'est pas le mien, toutes les questions sont pour lui.
Vous devez également comprendre qu'il s'agit d'une quantité très modeste de données et que sur de gros volumes, la situation peut changer. Au cours des expériences, j'ai brûlé plusieurs centaines de dollars, donc l'enthousiasme n'était suffisant que pour un test de leader à long terme et dans un mode limité à un serveur.
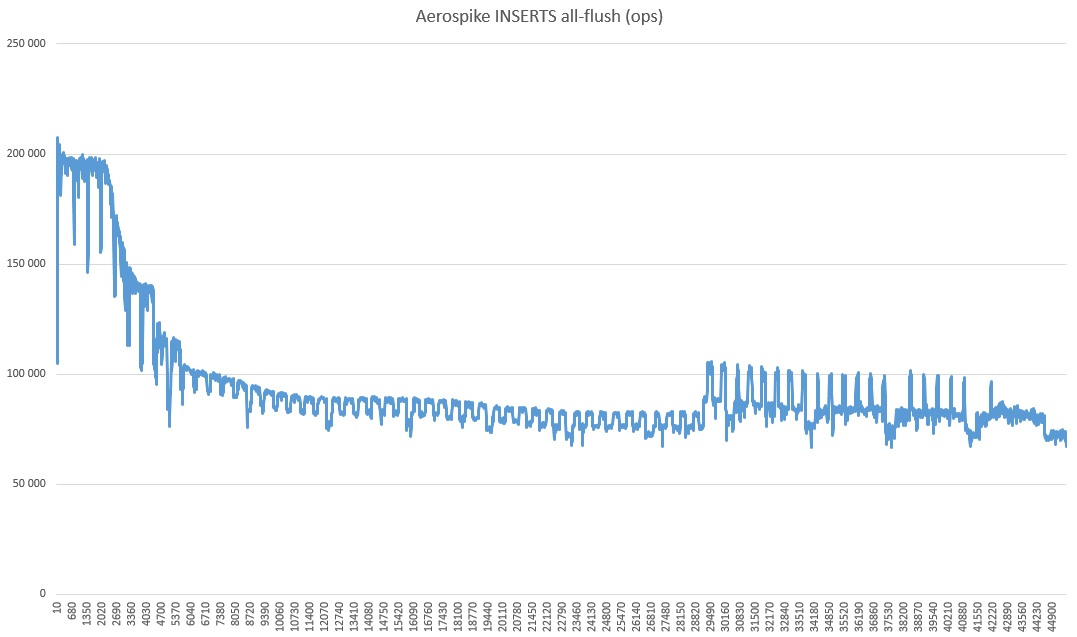
Pourquoi il s'est tellement calmé et quel genre de réveil dans le dernier tiers est un mystère de la nature. Vous pouvez également remarquer que la vitesse est radicalement plus élevée que dans les tests, un peu plus élevée. Je suppose que c'est parce que le mode de cohérence forte est désactivé (car il n'y a qu'un seul serveur).
Et enfin, GET + WRITE (en plus de plus de trois milliards d'enregistrements inondés par le test):
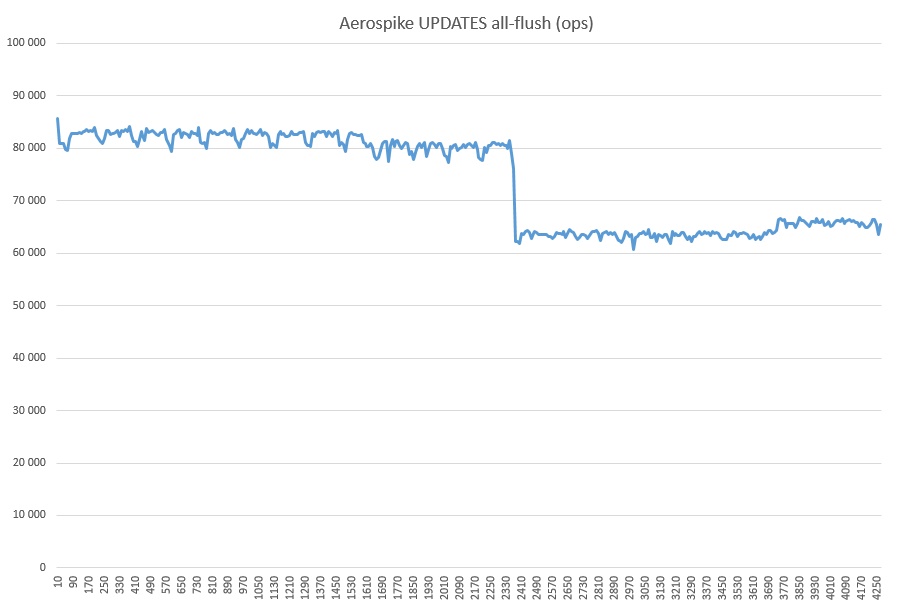
Quel genre de retrait est-ce, je ne devine pas dans mon cœur. Aucun processus étranger n'a été lancé. Cela a peut-être quelque chose à voir avec le cache SSD, car l'utilisation pendant tout le test AS en mode de vidage total était de 100%.

C'est tout. Les conclusions sont généralement claires, d'autres tests sont nécessaires. Il est souhaitable pour toutes les bases de données les plus populaires dans les mêmes conditions. Sur Internet, ce genre n'est pas grand-chose. Et ce serait bien, alors les fournisseurs de base seront motivés à optimiser, et nous choisirons délibérément les meilleurs.