
En linguistique informatique moderne, la compréhension du sens de ce qui est écrit ou dit est obtenue à l'aide de modèles de langage naturel (NLU). Avec la croissance progressive de l'audience des assistants virtuels Saliout, la question se pose d'optimiser nos services qui fonctionnent avec le langage naturel. Pour ce faire, il s'avère judicieux d'utiliser un modèle NLU fort pour résoudre plusieurs problèmes de traitement de texte à la fois. Dans cet article, nous allons vous montrer comment utiliser l'apprentissage multitâche pour améliorer les représentations vectorielles et entraîner un modèle NLU plus général à l'aide de SBERT.
Les services de traitement de texte très chargés résolvent un certain nombre de tâches NLP différentes :
- Reconnaître les intentions.
- Mettre en évidence les entités nommées.
- Analyse sentimentale.
- Analyse de toxicité.
- Recherchez des requêtes similaires.
Chacune de ces tâches a ses spécificités et, de manière générale, nécessite la construction et la formation d'un modèle distinct. Cependant, il n'est pas pratique de maintenir et d'exécuter un modèle NLU distinct pour chacune de ces tâches - le temps de traitement de la demande et la mémoire (vidéo) consommée augmentent considérablement. Au lieu de cela, nous utilisons un modèle NLU fort pour extraire des caractéristiques génériques du texte. En plus de ces fonctionnalités, nous appliquons des modèles relativement légers (adaptateurs), qui résolvent les problèmes de PNL appliqués. Dans le même temps, les NLU et les adaptateurs peuvent être exécutés sur différentes machines, ce qui facilite le déploiement et la mise à l'échelle des solutions.

Mais comment rendre les fonctionnalités identifiées par le modèle NLU de base suffisamment universelles pour qu'un modèle NLP de haute qualité puisse être construit dessus ? Trouvons-le.
Par tradition, nous présentons l'implémentation de notre approche en Python 3 et TensorFlow 1.15. Un guide complet étape par étape et des exemples de code sont disponibles ici - Colab .
Nous présentons également dans un modèle russe mis à jour un modèle russe SBERT-NLU classe BERT-large [427 millions d'options.] Version Multitask : huggingface [tensorflow, pytorch] .
Apprentissage multitâche. Pourquoi est-ce nécessaire ?
Lors du fonctionnement des modèles NLU, nous avons constaté que les caractéristiques allouées par les modèles entraînés pour une tâche (par exemple, NLI ) peuvent être réutilisées avec succès pour d'autres tâches en aval (par exemple, pour la classification ou l'analyse sentimentale). Pour ce faire, un modèle léger (adaptateur), affûté pour résoudre un nouveau problème, est entraîné sur les vecteurs sélectionnés par le modèle de base. Cela ne change pas le modèle de base.
Dans le même temps, la qualité de ces modèles d'adaptateur est généralement encore pire que si nous entraînions notre modèle NLU pour chaque tâche. La raison en est que les nouvelles données ne sont utilisées que pour les modèles d'adaptateur et n'améliorent pas le modèle de base. L'apprentissage multitâche nous aide à faire face à cela.
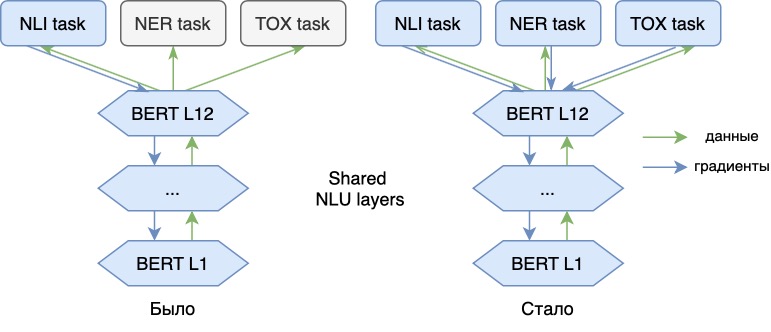
Maintenant, nous entraînons le modèle de langage non seulement sur le problème NLI principal, mais aussi sur des problèmes supplémentaires (NER, analyse de toxicité). L'ajout de nouvelles tâches nous permet d'ajouter de nouvelles "significations" aux vecteurs de notre modèle, les rend plus universels. Ainsi, le modèle pourra refléter dans ses vecteurs des informations, par exemple, sur les nuances émotionnelles du discours d'une phrase ou sur la partie du discours de chaque mot dans le texte. Avec des représentations vectorielles d'un tel modèle, ces problèmes peuvent être résolus plus efficacement.
0. Expérimenter
À titre d'exemple, envisagez d'enseigner à NLU sur trois tâches :
- Représentation de la phrase (NLI).
- Reconnaissance d'entité nommée (NER).
- Analyse des sentiments.
Pour enseigner la tâche principale de vectorisation des phrases, nous utilisons, comme la dernière fois , un ensemble de données pour l'inférence du langage naturel , contenant des paires de phrases avec des étiquettes qui indiquent une conséquence ("implication"), une contradiction ("contradiction") ou l'absence d'un lien sémantique (« neutre ») entre les phrases. Pour ces données, basées sur le modèle BERT, nous apprendrons une telle représentation vectorielle que la similitude entre les paires de phrases correspondantes sera plus grande que la similitude entre en conflit ou neutres les unes par rapport aux autres.
Nous allons former la tête NER à l'aide de l' ensemble de donnéesde la plate-forme Kaggle. Ce modèle affectera chaque jeton de la proposition en cours de traitement à l'un des nombreux types d'entités nommées IOB . Sa tâche est une classification multi-classes.
Pour le problème de l'analyse des sentiments, prenons les données du concours Tweet Sentiment Extraction . L'essence de ce concours est de prédire la couleur émotionnelle des commentaires sur les publications Twitter. Il existe trois classes dans l'ensemble de données : la couleur positive, neutre et négative de la réplique. Pour cet exemple, nous ne mettrons en évidence que deux classes : positive et négative. La tâche sera une classification binaire.
Nous utilisons la base BERT anglaise pré-entraînée comme modèle de vectorisation de base.
Plan d'expérimentation :
- Préparation des jeux de données.
- Implémentation du générateur de lots.
- Détermination de la fonction de perte.
- Construire le modèle.
- Préparation du processus de validation.
- Formation de modèle.
- Discussion des résultats et conclusions.
1. Préparation des données
Tout d'abord, chargeons les jeux de données nécessaires à l'apprentissage du modèle de vectorisation de phrases de base - [ SNLI , MNLI ] et à sa validation - [ STS SICK ]. De plus, nous avons besoin d'un modèle BERT anglais pré-entraîné. Heureusement, tout cela est dans le domaine public :
Ensuite, allons sur la plate - forme kaggle et téléchargeons des données à partir de là pour une analyse sentimentale - ici, nous avons besoin de train.csv. Pour ces données, éliminons les exemples négatifs dans une classe séparée et combinons le reste dans un groupe commun (positif, neutre) :
Il reste à récupérer les données pour NER et à les préparer au format [texte, ner_labels] :
2. Générateur de lots
Écrivons maintenant une procédure pour générer un ensemble d'exemples pour l'apprentissage d'un réseau de neurones. Du fait que nous recevons maintenant non pas un, mais déjà trois
jeux de données en entrée, nous avons également besoin de plus de générateurs : pour une tâche NLI, en utilisant le générateur de triplet, nous allons générer des triplets
[ancre, positif, négatif] :
pour les problèmes de classification NER et Toxic utilisent le même générateur de données générant des paires [échantillon, étiquette]. Ici, nous sélectionnons au hasard plusieurs exemples avec leurs étiquettes de classe à partir des ensembles de données fournis et formons un package :
Enfin, combinons les trois générateurs en un générateur complexe commun qui concaténera les trois types de paquets de données en un seul pour entraîner le modèle :
3. Fonction de perte
Maintenant, pour chaque tâche, nous définissons notre propre fonction d'erreur, puis les combinons pour la fonction de perte finale :
- Nous formulerons également le problème de "convergence" des phrases paraphrasées comme un problème de classement et utiliserons la Softmax Loss légèrement modifiée, déjà connue de travaux antérieurs, comme fonction d'erreur :
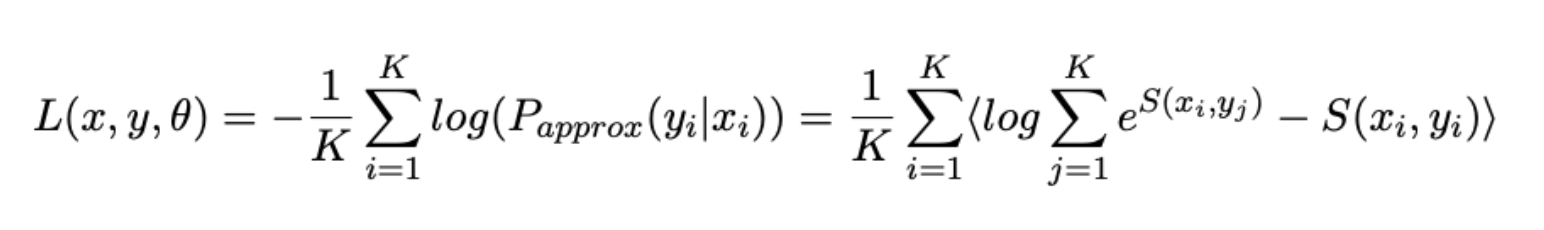
- Binary Cross Entropy Loss:

- NER- -, CrossEnrtopyLoss:

- Joint-loss, :
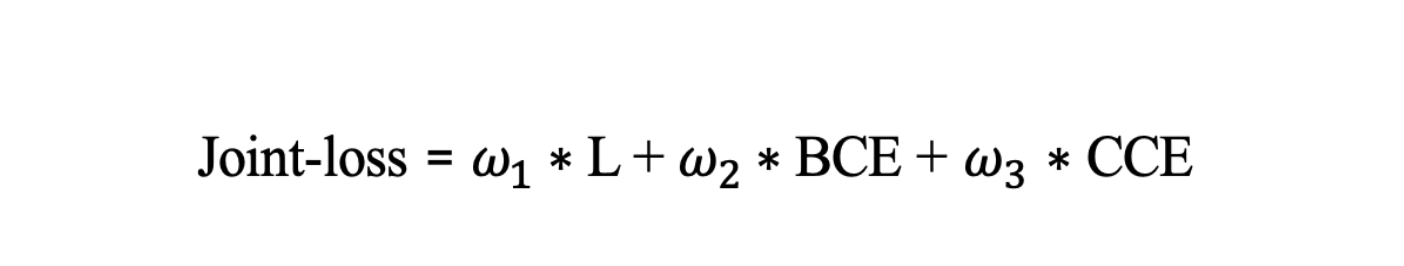
4.
Notre modèle se compose de la partie NLU principale (nous utilisons ici la base BERT) et de trois adaptateurs "heads", spécifiques à chaque tâche.
Pour les tâches NLI et Toxic, nous prendrons les incorporations moyennes de jetons de la dernière couche BERT (nous utilisons le pooling moyen masqué). Pour la tâche NER, nous utiliserons des incorporations de jetons provenant de la sortie de la 8ème couche d'encodeur. Lors de l'enseignement des représentations au niveau de la phrase, les intégrations pour les problèmes au niveau des jetons sont mieux extraites des couches intermédiaires du modèle.
Cela ressemble à ceci :

Architecture du modèle multitâche
Code pour assembler le modèle :
5. Validation des résultats
Pour valider le modèle de vectorisation de phrases, nous utilisons les jeux de données STS 2012-2016 et SICK 2014 .
Comme SNLI, cet ensemble de données contient des paires de phrases. Vectorisons-les avec un modèle utilisant un modèle et estimons la similarité entre les phrases en calculant la proximité en cosinus entre leurs vecteurs. En tant que métrique, nous calculerons la corrélation de rang avec les étiquettes de l'ensemble de données.
Code de rappel contenant cette logique :
https://gist.githubusercontent.com/gaphex/f2d2e1a9c849ba9d69a3014da705968f/raw/8ac26c3b236979625a906591dd594b9fd8640483/pearsonr_callback.py .
La tâche de déterminer la toxicité des commentaires sera testée par rapport à la métrique AUC. Le partitionnement des données est stratifié par rapport à la distribution des classes.
https://gist.github.com/Ab1992ao/873227b0834ebe43c95b4b5fe029eb95 .
La qualité du balisage NER sera évaluée par deux métriques - la précision et la mesure F1.
https://gist.github.com/Ab1992ao/e3ea080d36d2bf2d0c1ddc17aa4b9e99 .
6. Processus d'apprentissage
Nous sommes dans la dernière ligne droite. Nous avons maintenant : les données, le modèle et le pipeline de validation. Passons aux hyperparamètres et aux ressources d'apprentissage.
Selon les classiques, nous avons à notre disposition Colab avec accélérateur vidéo NVIDIA K80 (12 Go) / T80 (16 Go) - en fonction de votre activité dans cet environnement. Pour que l'ensemble de notre travail d'art multitâche puisse tenir en mémoire, il est important de choisir la bonne longueur maximale de la séquence traitée (seq_len) et, bien sûr, la taille du lot.
Dans cette expérience, nous nous limiterons à nouveau à 24 tokens pour la tâche de phrase, ce qui sera suffisant pour encoder la plupart des données utilisées dans l'apprentissage. Pour sentiment et ner-task, utilisez la même longueur de séquence.
Une augmentation de la taille du lot a un effet extrêmement positif sur la convergence du modèle - nous choisirons le maximum qui tiendra dans la mémoire de notre GPU.
En tant qu'optimiseur, nous utiliserons le bon vieux Adam avec un faible taux d'apprentissage . Nous allons entraîner le modèle avant la convergence, 25 époques devraient suffire.
Paramètres d'entraînement :
- taille du lot = 96/72 pour la base BERT (16 Go de mémoire ou 12 Go, respectivement) ;
- max_seq_len = 24 ;
- Optimiseur Adam ;
- Taux d'apprentissage ~ 2e-6;
- Métriques - [SpearmanR, F1, AUC] ;
- Nombre d'époques ~ 25.
Comparons les métriques des adaptateurs formés au-dessus des anciennes et des nouvelles versions du modèle SBERT.

Comme vous pouvez le voir, grâce à une formation supplémentaire multitâche, nous avons réussi à augmenter considérablement la qualité des tâches supplémentaires NER et TOX. Il est important que cela n'endommage pas la fonctionnalité principale du modèle - les métriques des ensembles de données STS et SICK sont restées au même niveau.
7. Possibilités d'amélioration
Augmentation
Dans le cadre de notre travail, nous utilisons des manipulations supplémentaires qui permettent d'obtenir des modèles plus précis et plus stables.
Lors de la génération par lots, nous appliquons un certain nombre d'augmentations, parmi lesquelles on peut distinguer : au niveau des lettres, au niveau des mots, changement de casse et suppression de ponctuation.
Au niveau des lettres, il s'agit de :
1) suppression de « prvet » ;
2) répéter « salutations » ;
3) permutation de deux symboles adjacents "Prievt" ;
4) remplacement d'une touche de fermeture sur le clavier "bienvenue" ;
5) remplacement par une lettre "bonjour" phonétiquement proche.
Au niveau des mots, il s'agit de :
1) échanger deux mots ou plus ;
2) insertion des mots de parasites - "Eh bien, c'est la même chose, pour ainsi dire."
Afin de rendre le modèle plus résistant aux changements de casse et de ponctuation, la ponctuation peut être supprimée dans certains exemples. Pour un jeton aléatoire, le registre peut être modifié.
Les augmentations liées au changement de mots et de symboles sont appliquées pour 3% du lot, et avec ponctuation et majuscule - pour 30%.
8. Résultats et conclusions
Dans cet article, nous nous sommes familiarisés avec le concept de Multitask Leaning et avons appliqué ces connaissances pour améliorer les représentations vectorielles du modèle de langage.
En utilisant ces méthodes, nous avons amélioré le modèle NLU pour le multitâche SBERT en langue russe et l'avons publié . Nous avons en outre entraîné cette version du modèle pour résoudre les problèmes de NER, l'analyse des sentiments et l'analyse de la toxicité.
Nous avons mesuré les métriques des deux versions du modèle SBERT sur le benchmark des modèles de langue russe RussianGLUE . Bien que les tâches RuGLUE n'aient pas participé au processus de recyclage multitâche, les métriques de la deuxième version du modèle ont légèrement augmenté. Enseigner le modèle à un problème a élargi ses horizons et amélioré la qualité des autres.

Nous prévoyons de développer davantage les modèles de langage naturel SBERT. Parmi les directions, on peut distinguer : l' accélération et la distillation , l' amélioration de l'architecture de base et l'ajout de nouvelles tâches. Nous en parlerons dans les articles suivants. Si vous êtes intéressé par les technologies NLP et que vous souhaitez les implémenter dans de nouveaux produits pour un large public, venez nous voir pour un entretien .
Nous vous souhaitons le meilleur dans vos recherches !
Merci pour votre aide dans la préparation du matériel pour cet article. Andriljo et Ibragim_bad...