À la fin de l'article, nous partagerons avec vous une liste des matériaux les plus intéressants sur ce sujet.

Nouvelle approche
L'apprentissage par renforcement multi-agents est un domaine de recherche en pleine croissance et riche. Néanmoins, l'utilisation constante d'algorithmes mono-agent dans des contextes multi-agents nous met dans une position difficile. L'apprentissage est compliqué pour de nombreuses raisons, notamment à cause:
- Instabilité entre agents indépendants;
- Croissance exponentielle des espaces d'actions et d'états.
Les chercheurs ont trouvé de nombreuses façons de réduire les effets de ces facteurs. La plupart de ces méthodes relèvent de la notion de «planification centralisée avec exécution décentralisée».
Planification centrale
Chaque agent a un accès direct aux observations locales. Ces observations peuvent être très diverses: images de l'environnement, positions par rapport à certains repères ou même positions par rapport à d'autres agents. De plus, lors de la formation, tous les agents sont gérés par un module central ou critique.
Malgré le fait que chaque agent de formation ne dispose que d'informations locales et de politiques locales, il existe une entité qui surveille l'ensemble du système d'agents et leur indique comment mettre à jour les politiques. Ainsi, l'effet de la non-stationnarité est réduit. Tous les agents sont formés à l'aide d'un module avec des informations globales.
Exécution décentralisée
Pendant le test, le module central est supprimé, mais les agents avec leurs politiques et leurs données locales restent. Cela réduit les dommages causés par l'augmentation des espaces d'actions et d'états, puisque les politiques agrégées ne sont jamais étudiées. Au lieu de cela, nous espérons qu'il y a suffisamment d'informations dans le module central pour gérer la politique d'apprentissage locale afin qu'elle soit optimale pour l'ensemble du système dès qu'il est temps de tester.
Openai
Des chercheurs d'OpenAI, d'UC Berkeley et de l'Université McGill ont présenté une nouvelle approche des paramètres multi-agents en utilisant le Gradient Policy Déterministe profond multi-agents . Inspirée de son homologue mono-agent du DDPG, cette approche utilise une formation «acteur-critique» et donne des résultats très prometteurs.
Architecture
Cet article suppose que vous êtes familiarisé avec la version à agent unique de MADDPG: Deep Deterministic Policy Gradients ou DDPG. Pour vous rafraîchir la mémoire, vous pouvez lire l'excellent article de Chris Yoon .
Chaque agent dispose d'un espace d'observation et d'un espace d'action continue. Chaque agent comprend également trois composants:
- , ;
- ;
- , - Q-.
Alors que le critique examine les valeurs Q conjointes d'une fonction au fil du temps, il envoie des approximations appropriées des valeurs Q à l'acteur pour faciliter l'apprentissage. Nous examinerons de plus près cette interaction dans la section suivante.
N'oubliez pas que le critique peut être un réseau partagé entre tous les N agents. En d'autres termes, au lieu de former N réseaux qui évaluent la même valeur, il suffit de former un réseau et de l'utiliser pour aider à former tous les autres agents. Il en est de même pour les réseaux d'acteurs si les agents sont homogènes.
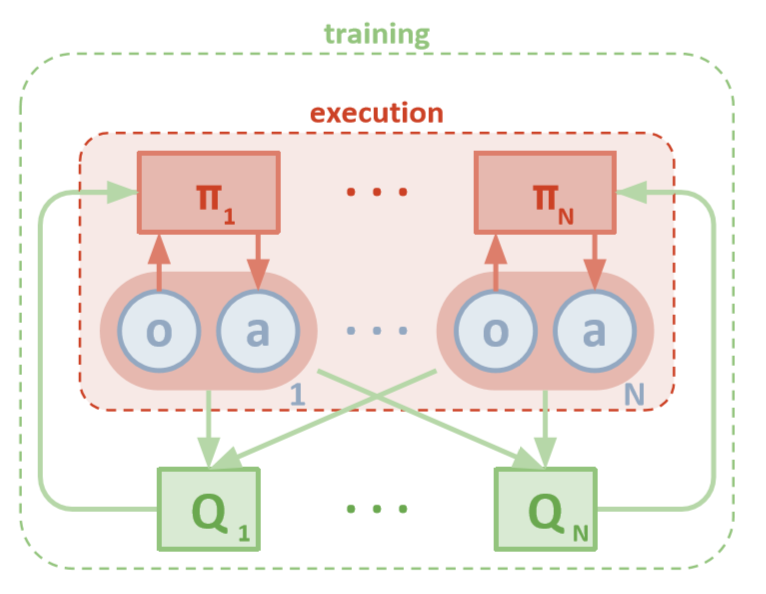
Architecture MADDPG (Lowe, 2018)
Formation
Premièrement, MADDPG utilise la relecture d'expérience pour un apprentissage efficace hors politique . À chaque intervalle de temps, l'agent stocke la transition suivante:
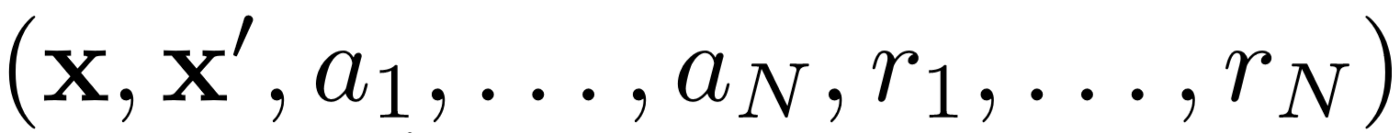
où nous stockons l'état conjoint, l'état conjoint suivant, l'action conjointe et chacune des récompenses reçues par l'agent. Nous récupérons ensuite un ensemble de ces transitions à partir de la relecture de l' expérience pour former notre agent.
Mises à jour critiques
Pour mettre à jour le critique central de l'agent, nous utilisons un bug TD lookahead:
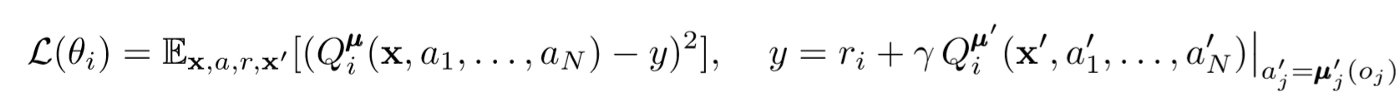
Où μ est un acteur. N'oubliez pas qu'il s'agit d'un critique central, c'est-à-dire qu'il utilise des informations générales pour mettre à jour ses paramètres. L'idée de base est que si vous connaissez les actions que tous les agents entreprennent, l'environnement sera stationnaire même si la politique change.
Faites attention au côté droit de l'expression avec le calcul de la valeur Q. Bien que nous ne sauvegardions jamais notre prochaine synergie, nous utilisons chaque acteur cible de l'agent pour calculer l'action suivante lors de la mise à jour afin de rendre l'apprentissage plus stable. Les paramètres de l'acteur cible sont périodiquement mis à jour pour correspondre à ceux de l'acteur de l'agent.
Mises à jour des acteurs
Semblable au DDPG à agent unique, nous utilisons un gradient de politique déterministe pour mettre à jour chaque paramètre d'un acteur agent.
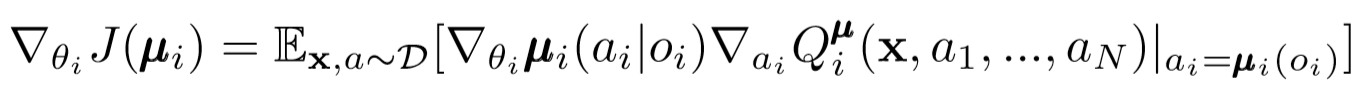
Où μ est un acteur agent.
Allons un peu plus loin dans cette expression de renouveau. Nous prenons le gradient par rapport aux paramètres de l'acteur avec l'aide d'un critique central. La chose la plus importante à faire attention est que même si l'acteur n'a que des observations et des actions locales, pendant la formation, nous utilisons un critique central pour obtenir des informations sur l'optimalité de ses actions dans l'ensemble du système. Cela réduit l'effet de la non-stationnarité et la politique d'apprentissage reste dans l'espace d'état inférieur!
Conclusions d'hommes politiques et d'ensembles d'hommes politiques
Nous pouvons faire un pas de plus sur la question de la décentralisation. Dans les mises à jour précédentes, nous supposions que chaque agent reconnaîtrait automatiquement les actions des autres agents. Mais MADDPG propose de tirer des conclusions des politiques des autres agents afin de rendre la formation encore plus indépendante. En fait, chaque agent ajoutera N-1 réseaux pour évaluer la validité de la politique de tous les autres agents. Nous utilisons un réseau probabiliste pour maximiser la probabilité logarithmique de déduire l'action observée d'un autre agent.
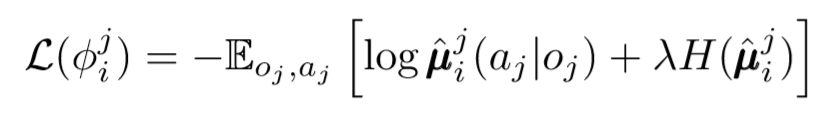
Où nous voyons la fonction de perte pour le ième agent, évaluer les politiques du jième agent à l'aide du régulariseur d'entropie. En conséquence, notre valeur Q cible devient légèrement différente lorsque nous remplaçons les actions de l'agent par nos actions prévisibles!
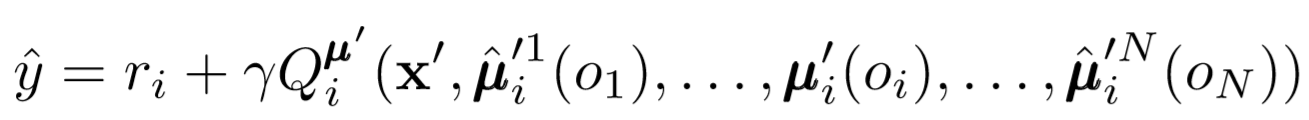
Alors que s'est-il passé à la fin? Nous avons supprimé l'hypothèse selon laquelle les agents connaissent les politiques de chacun. Au lieu de cela, nous essayons de former des agents à prédire les politiques des autres agents sur la base d'une série d'observations. En fait, chaque agent apprend indépendamment, recevant des informations globales de l'environnement au lieu de simplement les avoir à portée de main par défaut.
Ensembles politiques
Il y a un gros problème avec l'approche ci-dessus. Dans de nombreux contextes multi-agents, en particulier ceux de la concurrence, les agents peuvent créer des stratégies qui peuvent se recycler sur le comportement d'autres agents. Cela rendra la politique fragile, instable et généralement sous-optimale. Pour compenser cette lacune, MADDPG forme une collection de sous-politique K pour chaque agent. À chaque pas de temps, l'agent sélectionne au hasard l'une des sous-politiques pour sélectionner l'action. Et puis l'exécute.
Le gradient de la politique change un peu. Nous prenons la moyenne de K sous-politiques, utilisons la linéarité de l'espérance et distribuons les mises à jour à l'aide de la fonction Q-value.
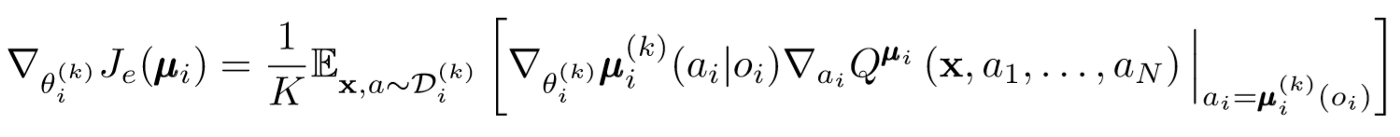
Prenons du recul
Voici à quoi ressemble l'ensemble de l'algorithme en termes généraux. Nous devons maintenant revenir en arrière et réaliser ce que nous avons fait exactement et comprendre intuitivement pourquoi cela fonctionne. En gros, nous avons fait ce qui suit:
- Des acteurs ont été identifiés pour les agents qui n'utilisent que des observations locales. De cette façon, on peut prendre le contrôle de l'effet négatif de l'augmentation exponentielle des espaces d'états et d'actions.
- Identifié un critique central pour chaque agent qui utilise des informations partagées. Nous avons donc pu réduire l'influence de la non-stationnarité et aidé l'acteur à devenir optimal pour le système global.
- Définition de réseaux d'inférence de politique pour évaluer les politiques d'autres agents. De cette manière, nous avons pu limiter l'interdépendance des agents et éliminer le besoin pour les agents d'avoir une information parfaite.
- Les ensembles de politiques ont été identifiés pour réduire l'effet et la possibilité de recyclage sur les politiques d'autres agents.
Chaque composant de l'algorithme a un objectif spécifique et distinct. Ce qui rend l'algorithme MADDPG puissant est le suivant: ses composants sont spécifiquement conçus pour surmonter les principaux obstacles auxquels les systèmes multi-agents sont généralement confrontés. Ensuite, nous parlerons des performances de l'algorithme.
résultats
MADDPG a été testé dans de nombreux environnements. Une revue complète de son travail se trouve dans l'article [1]. Ici, nous ne parlerons que du problème de la communication coopérative.
Présentation de l'environnement
Il y a deux agents: l'orateur et l'auditeur. À chaque itération, l'auditeur reçoit un point coloré sur la carte pour se déplacer et reçoit une récompense proportionnelle à la distance jusqu'à ce point. Mais voici le hic: l'auditeur ne connaît que sa position et la couleur des points de terminaison. Il ne sait pas vers quel point il doit se diriger. Cependant, le locuteur connaît la couleur du point correct pour l'itération en cours. En conséquence, les deux agents doivent interagir pour accomplir cette tâche.
Comparaison
Pour résoudre ce problème, l'article oppose MADDPG et les méthodes modernes à agent unique. Des améliorations significatives sont observées avec l'utilisation de MADDPG.
Il a également été démontré que les inférences tirées des politiques, même si les politiciens n'étaient pas formés idéalement, permettaient d'obtenir les mêmes résultats qui peuvent être obtenus en utilisant une véritable observation. De plus, il n'y a pas eu de ralentissement significatif de la convergence.
Enfin, les ensembles de politiques ont donné des résultats très prometteurs. L'article [1] explore l'impact des ensembles dans un environnement concurrentiel et démontre une amélioration significative des performances par rapport aux agents ayant une seule politique.
Conclusion
C'est tout. Ici, nous avons examiné une nouvelle approche de l'apprentissage par renforcement multi-agents. Bien sûr, il existe un nombre infini de méthodes liées à MARL, mais MADDPG fournit une base solide pour des méthodes qui résolvent les problèmes les plus globaux des systèmes multi-agents.
Sources
[1] R. Lowe, Y. Wu, A. Tamar, J. Harb, P. Abbeel, I. Mordatch, Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments (2018).
Liste d'articles utiles
- 3 pièges dans lesquels tombent les Data Scientists débutants
- Algorithme AdaBoost
- Comment s'est déroulée l'année 2019 dans le domaine des mathématiques et de l'informatique?
- L'apprentissage automatique face à un problème mathématique non résolu
- Comprendre le théorème de Bayes
- Trouver les contours du visage en une milliseconde à l'aide d'un ensemble d'arbres de régression
, , , . .