
Dans le travail quotidien sur Linux / Unix, nous utilisons de nombreux outils de ligne de commande - par exemple, du pour surveiller l'utilisation du disque et les ressources système. Certains de ces outils existent depuis longtemps. Par exemple, top est apparu en 1984 et la première sortie de du remonte à 1971.
Au fil des années, ces outils ont été modernisés et portés sur différents systèmes, mais en général ils ne sont pas allés loin de leurs premières versions, leur apparence et leur convivialité n'ont pas beaucoup changé non plus.
Ce sont d'excellents outils dont de nombreux administrateurs système ont besoin. Cependant, la communauté a développé des outils alternatifs qui offrent des avantages supplémentaires. Certains d'entre eux ont juste une interface moderne et belle, tandis que d'autres améliorent considérablement la convivialité. Dans cette traduction, nous discuterons de cinq alternatives aux outils de ligne de commande Linux standard.
1.ncdu vs du
L'utilisation du disque NCurses ( ncdu ) est similaire à du, mais avec une interface interactive basée sur la bibliothèque curses. ncdu affiche la structure de répertoires qui occupe la plupart de votre espace disque.
ncdu analyse le disque et affiche ensuite les résultats triés par les répertoires ou fichiers les plus couramment utilisés, par exemple:
ncdu 1.14.2 ~ Use the arrow keys to navigate, press ? for help
--- /home/rgerardi ------------------------------------------------------------
96.7 GiB [##########] /libvirt
33.9 GiB [### ] /.crc
7.0 GiB [ ] /Projects
. 4.7 GiB [ ] /Downloads
. 3.9 GiB [ ] /.local
2.5 GiB [ ] /.minishift
2.4 GiB [ ] /.vagrant.d
. 1.9 GiB [ ] /.config
. 1.8 GiB [ ] /.cache
1.7 GiB [ ] /Videos
1.1 GiB [ ] /go
692.6 MiB [ ] /Documents
. 591.5 MiB [ ] /tmp
139.2 MiB [ ] /.var
104.4 MiB [ ] /.oh-my-zsh
82.0 MiB [ ] /scripts
55.8 MiB [ ] /.mozilla
54.6 MiB [ ] /.kube
41.8 MiB [ ] /.vim
31.5 MiB [ ] /.ansible
31.3 MiB [ ] /.gem
26.5 MiB [ ] /.VIM_UNDO_FILES
15.3 MiB [ ] /Personal
2.6 MiB [ ] .ansible_module_generated
1.4 MiB [ ] /backgrounds
944.0 KiB [ ] /Pictures
644.0 KiB [ ] .zsh_history
536.0 KiB [ ] /.ansible_async
Total disk usage: 159.4 GiB Apparent size: 280.8 GiB Items: 561540Vous pouvez parcourir les entrées à l'aide des touches fléchées. Si vous appuyez sur Entrée, ncdu affichera le contenu du répertoire sélectionné:
--- /home/rgerardi/libvirt ----------------------------------------------------
/..
91.3 GiB [##########] /images
5.3 GiB [ ] /mediaVous pouvez utiliser cet outil pour, par exemple, déterminer quels fichiers occupent le plus d'espace disque. Vous pouvez retourner au répertoire précédent en appuyant sur la touche fléchée gauche. Avec ncdu, vous pouvez supprimer des fichiers en appuyant sur d. Avant de supprimer, il demande une confirmation. Si vous souhaitez désactiver la fonction de suppression pour éviter la perte accidentelle de fichiers précieux, utilisez l'option -r pour activer l'accès en lecture seule: ncdu -r.
ncdu est disponible pour de nombreuses plateformes et distributions Linux. Par exemple, vous pouvez utiliser dnf pour l'installer sur Fedora directement à partir des référentiels officiels:
$ sudo dnf install ncdu2.htop vs top
Htop est un visualiseur de processus interactif, similaire à top, mais offre une expérience utilisateur agréable dès le départ. Par défaut, htop affiche les mêmes informations que top, mais de manière plus visuelle et colorée.
Par défaut, htop ressemble à ceci:
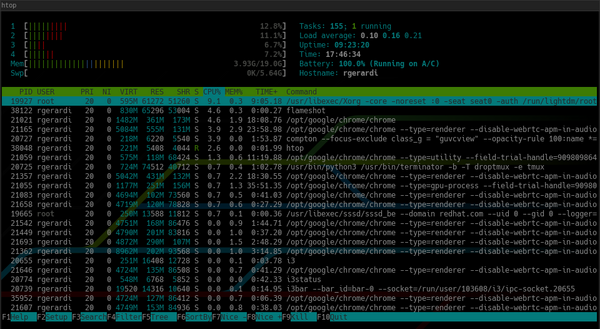
Contrairement au haut:
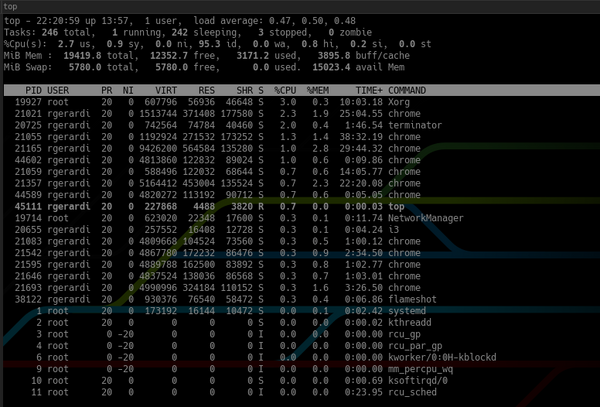
De plus, en haut, htop affiche une vue d'ensemble du système et en bas, un panneau pour exécuter des commandes à l'aide des touches de fonction. Vous pouvez le personnaliser en appuyant sur F2 pour ouvrir l'écran de personnalisation. Dans les paramètres, vous pouvez modifier les couleurs, ajouter ou supprimer des mesures ou modifier les options d'affichage du panneau de vue d'ensemble.
Bien qu'en modifiant les paramètres des dernières versions supérieures, vous puissiez également obtenir une convivialité similaire, htop fournit des configurations par défaut pratiques, ce qui le rend plus pratique et facile à utiliser.
3.tldr vs homme
L'outil de ligne de commande tldr affiche des informations d'aide sur les commandes simplifiées, principalement des exemples. Il a été développé par la communauté du projet tldr pages .
Il est à noter que tldr ne remplace pas l'homme. C'est toujours l'outil canonique et le plus complet pour afficher des pages de manuel. Cependant, dans certains cas, l'homme est redondant. Lorsque vous n'avez pas besoin d'informations complètes sur une équipe, vous essayez simplement de vous souvenir des principales options pour son utilisation. Par exemple, la page de manuel de curl compte près de 3000 lignes. La page tldr pour curl fait 40 lignes. Son fragment ressemble à ceci:
$ tldr curl
# curl
Transfers data from or to a server.
Supports most protocols, including HTTP, FTP, and POP3.
More information: <https://curl.haxx.se>.
- Download the contents of an URL to a file:
curl http://example.com -o filename
- Download a file, saving the output under the filename indicated by the URL:
curl -O http://example.com/filename
- Download a file, following [L]ocation redirects, and automatically [C]ontinuing (resuming) a previous file transfer:
curl -O -L -C - http://example.com/filename
- Send form-encoded data (POST request of type `application/x-www-form-urlencoded`):
curl -d 'name=bob' http://example.com/form
- Send a request with an extra header, using a custom HTTP method:
curl -H 'X-My-Header: 123' -X PUT http://example.com
- Send data in JSON format, specifying the appropriate content-type header:
curl -d '{"name":"bob"}' -H 'Content-Type: application/json' http://example.com/users/1234
... TRUNCATED OUTPUTTLDR signifie «trop long; n'a pas lu »: c'est-à-dire que certains textes ont été ignorés en raison de leur verbosité excessive. Le nom convient à cet outil, car les pages de manuel, bien qu'utiles, sont parfois trop longues.
Pour Fedora, tldr a été écrit en Python. Vous pouvez l'installer à l'aide du gestionnaire dnf. Habituellement, l'outil nécessite un accès Internet pour fonctionner. Mais le client Python de Fedora vous permet de charger et de mettre en cache ces pages pour un accès hors ligne.
4.jq contre sed / grep
jq est un processeur JSON en ligne de commande. Il est similaire à sed ou grep, mais est spécialement conçu pour fonctionner avec des données JSON. Si vous êtes un développeur ou un administrateur système qui utilise JSON dans les tâches quotidiennes, cet outil est fait pour vous.
Le principal avantage de jq par rapport aux outils de traitement de texte standard tels que grep et sed est qu'il comprend la structure des données JSON, vous permettant de créer des requêtes complexes en une seule instruction.
Par exemple, vous essayez de trouver les noms des conteneurs dans ce fichier JSON:
{
"apiVersion": "v1",
"kind": "Pod",
"metadata": {
"labels": {
"app": "myapp"
},
"name": "myapp",
"namespace": "project1"
},
"spec": {
"containers": [
{
"command": [
"sleep",
"3000"
],
"image": "busybox",
"imagePullPolicy": "IfNotPresent",
"name": "busybox"
},
{
"name": "nginx",
"image": "nginx",
"resources": {},
"imagePullPolicy": "IfNotPresent"
}
],
"restartPolicy": "Never"
}
}Exécutez grep pour trouver le nom de la chaîne:
$ grep name k8s-pod.json
"name": "myapp",
"namespace": "project1"
"name": "busybox"
"name": "nginx",grep a renvoyé toutes les lignes contenant le nom du mot. Vous pouvez ajouter quelques paramètres supplémentaires à grep pour le restreindre, et avec certaines manipulations d'expressions régulières, trouver les noms des conteneurs.
Pour obtenir le même résultat avec jq, écrivez simplement:
$ jq '.spec.containers[].name' k8s-pod.json
"busybox"
"nginx"Cette commande vous donnera les noms des deux conteneurs. Si vous recherchez uniquement le nom du deuxième conteneur, ajoutez l'index de l'élément de tableau à l'expression:
$ jq '.spec.containers[1].name' k8s-pod.json
"nginx"Étant donné que jq connaît la structure des données, il donne les mêmes résultats, même si le format de fichier change légèrement. grep et sed peuvent ne pas fonctionner correctement dans ce cas.
Jq a de nombreuses fonctions, mais un autre article est nécessaire pour les décrire. Pour plus d'informations, consultez la page du projet jq ou tldr.
5.fd vs trouver
fd est une alternative légère à trouver. Fd n'est pas destiné à le remplacer entièrement: il utilise par défaut les paramètres les plus courants qui définissent l'approche globale de l'utilisation des fichiers.
Par exemple, lors de la recherche de fichiers dans un répertoire de référentiel Git, fd exclut automatiquement les fichiers et sous-répertoires cachés, y compris le répertoire .git, et ignore les modèles du fichier .gitignore. Dans l'ensemble, il accélère les recherches en fournissant des résultats plus pertinents dès le premier essai.
Par défaut, fd effectue des recherches non sensibles à la casse dans le répertoire courant avec une sortie couleur. La même recherche à l'aide de la commande find nécessite la saisie de paramètres supplémentaires sur la ligne de commande. Par exemple, pour rechercher tous les fichiers .md (ou .MD) dans le répertoire en cours, vous devez écrire la commande find:
$ find . -iname "*.md"Pour fd, cela ressemble à ceci:
$ fd .mdMais dans certains cas, fd nécessite également des paramètres supplémentaires: par exemple, si vous souhaitez inclure des fichiers et des répertoires cachés, vous devez utiliser l'option -H, bien que cela ne soit généralement pas nécessaire lors de la recherche.
fd est disponible pour de nombreuses distributions Linux. Sur Fedora, vous pouvez l'installer comme ceci:
$ sudo dnf install fd-findIl n’est pas nécessaire d’abandonner quelque chose
Utilisez-vous les nouveaux outils de ligne de commande Linux? Ou vous asseoir exclusivement sur l'ancien? Mais vous avez probablement un combo, non? Veuillez partager votre expérience dans les commentaires.
La publicité
Beaucoup de nos clients ont déjà apprécié les avantages des serveurs épiques !
Ce sont des serveurs virtuels avec des processeurs AMD EPYC , une fréquence centrale de processeur jusqu'à 3,4 GHz. La configuration maximale vous permettra de sortir au maximum - 128 cœurs de processeur, 512 Go de RAM, 4000 Go de NVMe. Dépêchez-vous de commander!
