Dans cet article, je veux parler de la façon dont notre équipe a décidé d'appliquer l'approche CQRS & Event Sourcing dans un projet qui est un site d'enchères en ligne. Et aussi sur ce qui en est sorti, quelles conclusions peut-on tirer de notre expérience et sur quel râteau il est important de ne pas marcher pour ceux qui passent par CQRS & ES.

Prélude
Pour commencer, un peu d'histoire et de formation en affaires. Un client est venu nous voir avec une plateforme pour organiser des enchères dites chronométrées, qui était déjà en production et sur laquelle un certain nombre de retours ont été recueillis. Le client souhaitait que nous lui créions une plate-forme d'enchères en direct.
Maintenant un peu de terminologie. Une vente aux enchères se produit lorsque certains articles sont vendus - des lots, et des acheteurs (enchérisseurs) placent des offres. Le propriétaire du lot est l'acheteur qui a proposé l'offre la plus élevée. L'enchère chronométrée est lorsque chaque lot a une heure de clôture prédéterminée. Les acheteurs placent des paris, à un moment donné, le lot est fermé. Similaire à ebay.
La plateforme chronométrée a été réalisée de manière classique, en utilisant CRUD. Les lots ont été fermés par une application distincte, commençant selon un calendrier. Tout cela n'a pas fonctionné de manière très fiable: certains paris ont été perdus, certains ont été faits comme si au nom du mauvais acheteur, les lots n'étaient pas fermés ou fermés plusieurs fois.
L'enchère en direct est l'occasion de participer à une véritable vente aux enchères hors ligne à distance via Internet. Il y a une salle (dans notre terminologie interne - "salle"), elle contient l'hôte de la vente aux enchères avec un marteau et le public, et juste à côté de l'ordinateur portable se trouve le soi-disant commis, qui, en appuyant sur les boutons de son interface, diffuse le déroulement de la vente aux enchères sur Internet, et le connecté Au moment de l'enchère, les acheteurs voient les offres qui sont placées hors ligne et peuvent placer leurs offres.
Les deux plates-formes fonctionnent en principe en temps réel, mais si dans le cas du chronométré tous les acheteurs sont dans une position égale, dans le cas du live, il est extrêmement important que les acheteurs en ligne puissent concurrencer avec succès ceux de la salle. Autrement dit, le système doit être très rapide et fiable. La triste expérience de la plate-forme chronométrée nous a dit sans équivoque que le CRUD classique ne nous convenait pas.
Nous n'avions pas notre propre expérience de travail avec CQRS & ES, nous avons donc consulté des collègues qui l'avaient (nous avons une grande entreprise), leur avons présenté nos réalités commerciales et sommes parvenus à la conclusion que CQRS & ES devrait nous convenir.
Quelles sont les autres spécificités des enchères en ligne:
- — . , « », , . — , 5 . .
- , , .
- — - , , — .
- , .
- La solution doit être évolutive - plusieurs enchères peuvent être organisées simultanément.
Un bref aperçu de l'approche CQRS & ES
Je ne m'attarderai pas sur la prise en compte de l'approche CQRS & ES, il existe des supports à ce sujet sur Internet et en particulier sur Habré (par exemple, ici: Introduction au CQRS + Event Sourcing ). Cependant, je vous rappellerai brièvement les principaux points:
- Le plus important dans le sourcing d'événements: le système ne stocke pas les données, mais l'historique de leur changement, c'est-à-dire des événements. L'état actuel du système est obtenu par application séquentielle des événements.
- Le modèle de domaine est divisé en entités appelées agrégats. L'unité a une version. Les événements sont appliqués aux agrégats. L'application d'un événement à un agrégat incrémente sa version.
- write-. , .
- . . , , . «» . .
- , , - ( N- ) . «» . , .
- - , , , , write-.
- write-, read-, , . read- . Read- .
- , — Command Query Responsibility Segregation (CQRS): , , write-; , , read-.

. .
Afin de gagner du temps, ainsi qu'en raison du manque d'expérience spécifique, nous avons décidé que nous devions utiliser une sorte de cadre pour CQRS & ES.
En général, notre pile technologique est Microsoft, c'est-à-dire .NET et C #. Base de données - Microsoft SQL Server. Tout est hébergé dans Azure. Une plateforme chronométrée a été réalisée sur cette pile, il était logique d'en faire une plateforme live.
À cette époque, si je me souviens bien maintenant, Chinchilla était presque la seule option qui nous convenait en termes de pile technologique. Alors on l'a emmenée.
Pourquoi avons-nous besoin d'un cadre CQRS & ES? Il peut résoudre «hors de la boîte» des problèmes et prendre en charge des aspects de mise en œuvre tels que:
- Agréger les entités, commandes, événements, gestion des versions agrégées, réhydratation, mécanisme de capture instantanée.
- Interfaces pour travailler avec différents SGBD. Sauvegarde / chargement des événements et des instantanés des agrégats vers / depuis la base d'écriture (magasin d'événements).
- Interfaces pour travailler avec les files d'attente - envoi de commandes et d'événements aux files d'attente appropriées, lecture des commandes et événements de la file d'attente.
- Interface pour travailler avec des Websockets.
Ainsi, en tenant compte de l'utilisation de Chinchilla, nous avons ajouté à notre stack:
- Azure Service Bus en tant que bus de commande et d'événement, Chinchilla le prend en charge dès le départ;
- Les bases de données d'écriture et de lecture sont Microsoft SQL Server, c'est-à-dire qu'elles sont toutes deux des bases de données SQL. Je ne dirai pas que c'est le résultat d'un choix conscient, mais plutôt pour des raisons historiques.
Oui, le frontend est fait en Angular.
Comme je l'ai déjà dit, l'une des exigences du système est que les utilisateurs apprennent le plus rapidement possible les résultats de leurs actions et les actions des autres utilisateurs - cela s'applique à la fois aux clients et au commis. Par conséquent, nous utilisons SignalR et Websockets pour mettre à jour rapidement les données sur le frontend. Chinchilla prend en charge l'intégration SignalR.
Sélection des unités
L'une des premières choses à faire lors de la mise en œuvre de l'approche CQRS & ES est de déterminer comment le modèle de domaine sera divisé en agrégats.
Dans notre cas, le modèle de domaine se compose de plusieurs entités principales, quelque chose comme ceci:
public class Auction
{
public AuctionState State { get; private set; }
public Guid? CurrentLotId { get; private set; }
public List<Guid> Lots { get; }
}
public class Lot
{
public Guid? AuctionId { get; private set; }
public LotState State { get; private set; }
public decimal NextBid { get; private set; }
public Stack<Bid> Bids { get; }
}
public class Bid
{
public decimal Amount { get; set; }
public Guid? BidderId { get; set; }
}
Nous avons obtenu deux agrégats: Enchère et Lot (avec enchères). En général, c'est logique, mais nous n'avons pas pris en compte une chose - le fait qu'avec une telle division, l'état du système était réparti sur deux unités, et dans certains cas, pour maintenir la cohérence, nous devons apporter des modifications aux deux unités et non à une. Par exemple, une enchère peut être suspendue. Si l'enchère est suspendue, vous ne pouvez pas enchérir sur le lot. Il serait possible de suspendre le lot lui-même, mais une enchère suspendue ne peut traiter aucune commande autre que "unpause".
Alternativement, un seul agrégat pourrait être fait, aux enchères, avec tous les lots et toutes les enchères à l'intérieur. Mais un tel objet sera assez difficile, car il peut y avoir jusqu'à plusieurs milliers de lots aux enchères et il peut y avoir plusieurs dizaines d'offres pour un lot. Pendant la durée de l'enchère, un tel agrégat aura un grand nombre de versions, et la réhydratation d'un tel agrégat (application séquentielle de tous les événements à l'agrégat), si aucun instantané des agrégats n'est fait, prendra un temps assez long. Ce qui est inacceptable pour notre situation. Si vous utilisez des instantanés (nous les utilisons), les instantanés eux-mêmes pèseront beaucoup.
D'autre part, pour vous assurer que les modifications sont appliquées à deux agrégats dans le cadre du traitement d'une seule action utilisateur, vous devez soit modifier les deux agrégats dans la même commande à l'aide d'une transaction, soit exécuter deux commandes dans la même transaction. Les deux sont, dans l'ensemble, une violation de l'architecture.
Ces circonstances doivent être prises en compte lors de la décomposition du modèle de domaine en agrégats.
A ce stade de l'évolution du projet, nous vivons avec deux unités, Enchères et Lot, et nous cassons l'architecture en changeant les deux unités au sein de certaines commandes.
Application d'une commande à une version spécifique d'un agrégat
Si plusieurs acheteurs placent une offre sur le même lot en même temps, c'est-à-dire qu'ils envoient une commande «placer une offre» au système, une seule des offres sera acceptée. Beaucoup est un agrégat, il a une version. Lors du traitement de la commande, des événements sont générés, chacun incrémentant la version de l'agrégat. Il y a deux façons de procéder:
- Envoyez une commande spécifiant à quelle version de l'agrégat nous voulons l'appliquer. Ensuite, le gestionnaire de commandes peut comparer immédiatement la version de la commande avec la version actuelle de l'unité et ne pas continuer si elle ne correspond pas.
- Ne spécifiez pas la version de l'unité dans la commande. Ensuite, l'agrégat est réhydraté avec une version, la logique métier correspondante est exécutée, des événements sont générés. Et ce n'est que lorsqu'ils sont enregistrés qu'une exécution peut apparaître qu'une telle version de l'unité existe déjà. Parce que quelqu'un d'autre l'a fait plus tôt.
Nous utilisons la deuxième option. Cela donne aux équipes une meilleure chance d'être exécutées. Parce que dans la partie de l'application qui envoie des commandes (dans notre cas, c'est le frontend), la version actuelle de l'agrégat avec une certaine probabilité sera en retard sur la version réelle sur le backend. Surtout dans des conditions où beaucoup de commandes sont envoyées et la version de l'unité change fréquemment.
Erreurs lors de l'exécution d'une commande à l'aide d'une file d'attente
Dans notre implémentation, fortement pilotée par Chinchilla, le gestionnaire de commandes lit les commandes à partir d'une file d'attente (Microsoft Azure Service Bus). Nous distinguons clairement les situations où une équipe échoue pour des raisons techniques (timeouts, erreurs de connexion à une file d'attente / base) et lorsque pour des raisons commerciales (une tentative de faire une offre sur un lot du même montant qui a déjà été accepté, etc.). Dans le premier cas, la tentative d'exécution de la commande est répétée jusqu'à ce que le nombre de répétitions spécifié dans les paramètres de file d'attente soit atteint, après quoi la commande est envoyée à la file d'attente de lettres mortes (une rubrique distincte pour les messages non traités dans Azure Service Bus). Dans le cas d'une exécution commerciale, l'équipe est envoyée immédiatement à la file d'attente des lettres mortes.
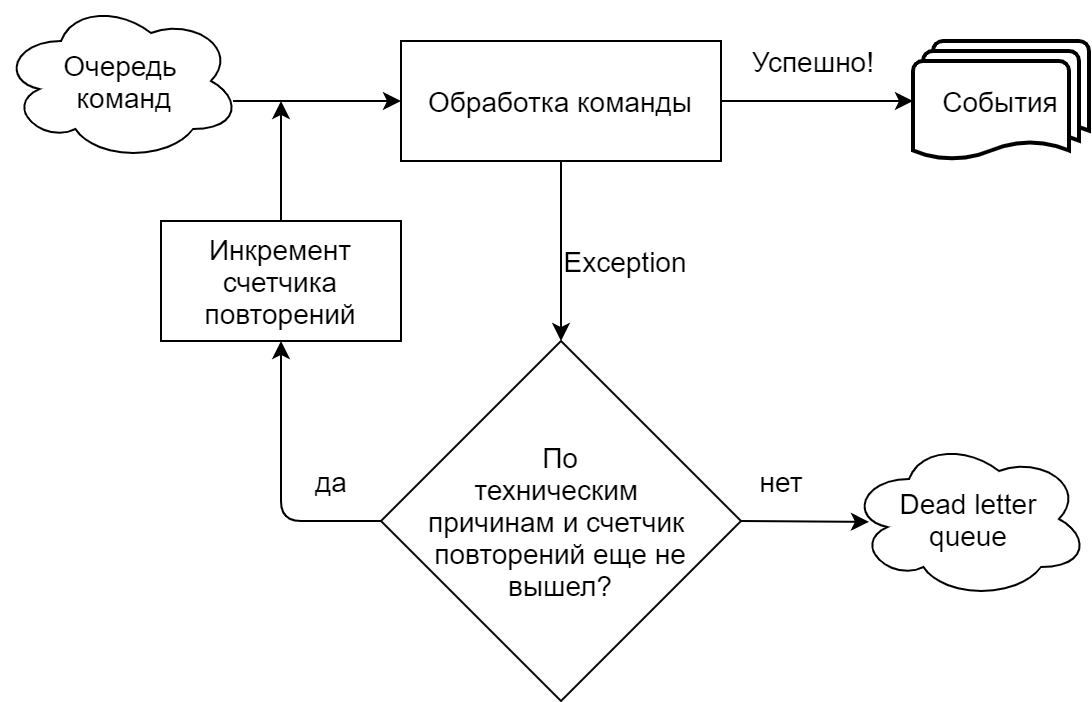
Erreurs lors de la gestion des événements à l'aide d'une file d'attente
Les événements générés à la suite de l'exécution de la commande, en fonction de l'implémentation, peuvent également être envoyés à la file d'attente et extraits de la file d'attente par les gestionnaires d'événements. Et lors de la gestion des événements, des erreurs se produisent également.
Cependant, contrairement à la situation avec une commande non exécutée, tout est pire ici - il peut arriver que la commande ait été exécutée et que les événements aient été écrits dans la base d'écriture, mais leur traitement par les gestionnaires a échoué. Et si l'un de ces gestionnaires met à jour la base de lecture, la base de lecture ne sera pas mise à jour. Autrement dit, il sera dans un état incohérent. En raison du mécanisme de relance de l'événement de lecture, la base de données est presque toujours mise à jour à la fin, mais la probabilité qu'après toutes les tentatives, elle reste défectueuse demeure.
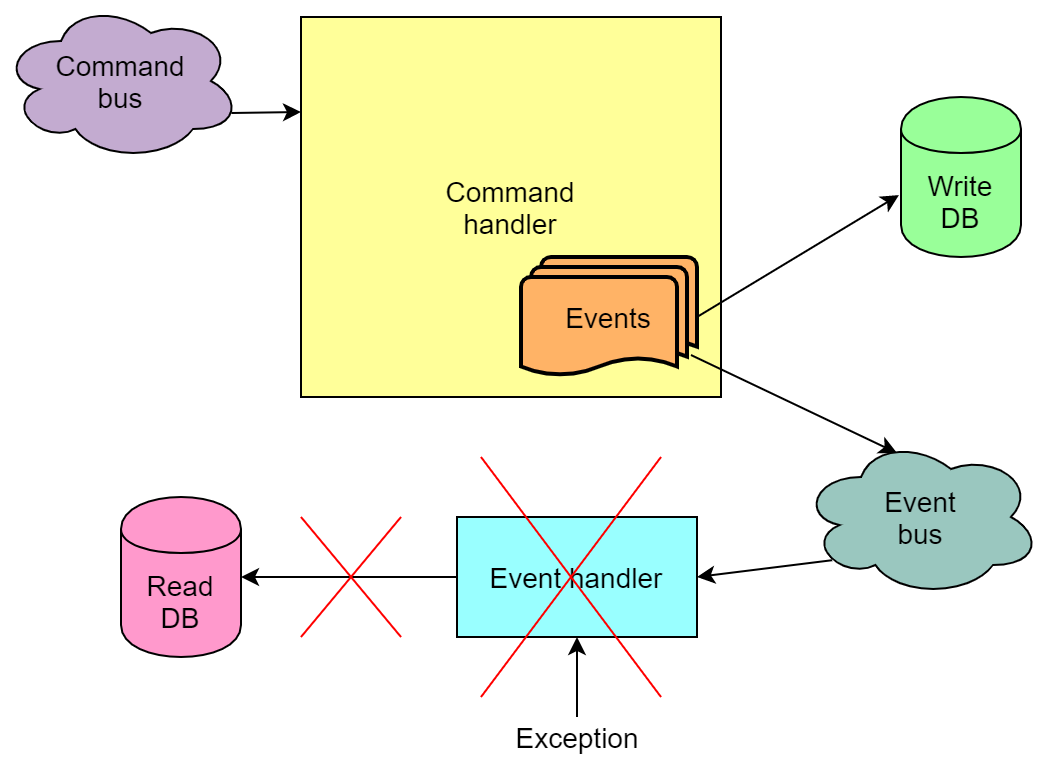
Nous avons rencontré ce problème à la maison. La raison, cependant, était en grande partie due au fait que nous avions une certaine logique métier dans le traitement des événements, qui, avec un flux intense de paris, a de bonnes chances d'échouer de temps en temps. Malheureusement, nous avons réalisé cela trop tard, il n'était pas possible de refaire l'implémentation métier rapidement et simplement.
Par conséquent, à titre de mesure temporaire, nous avons cessé d'utiliser Azure Service Bus pour transférer des événements de la partie écriture de l'application vers la partie lecture. Au lieu de cela, le soi-disant bus en mémoire est utilisé, ce qui vous permet de traiter la commande et les événements en une seule transaction et, en cas d'échec, de restaurer le tout.
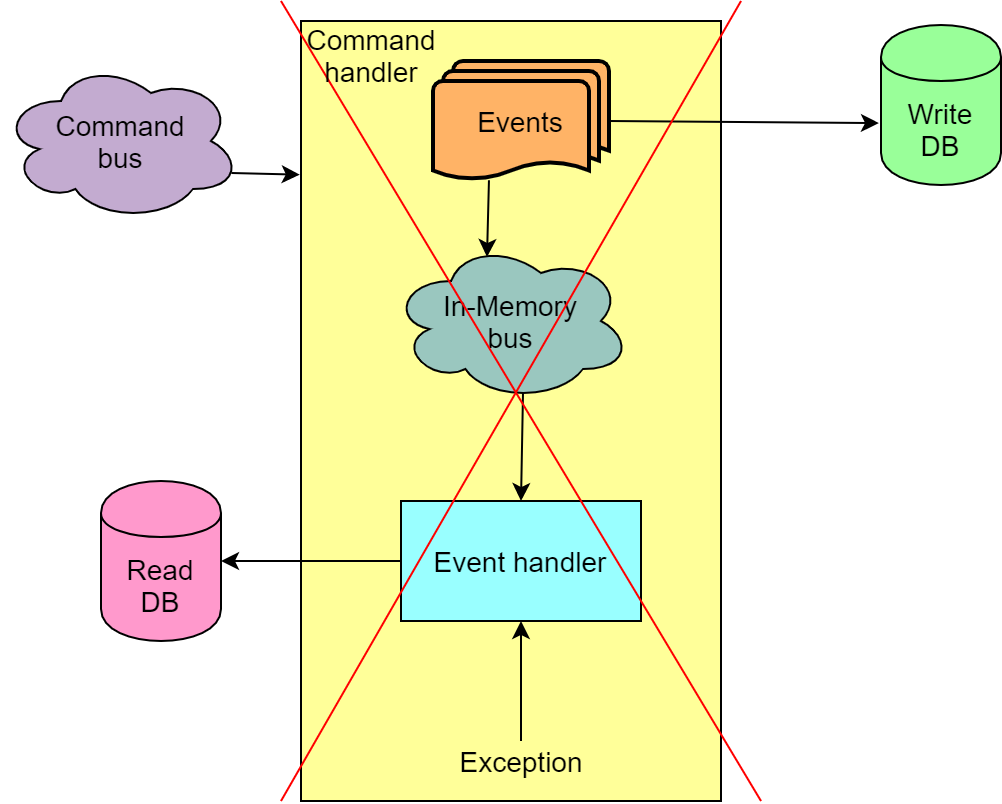
Une telle solution ne contribue pas à l'évolutivité, mais d'un autre côté, nous excluons les situations où notre base de lecture se brise, ce qui, à son tour, décompose les frontaux et il devient impossible de continuer l'enchère sans recréer la base de lecture en rejouant tous les événements.
Envoi d'une commande en réponse à un événement
Ceci est, en principe, approprié, mais uniquement dans le cas où l'échec de l'exécution de cette deuxième commande ne rompt pas l'état du système.
Gérer plusieurs événements d'une commande
En général, l'exécution d'une commande entraîne plusieurs événements. Il arrive que pour chacun des événements, nous devions apporter des modifications à la base de données de lecture. Il arrive également que la séquence d'événements soit également importante et que dans le mauvais ordre, le traitement des événements ne fonctionnera pas comme il se doit. Tout cela signifie que nous ne pouvons pas lire à partir de la file d'attente et traiter les événements d'une commande indépendamment, par exemple, avec différentes instances de code qui lit les messages de la file d'attente. De plus, nous avons besoin d'une garantie que les événements de la file d'attente seront lus dans la même séquence dans laquelle ils y ont été envoyés. Ou nous devons être préparés au fait que tous les événements de commande ne seront pas traités avec succès du premier coup.
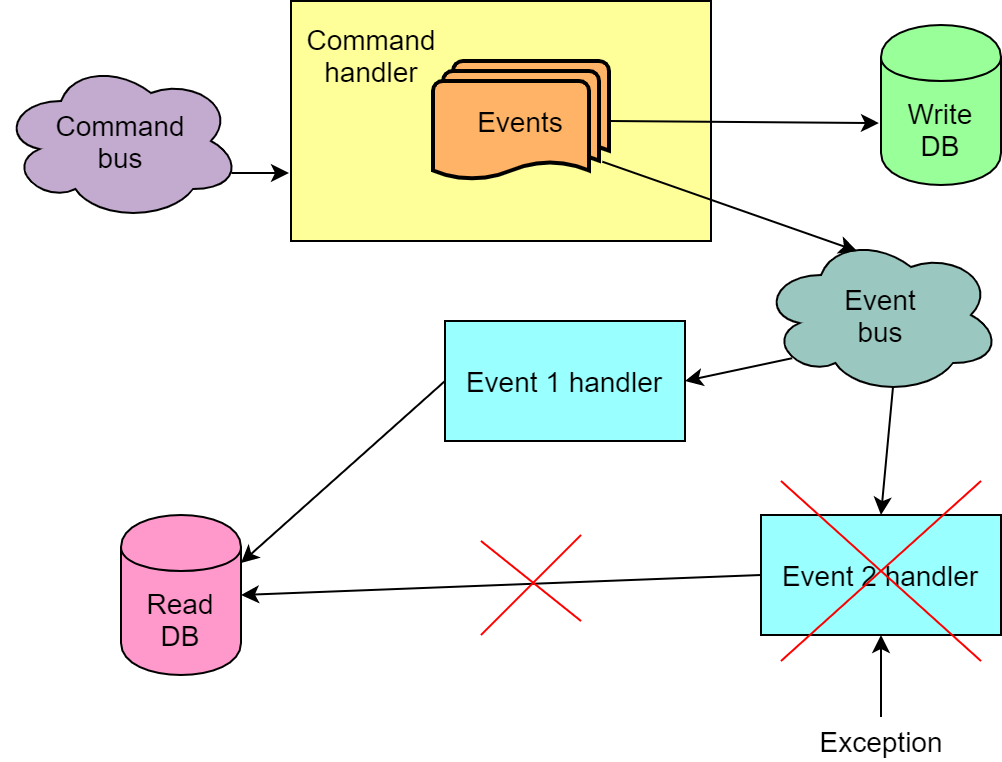
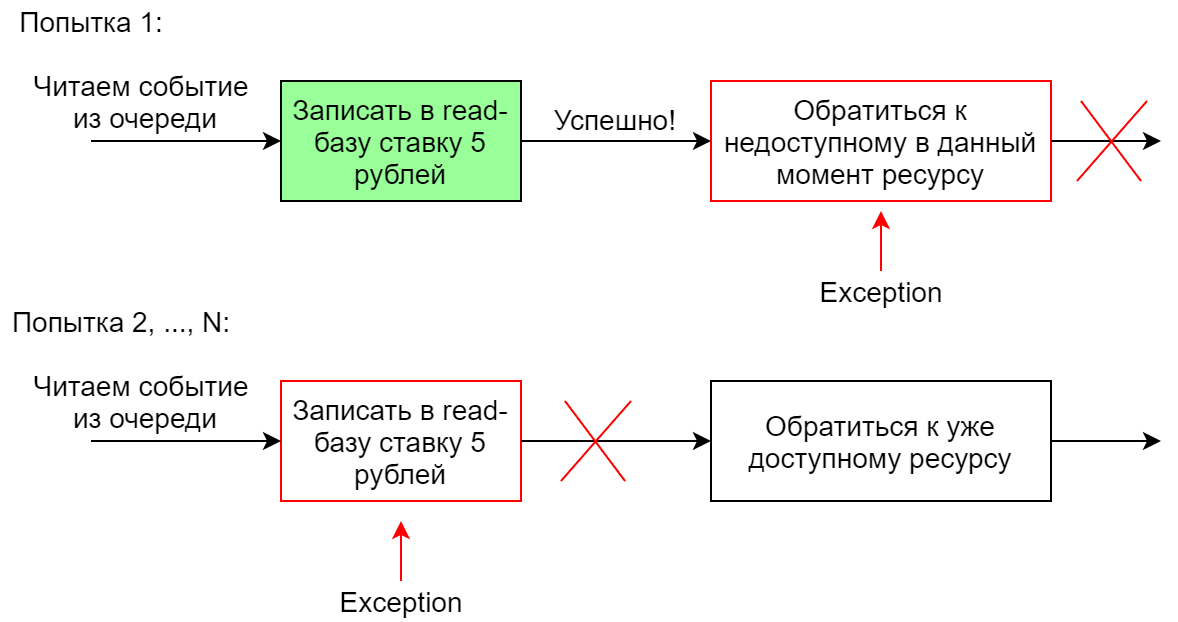
Gérer un événement avec plusieurs gestionnaires
Si le système doit effectuer plusieurs actions différentes en réponse à un événement, plusieurs gestionnaires sont généralement créés pour cet événement. Ils peuvent fonctionner en parallèle ou séquentiellement. Dans le cas d'un lancement séquentiel, si l'un des gestionnaires échoue, toute la séquence est redémarrée (c'est le cas dans Chinchilla). Avec une telle implémentation, il est important que les gestionnaires soient idempotents afin que la deuxième exécution d'un gestionnaire une fois exécuté avec succès n'échoue pas. Sinon, lorsque le deuxième gestionnaire tombe de la chaîne, elle, la chaîne, ne fonctionnera certainement pas entièrement, car le premier gestionnaire tombera lors de la deuxième (et des suivantes) tentatives.
Par exemple, un gestionnaire d'événements dans la base de lecture ajoute une enchère pour un lot de 5 roubles. La première tentative réussira et la seconde ne permettra pas à la contrainte d'être exécutée dans la base de données.
Conclusions / Conclusion
Maintenant, notre projet est à un stade où, comme il nous semble, nous avons déjà marché sur la plupart des râteaux existants qui sont pertinents pour nos spécificités commerciales. En général, nous considérons que notre expérience est plutôt réussie, CQRS & ES est bien adapté à notre domaine. La poursuite du développement du projet se traduit par l'abandon de Chinchilla au profit d'un autre cadre offrant plus de flexibilité. Cependant, il est également possible de refuser du tout d'utiliser le framework. Il y aura aussi probablement des changements dans la direction de la recherche d'un équilibre entre la fiabilité d'une part et la vitesse et l'évolutivité de la solution d'autre part.
En ce qui concerne la composante métier, ici aussi certaines questions restent ouvertes - par exemple, la division du modèle de domaine en agrégats.
Je voudrais espérer que notre expérience sera utile à quelqu'un, aidera à gagner du temps et évitera un râteau. Merci de votre attention.