
Bien sûr, NSPK n'est pas une startup, mais une telle atmosphère a régné dans l'entreprise dans les premières années de son existence, et ce furent des années très intéressantes. Je m'appelle Dmitry Kornyakov , je supporte l'infrastructure Linux avec des exigences de haute disponibilité depuis plus de 10 ans. Il a rejoint l'équipe NSPK en janvier 2016 et, malheureusement, n'a pas vu le tout début de l'existence de l'entreprise, mais est arrivé au stade de grands changements.
En général, on peut dire que notre équipe fournit 2 produits pour l'entreprise. Le premier est l'infrastructure. Le courrier devrait disparaître, le DNS devrait fonctionner et les contrôleurs de domaine devraient vous laisser sur des serveurs qui ne devraient pas tomber. Le paysage informatique de l'entreprise est immense! Ce sont des systèmes critiques pour l'entreprise et la mission, les exigences de disponibilité pour certains sont de 99 999. Le deuxième produit est les serveurs eux-mêmes, physiques et virtuels. Les existants doivent être surveillés et de nouveaux sont régulièrement fournis aux clients de nombreux départements. Dans cet article, je souhaite me concentrer sur la manière dont nous avons développé l'infrastructure responsable du cycle de vie des serveurs.
Le début du chemin
Au début du chemin, notre pile technologique ressemblait à ceci: Contrôleurs de domaine
OS CentOS 7
FreeIPA
Automation - Ansible (+ Tower), Cobbler
Tout cela était localisé dans 3 domaines, répartis sur plusieurs centres de données. Dans un centre de données - systèmes de bureau et sites de test, dans le reste PROD.
À un moment donné, la création de serveurs ressemblait à ceci:
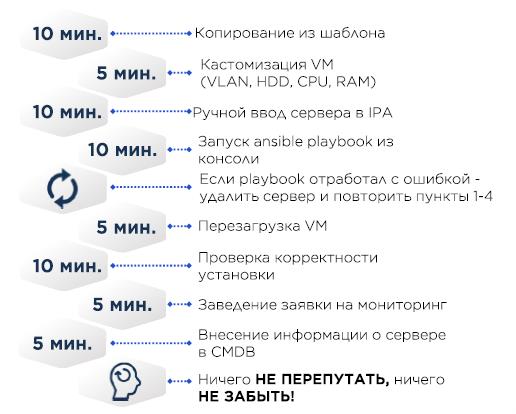
dans le modèle minimal de VM CentOS et le minimum requis, comme le bon /etc/resolv.conf, le reste passe par Ansible.
CMDB - Excel.
Si le serveur est physique, au lieu de copier la machine virtuelle, le système d'exploitation a été installé dessus à l'aide de Cobbler - les adresses MAC du serveur cible sont ajoutées à la configuration de Cobbler, le serveur reçoit une adresse IP via DHCP, puis le système d'exploitation est versé.
Au début, nous avons même essayé de faire une sorte de gestion de configuration dans Cobbler. Mais avec le temps, cela a commencé à poser des problèmes de portabilité des configurations à la fois vers d'autres centres de données et au code Ansible pour préparer la machine virtuelle.
A cette époque, beaucoup d'entre nous percevaient Ansible comme une extension pratique de Bash et ne lésinaient pas sur les constructions utilisant la coque, sed. En général Bashsible. Cela a finalement conduit au fait que si le playbook pour une raison quelconque ne fonctionnait pas sur le serveur, il était plus facile de supprimer le serveur, de réparer le playbook et de le relancer. En fait, il n'y avait pas de versionnage de script, ni de portabilité de configuration.
Par exemple, nous voulions changer une configuration sur tous les serveurs:
- Nous modifions la configuration sur les serveurs existants dans le segment logique / centre de données. Parfois pas du jour au lendemain - les exigences de disponibilité et la loi des grands nombres ne permettent pas d'appliquer toutes les modifications en même temps. Et certains changements sont potentiellement destructeurs et nécessitent tout redémarrage - des services au système d'exploitation lui-même.
- Fixation dans Ansible
- Fixation dans Cobbler
- Répétez N fois pour chaque segment logique / centre de données
Pour que tous les changements se déroulent sans heurts, de nombreux facteurs ont dû être pris en compte et des changements se produisent constamment.
- Refactorisation du code ansible, fichiers de configuration
- Changer les meilleures pratiques internes
- Changements suite à l'analyse des incidents / accidents
- Modification des normes de sécurité, à la fois internes et externes. Par exemple, PCI DSS est mis à jour avec de nouvelles exigences chaque année
Croissance de l'infrastructure et début du chemin Le
nombre de serveurs / domaines logiques / centres de données a augmenté, et avec eux le nombre d'erreurs dans les configurations. À un moment donné, nous sommes arrivés à trois directions, vers lesquelles nous devons développer la gestion de la configuration:
- Automatisation. Dans la mesure du possible, le facteur humain dans les opérations répétitives doit être évité.
- . , . . – , .
- configuration management.
Il reste à ajouter quelques outils.
Nous avons choisi GitLab CE comme référentiel de code, notamment pour les modules CI / CD intégrés.
Vault of secrets - Hashicorp Vault, incl. pour la grande API.
Test des configurations et des rôles ansible - Molecule + Testinfra. Les tests s'exécutent beaucoup plus rapidement s'ils sont connectés à un mitogène ansible. En parallèle, nous avons commencé à écrire notre propre CMDB et un orchestrateur pour le déploiement automatique (dans l'image ci-dessus Cobbler), mais c'est une histoire complètement différente, que mon collègue et le principal développeur de ces systèmes raconteront à l'avenir.
Notre choix:
Molecule + Testinfra
Ansible + Tower + AWX Server
World + DITNET (In-house)
Cobbler
Gitlab + GitLab runner
Hashicorp Vault

En parlant de rôles ansibles. Au début c'était seul, après plusieurs refactorisations il y en a 17. Je recommande fortement de diviser le monolithe en rôles idempotents, qui peuvent ensuite être exécutés séparément, vous pouvez en plus ajouter des balises. Nous avons divisé les rôles par fonctionnalité - réseau, journalisation, packages, matériel, molécule, etc. En général, nous avons adhéré à la stratégie ci-dessous. Je n'insiste pas sur le fait que c'est la seule vérité, mais cela a fonctionné pour nous.
- Copier des serveurs à partir de "l'image dorée" est mal!
Le principal inconvénient est que vous ne savez pas exactement dans quel état se trouvent les images et que toutes les modifications s'appliqueront à toutes les images de toutes les fermes de virtualisation. - Utilisez au minimum les fichiers de configuration par défaut et convenez avec les autres services des fichiers système de base dont vous êtes responsable , par exemple:
- /etc/sysctl.conf , /etc/sysctl.d/. , .
- override systemd .
- , sed
- :
- ! Ansible-lint, yaml-lint, etc
- ! bashsible.
- Ansible molecule .
- , ( 100) 70000 . .

Notre implémentation
Ainsi, les rôles ansible étaient prêts, modélisés et vérifiés par des linters. Et même les gits sont élevés partout. Mais la question de la livraison fiable du code aux différents segments reste ouverte. Nous avons décidé de synchroniser avec les scripts. Cela ressemble à ceci: Une

fois le changement arrivé, CI est lancé, un serveur de test est créé, les rôles sont lancés et testés avec une molécule. Si tout va bien, le code va à la branche production. Mais nous n'appliquons pas le nouveau code aux serveurs existants de la machine. Il s'agit d'une sorte de bouchon nécessaire à la haute disponibilité de nos systèmes. Et lorsque l'infrastructure devient énorme, la loi des grands nombres entre en jeu - même si vous êtes sûr que le changement est inoffensif, il peut avoir des conséquences désastreuses.
Il existe également de nombreuses options pour créer des serveurs. Nous avons fini par choisir des scripts python personnalisés. Et pour CI ansible:
- name: create1.yml - Create a VM from a template
vmware_guest:
hostname: "{{datacenter}}".domain.ru
username: "{{ username_vc }}"
password: "{{ password_vc }}"
validate_certs: no
cluster: "{{cluster}}"
datacenter: "{{datacenter}}"
name: "{{ name }}"
state: poweredon
folder: "/{{folder}}"
template: "{{template}}"
customization:
hostname: "{{ name }}"
domain: domain.ru
dns_servers:
- "{{ ipa1_dns }}"
- "{{ ipa2_dns }}"
networks:
- name: "{{ network }}"
type: static
ip: "{{ip}}"
netmask: "{{netmask}}"
gateway: "{{gateway}}"
wake_on_lan: True
start_connected: True
allow_guest_control: True
wait_for_ip_address: yes
disk:
- size_gb: 1
type: thin
datastore: "{{datastore}}"
- size_gb: 20
type: thin
datastore: "{{datastore}}"C'est ce à quoi nous sommes arrivés, le système continue de vivre et de se développer.
- 17 rôles accessibles pour la configuration du serveur. Chacun des rôles est conçu pour résoudre une tâche logique distincte (journalisation, audit, autorisation des utilisateurs, surveillance, etc.).
- Test de rôle. Molecule + TestInfra.
- Propre développement: CMDB + Orchestrator.
- Temps de création du serveur ~ 30 minutes, automatisé et pratiquement indépendant de la file d'attente des tâches.
- Le même état / dénomination de l'infrastructure dans tous les segments - playbooks, référentiels, éléments de virtualisation.
- Contrôle quotidien de l'état des serveurs avec génération de rapports sur les écarts avec la norme.
J'espère que mon histoire sera utile à ceux qui sont au début du voyage. Quelle pile d'automatisation utilisez-vous?