
Selon une blague bien connue, tous les mémoires dans les librairies devraient être situés dans la section "Science Fiction". Mais dans mon cas, c'est vrai! Il y a longtemps,
3D Talking Heads - Ceci est un buste en bronze qui colle à la langue et clignote de l'œil de Max Planck; un singe qui copie vos expressions faciales en temps réel; il s'agit d'un modèle 3D de la tête assez reconnaissable du vice-président d'Intel, créé entièrement automatiquement à partir de vidéo avec sa participation, et bien plus encore ... Mais tout d'abord.
Vidéo synthétique: Têtes parlantes 3D compatibles MPEG-4 est le nom complet du projet réalisé au Centre de recherche et développement Intel de Nizhny Novgorod en 2000-2003. Le développement était un ensemble de trois technologies principales qui peuvent être utilisées à la fois ensemble et séparément dans de nombreuses applications liées à la création et à l'animation de personnages parlants synthétiques en trois dimensions.
- Reconnaissance et suivi automatiques des expressions faciales et des mouvements de la tête humaine dans la séquence vidéo. Dans ce cas, non seulement les angles de rotation et d'inclinaison de la tête dans tous les plans sont évalués, mais également les contours externes et internes des lèvres et des dents lors d'une conversation, la position des sourcils, le degré de couverture des yeux et même la direction du regard.
- Animation automatique en temps réel de modèles tridimensionnels quasi arbitraires de têtes en fonction des paramètres d'animation obtenus à l'aide des algorithmes de reconnaissance et de suivi à partir du premier point ainsi qu'à partir de toute autre source.
- Création automatique d'un modèle 3D photoréaliste de la tête d'une personne spécifique en utilisant soit deux photos du prototype (vues de face et de côté), soit une séquence vidéo dans laquelle une personne tourne la tête d'une épaule à l'autre.
Et un autre bonus - la technologie, ou plutôt, quelques astuces de rendu réaliste des "têtes parlantes" en temps réel, en tenant compte des limites des performances matérielles et des capacités logicielles qui existaient au début des années 2000.
Et le lien entre ces trois points et demi, ainsi que le lien vers Intel, sont quatre lettres et un chiffre: MPEG-4.
MPEG-4
Peu de gens savent que la norme MPEG-4 , apparue en 1998, en plus de coder des flux vidéo et audio ordinaires, réels, prévoit le codage d'informations sur les objets synthétiques et leur animation - la vidéo dite synthétique. L'un de ces objets est un visage humain, plus précisément une tête définie comme une surface triangulée - un maillage dans l'espace 3D. MPEG-4 définit 84 points spéciaux sur le visage d'une personne - Points caractéristiques (FP): coins et points médians des lèvres, des yeux, des sourcils, du bout du nez, etc.
Les paramètres d'animation faciale (FAP) sont appliqués à ces points spéciaux (ou à l'ensemble du modèle dans le cas des virages et des inclinaisons), décrivant le changement de position et d'expression du visage par rapport à l'état neutre.
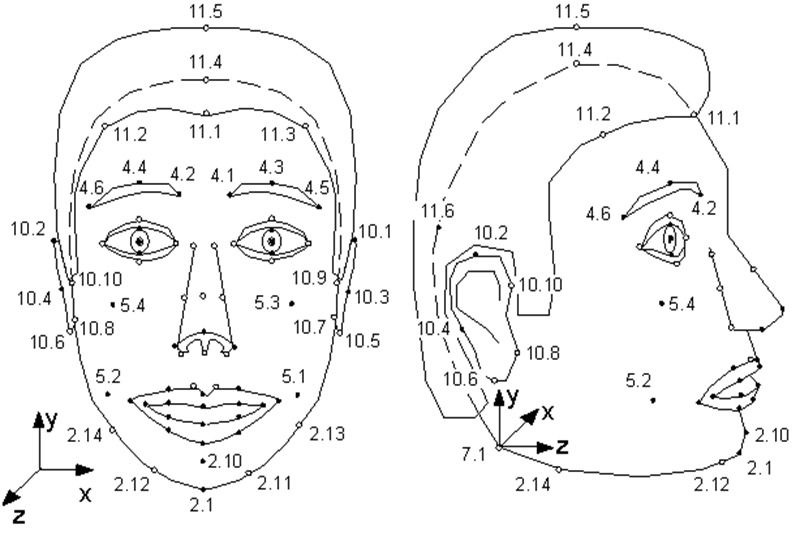
Illustration tirée de la spécification MPEG-4. Points singuliers du modèle. Comme vous pouvez le voir, le modèle peut renifler et bouger ses oreilles.
Autrement dit, la description de chaque image de vidéo synthétique montrant un personnage parlant ressemble à un petit ensemble de paramètres par lesquels le décodeur MPEG-4 doit animer le modèle.
Quel model? MPEG-4 a deux options. Soit le modèle est créé par le codeur et transmis au décodeur une fois au début de la séquence, soit le décodeur a son propre modèle propriétaire, qui est utilisé dans l'animation.
Dans le même temps, les seules exigences MPEG-4 pour le modèle: le stockage en VRML-format et la présence de points spéciaux. Autrement dit, un modèle peut servir de copie photoréaliste d'une personne dont le FAP est utilisé pour l'animation, ainsi que d'un modèle de toute autre personne, et même d'une bouilloire parlante - l'essentiel est que lui, en plus d'un nez, ait une bouche et des yeux.

L'un de nos modèles compatibles MPEG-4 est le plus souriant.En
plus de l'objet principal "visage", MPEG-4 décrit des objets indépendants "mâchoire supérieure", "mâchoire inférieure", "langue", "yeux", sur lesquels sont également fixés des points spéciaux. Mais si un modèle n'a pas ces objets, alors les FAP correspondants ne sont tout simplement pas utilisés par le décodeur.

- Mannequin, mannequin, pourquoi as-tu des yeux et des dents aussi grands? - Pour mieux vous animer!
D'où viennent les modèles d'animation personnalisés? Comment obtenir FAP? Et enfin, comment mettre en œuvre une animation et un rendu réalistes basés sur ces FAP? MPEG-4 ne donne aucune réponse à toutes ces questions - tout comme toute norme de compression vidéo ne dit rien sur le processus de tournage et le contenu des films qu'il encode.
Jusqu'où le progrès est-il venu? Jusqu'à des miracles sans précédent!
Bien sûr, le modèle et l'animation peuvent être créés manuellement par des artistes professionnels, y consacrant des dizaines d'heures et recevant des dizaines de centaines de dollars. Mais cela réduit considérablement la portée de la technologie, la rendant inapplicable à l'échelle industrielle. Et il existe de nombreuses utilisations potentielles de la technologie, qui compresse en fait les images vidéo haute définition sur plusieurs octets (oh, c'est dommage que pas de vidéo). Tout d'abord, le réseautage - jeux, éducation et communication (vidéoconférence) utilisant des caractères synthétiques.
Ces applications étaient particulièrement pertinentes il y a 20 ans, alors que l’Internet était encore accessible à l’aide de modems, et que l’Internet illimité gigabit ressemblait à une sorte de téléportation. Mais, comme le montre la vie, en 2020, la bande passante des canaux Internet reste dans de nombreux cas un problème. Et même s'il n'y a pas un tel problème, disons, nous parlons d'utilisation locale, les caractères synthétiques sont capables de beaucoup. Par exemple, «ressusciter» dans un film un acteur célèbre du siècle dernier, ou donner l'occasion de regarder dans les yeux des assistants vocaux désormais populaires et encore désincarnés. Mais d'abord, le processus de transition d'une vidéo réelle d'une personne parlant à une vidéo synthétique devrait devenir automatique, ou du moins, avec une participation humaine minimale.
C'est exactement ce qui a été mis en œuvre dans Nizhny Novgorod Intel. L'idée est née dans le cadre de la mise en œuvre de la bibliothèque de traitement MPEG, développée à un moment donné par Intel, puis s'est développée non seulement en une spin-off à part entière, mais en un véritable blockbuster fantastique.
De plus, complètement "made in Russia" - ce projet semble être le seul pour toute l'existence d'Intel russe, il n'y avait pas de conservateur chez Intel USA. Lors de sa visite à Nizhny Novgorod, Justin Ratner (chef de la division de recherche d'Intel Labs) a aimé l'idée et a donné le feu vert pour

Synthétique Valery Fedorovich Kuryakin, producteur, réalisateur, scénariste, et dans certains endroits le cascadeur du projet - à l'époque à la tête du groupe de développement Intel.
Premièrement, la combinaison de technologies aussi différentes dans un petit projet, sur lequel seulement trois à sept personnes travaillaient en même temps, était fantastique. Au cours de ces années, au moins une douzaine d'entreprises existaient déjà dans le monde, engagées à la fois dans la reconnaissance faciale et le suivi, ainsi que dans la création et l'animation de «têtes parlantes». Tous, bien sûr, avaient des réalisations dans certains domaines: certains avaient une excellente qualité de modèle, certains montraient des animations très réalistes, certains ont réussi à reconnaître et à suivre. Mais pas une seule entreprise n'a été en mesure de proposer l'ensemble des technologies permettant de créer de manière entièrement automatique une vidéo synthétique, dans laquelle un modèle, très similaire à son prototype, copie parfaitement ses expressions faciales et ses mouvements.
Le projet Intel 3D Talking Heads était le premier et à l'époque la seule implémentation d'un cycle complet de communication vidéo basé sur tous les éléments du profil synthétique MPEG-4.

Convoyeur du projet de production de clones synthétiques du modèle 2003.
Deuxièmement, la combinaison du matériel qui existait à l'époque et des solutions technologiques mises en œuvre dans le projet, ainsi que des plans pour leur utilisation, était fantastique. Donc, au début du projet, j'avais un Nokia 3310 dans ma poche, j'avais un Pentium III-500MHz sur mon bureau, et des algorithmes particulièrement critiques pour les performances pour le travail en temps réel ont été testés sur un serveur Pentium 4-1.7GHz avec 128 Mo de RAM.
Dans le même temps, nous espérions que bientôt nos modèles fonctionneraient sur des appareils mobiles et que la qualité ne serait pas pire que celle des héros du film d'animation photoréaliste " Final Fantasy " sorti à cette époque (2001) .

137 millions de dollars était le coût pour un film créé sur une ferme de rendu d'environ 1000 ordinateurs Pentium III. Affiche de www.thefinalfantasy.com
Mais voyons ce qui s'est passé avec nous.
Reconnaissance et suivi des visages, acquisition FAP.
Cette technologie a été présentée en deux versions:
- mode temps réel (25 images par seconde sur le processeur Pentium 4-1,7 GHz déjà mentionné), lorsqu'une personne se tenant directement devant une caméra vidéo connectée à un ordinateur est suivie;
- ( 1 ), .
Dans le même temps, la dynamique des changements de position / état du visage humain a été surveillée en temps réel - nous pourrions estimer approximativement les angles de rotation et d'inclinaison de la tête dans tous les plans, le degré approximatif d'ouverture et d'étirement de la bouche et le soulèvement des sourcils, et reconnaître le clignotement. Pour certaines applications, une telle estimation approximative est suffisante, mais si vous avez besoin de suivre avec précision les expressions faciales d'une personne, des algorithmes plus complexes sont nécessaires, ce qui signifie des algorithmes plus lents.
En mode hors ligne, notre technologie a permis d'évaluer non seulement la position de la tête dans son ensemble, mais aussi de reconnaître et de suivre de manière absolument précise les contours externes et internes des lèvres et des dents lors d'une conversation, la position des sourcils, le degré de couverture oculaire et même le déplacement des pupilles - la direction du regard.
Pour la reconnaissance et le suivi, une combinaison d'algorithmes de vision par ordinateur bien connus a été utilisée, dont certains avaient déjà été implémentés dans la nouvelle bibliothèque OpenCV - par exemple, Optical Flow, ainsi que nos propres méthodes originales basées sur une connaissance a priori de la forme des objets correspondants. En particulier - sur notre version améliorée de la méthode des modèles déformables , pour laquelle les participants au projet ont reçu un brevet .
La technologie a été mise en œuvre sous la forme d'une bibliothèque de fonctions recevant des images vidéo à visage humain en entrée et en sortie des FAP correspondants.
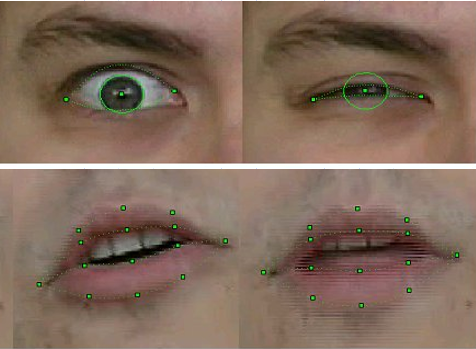
Qualité de la reconnaissance et du suivi FP échantillon 2003
Bien sûr, la technologie était imparfaite. La reconnaissance et le suivi échouaient si la personne dans la monture avait une moustache, des lunettes ou des rides profondes. Mais depuis trois ans de travail, la qualité s'est nettement améliorée. Si dans les premières versions des modèles de reconnaissance de mouvement lors de la prise de vue d'une vidéo, il fallait coller des marques spéciales sur les points FP correspondants du visage - des cercles de papier blanc obtenus avec un poinçon de bureau, alors, dans la finale du projet, rien de ce genre n'était bien sûr nécessaire. De plus, nous avons réussi à suivre assez régulièrement la position des dents et la direction du regard - et c'est à la résolution de la vidéo des webcams de l'époque, où de tels détails étaient à peine discernables!

Ce n'est pas la varicelle, mais des images de «l'enfance» de la technologie de reconnaissance. Ingénieur principal d'Intel, et à cette époque - Alexander Bovyrin, un employé novice d'Intel, enseigne un modèle synthétique pour lire la poésie
Animation
Comme cela a été dit à plusieurs reprises, l'animation d'un modèle en MPEG-4 est entièrement déterminée par le FAP. Et tout serait simple, sinon pour quelques problèmes.
Premièrement, le fait que les FAP des séquences vidéo sont extraits en 2D et que le modèle est en 3D, et il est nécessaire de compléter en quelque sorte la troisième coordonnée. Autrement dit, un sourire accueillant dans le profil (et les utilisateurs devraient pouvoir voir ce profil, sinon il n'y a pas de sens en 3D) ne devrait pas se transformer en un sourire inquiétant.
Deuxièmement, comme on l'a également dit, les FAP décrivent le mouvement de points singuliers, dont il y en a environ quatre-vingts dans le modèle, alors qu'au moins un modèle quelque peu réaliste dans son ensemble se compose de plusieurs milliers de sommets (dans notre cas, de quatre à huit mille), et des algorithmes sont nécessaires pour calculer le déplacement de tous les autres points du modèle sur la base des déplacements FP.
Autrement dit, il est clair que lorsque la tête est tournée d'un angle égal, tous les points tourneront, mais en souriant, même si cela va jusqu'aux oreilles, l '«indignation» du déplacement du coin de la bouche devrait progressivement s'estomper, déplacer la joue, mais pas les oreilles. De plus, il doit être automatique et réaliste pour tout modèle avec n'importe quelle largeur de bouche et géométrie de maillage autour de lui. Pour résoudre ces problèmes, des algorithmes d'animation ont été créés dans le cadre du projet. Ils étaient basés sur un modèle pseudomusculaire, qui décrit simplement les muscles qui contrôlent les expressions faciales.
Et puis, pour chaque modèle et chaque FAP, la "zone d'influence" a été préalablement déterminée automatiquement - les sommets impliqués dans l'action correspondante, dont les mouvements ont été calculés en tenant compte de l'anatomie et de la géométrie - en maintenant la douceur et la connectivité de la surface. Autrement dit, l'animation se composait de deux parties - préliminaire, réalisée hors ligne, où certains coefficients pour les sommets de maillage ont été créés et saisis dans la table, et en ligne, où, en tenant compte des données de la table, une animation en temps réel a été appliquée au modèle.

Sourire n'est pas facile pour un modèle 3D et ses créateurs
Création d'un modèle 3D d'une personne spécifique.
Dans le cas général, la tâche de reconstruction d'un objet tridimensionnel à partir de ses images bidimensionnelles est très difficile. Autrement dit, les algorithmes pour le résoudre sont connus depuis longtemps de l'humanité, mais en pratique, en raison de nombreux facteurs, le résultat est loin d'être celui souhaité. Et cela est particulièrement visible dans le cas de la reconstruction de la forme du visage d'une personne - ici, vous pouvez vous rappeler nos premiers modèles avec des yeux en forme de huit (l'ombre des cils sur les photos originales n'a pas réussi) ou une légère bifurcation du nez (la raison de la prescription des années ne peut pas être restaurée).
Mais dans le cas des têtes parlantes MPEG-4, la tâche est grandement simplifiée, car l'ensemble des traits du visage humain (nez, bouche, yeux, etc.) est le même pour tout le monde, et les différences externes par lesquelles nous tous (et les programmes de vision par ordinateur) distinguons les gens les uns des autres "géométriques" - la taille / proportions et l'emplacement de ces caractéristiques et "texturé" - couleurs et relief. Par conséquent, l'un des profils de la vidéo MPEG-4 synthétique, l'étalonnage, qui a été mis en œuvre dans le projet, suppose que le décodeur a un modèle généralisé d'une «personne abstraite» qui est personnalisé pour une personne spécifique à l'aide d'une séquence photo ou vidéo.
Notre "homme sphérique dans le vide" - un modèle de personnalisation
Autrement dit, les déformations globales et locales du maillage 3D se produisent pour correspondre aux proportions des traits du visage du prototype mis en évidence dans sa photo / vidéo, après quoi la «texture» du prototype est appliquée au modèle - c'est-à-dire la texture créée à partir des mêmes images d'entrée. Le résultat est un modèle synthétique. Cela se fait une fois pour chaque modèle, bien sûr hors ligne, et bien sûr, pas si facile.
Tout d'abord, l' enregistrement ou la rectification des images d'entrée est nécessaire - les amenant à un système de coordonnées qui coïncide avec le système de coordonnées du modèle 3D. En outre, sur les images d'entrée, il est nécessaire de détecter des points singuliers et, en fonction de leur emplacement, de déformer le modèle 3D, par exemple, en utilisant la méthode des fonctions de base radiale, après quoi, à l'aide d'algorithmes d' assemblage de panorama , générez une texture à partir de deux images d'entrée ou plus, c'est-à-dire «mélangez-les» dans la bonne proportion pour obtenir un maximum d'informations visuelles, ainsi que de compenser la différence d'éclairage et de ton, qui est toujours présente même sur les photos prises avec les mêmes paramètres de l'appareil photo (ce qui n'est pas toujours le cas), et très visible lors de la combinaison de ces photos.

Il ne s'agit pas d'une image fixe de films d'horreur, mais de la texture d'un modèle 3D de Pat Gelsinger , créé avec sa permission lors de la démonstration du projet au Intel Developer Forum en 2003.
La version initiale de la technologie de personnalisation du modèle basée sur deux photos a été mise en œuvre par les participants au projet eux-mêmes chez Intel. Mais après avoir atteint un certain niveau de qualité et réalisé les limites de leurs capacités, il a été décidé de transférer cette partie des travaux au groupe de recherche de l'Université d'État de Moscou, qui avait une expérience dans ce domaine. Le résultat du travail de chercheurs de l'Université d'État de Moscou sous la direction de Denis Ivanov a été l'application "Head Calibration Environment", qui a effectué toutes les opérations ci-dessus pour créer un modèle personnalisé d'une personne à partir de sa photo de plein visage et de profil.
Le seul point subtil est que l'application n'était pas intégrée à l'unité de reconnaissance faciale décrite ci-dessus, qui a été développée dans notre projet, de sorte que les points spéciaux de la photo nécessaires au fonctionnement des algorithmes devaient être marqués manuellement. Bien sûr, pas tous les 84, mais seulement les principaux, et étant donné que l'application avait une interface utilisateur correspondante, cette opération n'a pris que quelques secondes.
En outre, une version entièrement automatique de la reconstruction du modèle à partir d'une séquence vidéo a été mise en œuvre, dans laquelle une personne tourne la tête d'une épaule à l'autre. Mais, comme vous pouvez le deviner, la qualité de la texture extraite de la vidéo était nettement inférieure à la texture créée à partir de photographies d'appareils photo numériques de l'époque avec une résolution de ~ 4K (3-5 mégapixels), ce qui signifie que le modèle résultant était moins attrayant. Par conséquent, il y avait aussi une version intermédiaire utilisant plusieurs photos d'angles de rotation de la tête différents.

La rangée du haut est des personnes virtuelles, la rangée du bas est réelle.
Quelle a été la qualité du résultat obtenu? La qualité du modèle résultant doit être évaluée non pas en statique, mais directement sur la vidéo synthétique par sa similitude avec la vidéo correspondante de l'original. Mais les termes «similaires et non similaires» ne sont pas mathématiques, ils dépendent de la perception d'une personne en particulier, et il est difficile de comprendre en quoi notre modèle synthétique et son animation diffèrent du prototype. Certaines personnes aiment ça, d'autres pas. Mais le résultat de trois ans de travail était que lors de la démonstration des résultats lors de diverses expositions, le public devait expliquer dans quelle fenêtre se trouvait la vraie vidéo et dans laquelle - la vidéo synthétique.
Visualisation.
Pour démontrer les résultats de toutes les technologies ci-dessus, un lecteur vidéo synthétique MPEG-4 spécial a été créé. Le lecteur a reçu en entrée un fichier VRML avec un modèle, un flux (ou fichier) avec FAP, ainsi que des flux (fichiers) avec de la vidéo et de l'audio réels pour un affichage synchronisé avec une vidéo synthétique avec prise en charge du mode "image dans l'image". Lors de la démonstration d'une vidéo synthétique, l'utilisateur a eu la possibilité de zoomer sur le modèle, ainsi que de le regarder de tous les côtés, simplement en tournant la souris à un angle arbitraire.

Bien que le lecteur ait été écrit pour Windows, mais en tenant compte d'un éventuel portage à l'avenir vers d'autres systèmes d'exploitation, y compris les mobiles. Par conséquent, l'OpenGL 1.1 "classique" sans aucune extension a été choisi comme bibliothèque 3D.
Dans le même temps, le joueur a non seulement montré le modèle, mais a également essayé de l'améliorer, mais pas de le retoucher, comme c'est maintenant le cas avec les modèles photo, mais, au contraire, de le rendre aussi réaliste que possible. A savoir, en restant dans le cadre de l'éclairage Phong le plus simple et sans shaders, mais ayant des exigences de performances strictes, l'unité de rendu du joueur a automatiquement créé des modèles synthétiques: imiter les rides, les cils, capables de rétrécir et dilater les pupilles de manière réaliste; mettre des lunettes de taille appropriée sur le modèle; et en utilisant également le tracé de rayons le plus simple, il a calculé l'éclairage (ombrage) de la langue et des dents en parlant.
Bien sûr, ces méthodes ne sont plus pertinentes maintenant, mais s'en souvenir est assez intéressant. Ainsi, pour la synthèse de rides mimiques, c'est-à-dire de petits plis du relief cutané sur le visage, visibles lors de la contraction des muscles du visage, les tailles relativement grandes des triangles de la maille du modèle ne permettaient pas de créer de vrais plis. Par conséquent, une sorte de technologie de bump mapping a été appliquée - la cartographie normale. Au lieu de changer la géométrie du modèle, la direction des normales vers la surface aux bons endroits a changé et la dépendance de la composante diffuse de l'éclairage à chaque point de la normale a créé l'effet désiré.

C'est du réalisme synthétique.
Mais le joueur ne s'est pas arrêté là. Pour faciliter l'utilisation des technologies et les transférer vers le monde extérieur, la bibliothèque d'objets Intel Facial Animation Library a été créée, contenant des fonctions d'animation (transformation 3D) et de visualisation du modèle, de sorte que quiconque souhaite (et dispose d'une source FAP) appelle plusieurs fonctions - "Créer une scène", " CreateActor »,« Animate »pourrait animer et montrer son modèle dans son application.
Résultat
Qu'est-ce que la participation à ce projet m'a apporté personnellement? Bien sûr, l'opportunité de collaborer avec des personnes formidables sur des technologies intéressantes. Ils m'ont emmené dans le projet pour ma connaissance des méthodes et bibliothèques de rendu de modèles 3D et d'optimisation des performances pour x86. Mais, naturellement, il n'était pas possible de se limiter à la 3D, il fallait donc passer à d'autres dimensions. Pour écrire un player, il fallait s'occuper de l'analyse VRML (il n'y avait pas de bibliothèques prêtes à l'emploi à cet effet), maîtriser le travail natif avec les threads sous Windows, assurer le travail conjoint de plusieurs threads avec synchronisation 25 fois par seconde, sans oublier l'interaction utilisateur, et même réfléchir et implémenter interface. Plus tard, cette liste a été ajoutée pour participer à l'amélioration des algorithmes de suivi des visages. Et la nécessité d'intégrer en permanence et de combiner simplement des composants écrits par d'autres membres de l'équipe avec le joueur,et aussi présenter le projet au monde extérieur a grandement amélioré mes compétences en communication et en coordination.
Qu'a donné la participation d'Intel à ce projet? En conséquence, notre équipe a créé un produit qui peut servir de bon test et de démonstration des capacités des plates-formes et des produits Intel. De plus, tant le matériel - CPU et GPU, que les logiciels - nos têtes (à la fois réelles et synthétiques) ont contribué à l'amélioration de la bibliothèque OpenCV.
En outre, nous pouvons affirmer avec certitude que le projet a laissé une marque visible dans l'histoire - à la suite de son travail, ses participants ont écrit des articles et présenté des rapports lors de conférences spécialisées sur la vision par ordinateur et l'infographie, russe ( GraphiCon ) et internationale.
Et les applications de démonstration 3D Talking Heads ont été présentées par Intel dans des dizaines de salons, forums et congrès à travers le monde.
Dans l'intervalle, la technologie, bien sûr, a beaucoup progressé, ce qui facilite la création et l'animation automatiques de personnages synthétiques. Il y avait une définition de la profondeur de la chambre Intel Real Sense , et les réseaux de neurones basés sur de grandes données ont appris à générer des images réalistes de personnes, même inexistantes.
Mais, néanmoins, les développements du projet 3D Talking Heads, publiés dans le domaine public, continuent d'être consultés jusqu'à présent.
Regardez notre jeune enceinte MPEG-4 synthétique de presque vingt ans et vous: