Dans mon discours, j'ai partagé mon expérience de l'utilisation d'Alembic, un outil éprouvé de gestion des migrations. Pourquoi choisir Alembic, comment l'utiliser pour préparer des migrations, comment les exécuter (automatiquement ou manuellement), comment résoudre les problèmes de changements irréversibles, pourquoi tester les migrations, quels problèmes les tests peuvent révéler et comment les implémenter - j'ai essayé de répondre à toutes ces questions. En même temps, j'ai partagé plusieurs astuces de vie qui rendront le travail avec les migrations dans Alembic facile et agréable.
Depuis le jour du rapport, le code sur GitHub a été légèrement mis à jour, il y a plus d'exemples. Si vous voulez voir le code exactement tel qu'il apparaît sur les diapositives, voici un lien vers un commit de cette époque.
- Salut! Je m'appelle Alexander, je travaille à Edadil. Aujourd'hui, je veux vous dire comment nous vivons avec les migrations et comment vous pourriez vivre avec elles. Peut-être que cela vous aidera à vivre plus facilement.
Que sont les migrations?
Avant de commencer, il vaut la peine de parler de ce que sont les migrations en général. Par exemple, vous avez une application et vous créez quelques tablettes pour que cela fonctionne, va vers elles. Ensuite, vous déployez une nouvelle version, dans laquelle quelque chose a changé - la première plaque a changé, la seconde ne l'est pas et la troisième n'était pas là avant, mais elle est apparue.

Puis une nouvelle version de l'application apparaît, dans laquelle une plaque est supprimée, rien n'arrive au reste. Ce que c'est? On peut dire que c'est l'état qui peut être décrit par la migration. Lorsque nous passons d'un état à un autre, il s'agit d'une mise à niveau, lorsque nous voulons revenir en arrière - rétrograder.
Que sont les migrations?

D'une part, c'est du code qui change l'état de la base de données. D'un autre côté, c'est le processus que nous commençons.

Quelles propriétés devraient avoir les migrations? Il est important que les états que nous basculons dans les versions de l'application soient atomiques. Si, par exemple, nous voulons que nous ayons deux tables, mais qu'une seule apparaît, cela peut conduire à de mauvaises conséquences en production.
Il est important que nous puissions annuler nos modifications, car si vous déployez une nouvelle version, elle ne décolle pas et vous ne pouvez pas revenir en arrière, tout se termine généralement mal.
Il est également important que les versions soient commandées afin que vous puissiez enchaîner la façon dont elles roulent.
Outils
Comment mettre en œuvre ces migrations?
La première idée qui me vient à l'esprit: d'accord, la migration est SQL, pourquoi ne pas prendre et créer des fichiers SQL avec des requêtes. Il existe plusieurs autres modules qui peuvent nous faciliter la vie.

Si nous regardons ce qui se passe à l'intérieur, il y a en effet quelques demandes. Cela peut être CREATE TABLE, ALTER, n'importe quoi d'autre. Dans le fichier downgrade_v1.sql, nous annulons tout.

Pourquoi ne devriez-vous pas faire ça? Principalement parce que vous devez le faire avec vos mains. N'oubliez pas d'écrire begin, puis validez vos modifications. Lorsque vous écrivez du code, vous devrez vous souvenir de toutes les dépendances et de ce qu'il faut faire dans quel ordre. C'est un travail plutôt routinier, difficile et chronophage.
Vous n'avez aucune protection contre le lancement accidentel du mauvais fichier. Vous devez exécuter tous les fichiers à la main. Si vous avez 15 migrations, ce n'est pas facile. Vous devrez appeler certains psql 15 fois, ce ne sera pas très cool.
Plus important encore, vous ne savez jamais dans quel état se trouve votre base de données. Vous devez écrire quelque part - sur une feuille de papier, ailleurs - quels fichiers vous avez téléchargés et lesquels ne l'ont pas fait. Cela ne sonne pas très bien non plus.

Il existe un module yoyo-migrations . Il prend en charge les bases de données les plus courantes et utilise des requêtes brutes.

Si on regarde ce qu'il nous propose, ça ressemble à ça. Nous voyons le même SQL. Il y a déjà du code Python sur la droite qui importe la bibliothèque yoyo.

Ainsi, nous pouvons déjà démarrer les migrations, exactement automatiquement. En d'autres termes, il existe une commande qui crée et ajoute une nouvelle migration à la chaîne où nous pouvons écrire notre code SQL. À l'aide des commandes, vous pouvez appliquer une ou plusieurs migrations, vous pouvez revenir en arrière, c'est déjà un pas en avant.

L'avantage est que vous n'avez plus besoin d'écrire sur un morceau de papier les requêtes que vous avez effectuées sur la base de données, les fichiers que vous avez lancés et où vous devez restaurer si quelque chose se produit. Vous avez une sorte de protection infaillible: vous ne pourrez plus exécuter une migration conçue pour autre chose, pour la transition entre deux autres états de la base de données. Un très gros plus: cette chose effectue chaque migration dans une transaction distincte. Cela donne également de telles garanties.

Les inconvénients sont évidents. Vous avez toujours du SQL brut. Si, par exemple, vous avez une production de données volumineuse avec une logique tentaculaire en Python, vous ne pouvez pas l'utiliser, car vous n'avez que SQL.
De plus, vous trouverez de nombreux travaux de routine qui ne peuvent pas être automatisés. Il est nécessaire de garder une trace de toutes les relations entre les tables - ce qui peut être écrit quelque part et ce qui n'est pas encore possible. En général, il existe des inconvénients assez évidents.
Un autre module qui mérite une attention particulière, et pour lequel tout le discours est aujourd'hui, est Alembic .

Il a les mêmes choses que yoyo, et bien plus encore. Il surveille non seulement vos migrations et sait comment les créer, mais vous permet également d'écrire une logique métier très complexe, de connecter toute votre production de données, toutes les fonctions en Python. Extrayez les données et traitez-les en interne si vous le souhaitez. Si vous ne le voulez pas, vous n'êtes pas obligé.
Il peut écrire automatiquement du code pour vous dans la plupart des cas. Pas toujours, bien sûr, mais cela semble être un bon plus après avoir beaucoup écrit avec vos mains.
Il a beaucoup de trucs sympas. Par exemple, SQLite ne prend pas entièrement en charge ALTER TABLE. Et Alembic a des fonctionnalités qui vous permettent de contourner facilement cela en quelques lignes, et vous n'y pensez même pas.
Dans les diapositives précédentes, il y avait un module Django-migrations. C'est également un très bon module pour les migrations. Son principe est comparable à celui d'Alembic en termes de fonctionnalité. La seule différence est qu'il est spécifique au cadre, et Alembic ne l'est pas.
SQLAlchemy
Puisque Alembic est basé sur SQLAlchemy, je suggère de parcourir un peu SQLAlchemy pour se souvenir ou apprendre de quoi il s'agit.

Jusqu'à présent, nous avons examiné les requêtes brutes. Les requêtes brutes ne sont pas mauvaises. Cela peut être très bien. Lorsque vous avez une application très chargée, c'est peut-être exactement ce dont vous avez besoin. Inutile de perdre du temps à convertir certains objets en une sorte de requêtes.
Aucune bibliothèque supplémentaire n'est requise. Il suffit de prendre le pilote et c'est tout, ça marche. Mais par exemple, si vous écrivez des requêtes complexes, ce ne sera pas si facile: eh bien, vous pouvez prendre une constante, la faire apparaître, écrire un gros code multiligne. Mais si vous avez 10 à 20 demandes de ce type, il sera déjà très difficile à lire. Ensuite, vous ne pouvez en aucun cas les réutiliser. Vous avez beaucoup de texte et, bien sûr, des fonctions pour travailler avec des chaînes, des f-strings et tout ça, mais cela ne sonne déjà pas très bien. Ils sont difficiles à lire.
Si, par exemple, vous avez une classe dans laquelle vous souhaitez également avoir des requêtes et des structures complexes, l'indentation est une douleur sauvage. Si vous souhaitez effectuer une migration brute, le seul moyen de trouver où vous utilisez quelque chose est d'utiliser grep. Et vous ne disposez pas non plus d'un outil dynamique pour les requêtes dynamiques.
Par exemple, une tâche super facile. Vous avez une entité, elle a 15 champs dans une plaque. Vous souhaitez faire une requête PATCH. Cela semble super simple. Essayez d'écrire ceci sur des requêtes brutes. Cela ne sera pas très joli et la demande de tirage ne sera probablement pas approuvée.

Il existe une alternative à cela: le générateur de requêtes. Il présente certainement des inconvénients car il vous permet de représenter vos requêtes sous forme d'objets en Python.
Pour plus de commodité, vous devrez payer avec le temps de génération des requêtes et la mémoire. Mais il y a des avantages. Lorsque vous écrivez des applications volumineuses et complexes, vous avez besoin d'abstractions. Le générateur de requêtes peut vous donner ces abstractions. Ces requêtes peuvent être décomposées, nous verrons comment cela se fait un peu plus tard. Ils peuvent être réutilisés, étendus ou encapsulés dans des fonctions qui seront déjà appelées des noms conviviaux associés à la logique métier.
Il est très facile de créer des requêtes dynamiques. Si vous avez besoin de changer quelque chose, d'écrire une migration, l'analyse statistique du code suffit. C'est très pratique.
Pourquoi SQLAlchemy est-il de toute façon? Pourquoi cela vaut-il la peine de s'arrêter?

C'est une question non seulement sur la migration, mais en général. Parce que lorsque nous avons Alembic, il est logique d'utiliser la pile entière à la fois, car SQLAlchemy ne fonctionne pas seulement avec des pilotes synchrones. Autrement dit, Django est un outil très cool, mais Alchemy peut être utilisé, par exemple, avec asyncpg et aiopg . Asyncpg vous permet de lire, comme l'a dit Selivanov, un million de lignes par seconde - lire à partir de la base de données et transférer vers Python. Bien sûr, avec SQLAlchemy, il y aura un peu moins, il y aura des frais généraux. Mais peu importe.
SQLAlchemy possède un nombre incroyable de pilotes avec lesquels il sait travailler. Il existe Oracle et PostgreSQL, et tout pour tous les goûts et toutes les couleurs. De plus, ils sont déjà prêts à l'emploi, et si vous avez besoin de quelque chose de séparé, alors là, j'ai récemment regardé, il y a même Elasticsearch. C'est vrai, seulement pour lire, mais - comprenez-vous? - Elasticsearch dans SQLAlchemy.
Il y a une très bonne documentation, une grande communauté. Il y a beaucoup de bibliothèques. Et ce qui est important, après tout, il ne vous dicte pas les frameworks et les bibliothèques. Lorsque vous effectuez une tâche étroite qui doit être bien exécutée, cela peut être un outil.
Alors, de quoi s'agit-il?
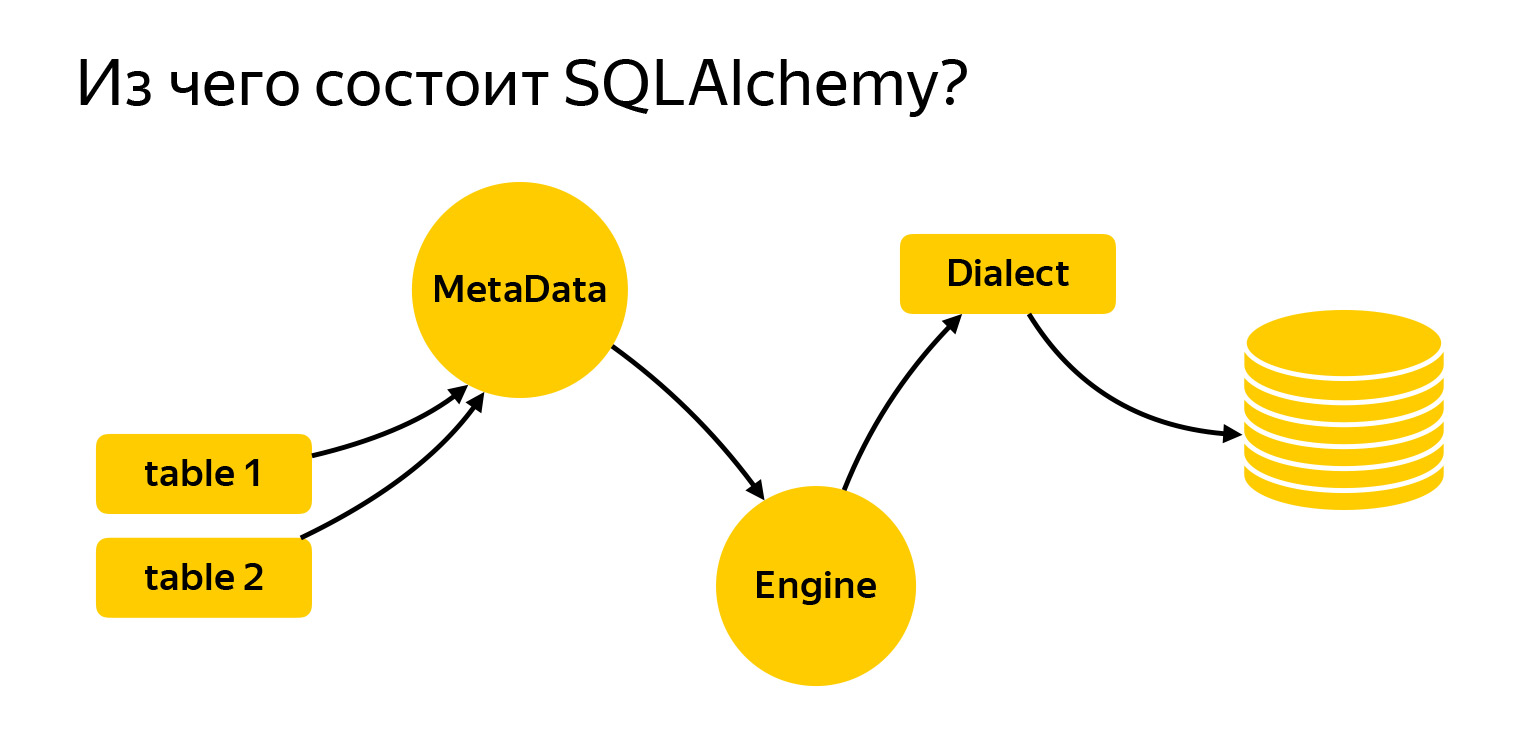
J'ai amené ici les principales entités avec lesquelles nous allons travailler aujourd'hui. Ce sont des tableaux. Pour rédiger des demandes, Alchemy doit savoir ce que c'est et avec quoi nous travaillons. Vient ensuite le registre MetaData. Le moteur est une chose qui se connecte à la base de données et communique avec elle via Dialect.
Regardons de plus près ce que c'est.

MetaData est une sorte d'objet, un conteneur, dans lequel vous allez ajouter vos tables, index et, en général, toutes les entités que vous avez. C'est un objet qui reflète, d'une part, comment vous voulez voir la base de données, en fonction de votre code écrit. D'un autre côté, MetaData peut accéder à la base de données, obtenir un instantané de ce qui s'y trouve réellement et créer lui-même ce modèle d'objet.
En outre, l'objet MetaData a une fonctionnalité très intéressante. Il vous permet de définir un modèle de dénomination par défaut pour les index et les contraintes. Ceci est très important lorsque vous écrivez des migrations, car chaque base de données - que ce soit PostgreSQL, MySQL, MariaDB - a sa propre vision de la façon dont les index doivent être appelés.
Certains développeurs ont également leur propre vision. Et SQLAlchemy vous permet de définir une fois pour toutes comment cela fonctionne. J'ai dû développer un projet qui devait fonctionner à la fois avec SQLite et PostgreSQL. C'était très pratique.

Cela ressemble à ceci: vous importez un objet MetaData depuis SQLAlchemy et lorsque vous le créez, spécifiez des modèles à l'aide du paramètre naming_convention, dont les clés spécifient les types d'index et de contraintes: ix - index régulier, uq - index unique, fk - clé étrangère, pk - clé primaire.
Dans les valeurs du paramètre naming_convention, vous pouvez spécifier un modèle composé du type d'index / de la contrainte (ix / uq / fk, etc.) et du nom de la table, séparés par des traits de soulignement. Dans certains modèles, vous pouvez également répertorier toutes les colonnes. Par exemple, il n'est pas nécessaire de le faire pour la clé primaire, vous pouvez simplement spécifier le nom de la table.
Lorsque vous commencez à créer un nouveau projet, vous y ajoutez une fois des modèles de dénomination et vous oubliez. Depuis lors, toutes les migrations ont été générées avec les mêmes noms d'index et de contrainte.
Ceci est important pour une autre raison: lorsque vous décidez que cet index n'est plus nécessaire dans votre modèle objet et que vous le supprimez, alors Alembic saura comment il s'appelle et générera correctement la migration. C'est déjà un certain gage de fiabilité, que tout fonctionnera comme il se doit.
Une autre entité très importante que vous êtes susceptible de rencontrer est une table, un objet qui décrit ce que la table contient.

La table a un nom, des colonnes avec des types de données et elle fait nécessairement référence au registre MetaData, puisque MetaData est un registre de tout ce que vous décrivez. Et il y a des colonnes avec des types de données.
Grâce à ce que nous avons décrit, SQLAlchemy peut maintenant et en sait beaucoup. Si nous spécifions une clé étrangère ici, elle saurait toujours comment nos tables sont connectées les unes aux autres. Et elle saurait dans quel ordre quelque chose doit être fait.

SQLAlchemy a également Engine. Important: ce que nous avons dit à propos des demandes peut être utilisé séparément, et Engine peut être utilisé séparément. Et vous pouvez tout utiliser ensemble, personne ne vous interdit. Autrement dit, Engine sait se connecter directement au serveur et vous offre exactement la même interface. Non, bien sûr, différents pilotes essaient de se conformer à DBAPI, il existe un PEP en Python qui fait des recommandations. Mais Engine vous offre exactement la même interface pour toutes les bases de données, et c'est très pratique.

Le dernier jalon majeur est Dialect. C'est ainsi que le moteur communique avec différentes bases de données. Il y a différentes langues, différentes personnes et différents dialectes ici.
Voyons à quoi ça sert.

Voici à quoi ressemblera une insertion normale. Si nous voulons ajouter une nouvelle ligne, la plaque que nous avons décrite précédemment, dans laquelle il y avait un champ ID et email, ici nous spécifions l'email, faisons Insertion, et récupérons immédiatement tout ce que nous avons inséré.
Et si nous voulons ajouter beaucoup de lignes? Aucun problème.

Vous pouvez simplement transférer une liste de dictées ici. On dirait du code parfait pour un stylo super simple. Les données sont arrivées, ont passé une sorte de validation, un schéma JSON et tout est entré dans la base de données. Super facile.
Certaines requêtes sont assez complexes. Parfois, une demande peut même être visualisée avec une impression, parfois vous devez la compiler. Ce n'est pas difficile. Alchemy vous permet de faire tout cela. Dans ce cas, nous avons compilé la requête et vous pouvez voir ce qui va réellement voler dans la base de données.

La demande de données semble assez simple. Littéralement deux lignes, vous pouvez même en écrire une.

Revenons à notre question sur comment, par exemple, écrire une requête PATCH pour 15 champs. Ici, vous ne devez écrire que le nom du champ, sa clé et sa valeur. C'est tout ce qui est nécessaire. Pas de fichiers, pas de construction de chaînes, rien du tout. Cela semble pratique.
Peut-être la fonctionnalité Alchemy la plus importante que j'utilise quotidiennement dans mon travail est la décomposition et l'expansion des requêtes.

Supposons que vous écriviez une interface dans PostgreSQL, votre application doit en quelque sorte autoriser une personne et lui permettre d'exécuter CRUD. D'accord, il n'y a pas grand chose à décomposer.
Lorsque vous écrivez une application très complexe qui utilise la gestion des versions de données, un tas d'abstractions différentes, les requêtes que vous allez générer peuvent consister en un grand nombre de sous-requêtes. Les sous-requêtes sont jointes aux sous-requêtes. Il existe différentes tâches. Et parfois, la décomposition des requêtes aide beaucoup, elle permet une grande séparation entre la logique et la conception de code.
Pourquoi ça marche comme ça? Lorsque vous appelez la méthode users_table.select (), par exemple, elle renvoie un objet. Lorsque vous appelez une autre méthode sur l'objet résultant, telle que where (), elle renvoie un objet complètement nouveau. Tous les objets de requête sont immuables. Par conséquent, vous pouvez construire sur tout ce que vous voulez.
Migrations d'alambic
Donc, nous avons traité SQLAlchemy et maintenant nous pouvons enfin écrire des migrations Alembic.

Commencer à utiliser Alembic n'est pas du tout difficile, surtout si vous avez déjà décrit vos tables, comme nous l'avons dit précédemment, et spécifié un objet MetaData. Vous venez d'installer alambic, appelez alambic init alambic. alambic - le nom du module, c'est la ligne de commande, vous l'aurez. init est une commande. Le dernier argument est le dossier dans lequel le placer.
Lorsque vous appelez cette commande, vous aurez plusieurs fichiers, que nous allons examiner de plus près maintenant.

Il y aura une configuration générale dans alembic.ini. script_location est exactement là où vous souhaitez qu'il aille. Ensuite, il y aura un modèle pour les noms de vos migrations que vous allez générer et des informations pour vous connecter à la base de données.

Il existe également un modèle pour les nouvelles migrations. Vous dites: "Je veux une nouvelle migration" et Alembic la créera selon un certain modèle. Vous pouvez personnaliser tout cela, c'est très simple. Vous allez dans ce fichier et éditez tout ce dont vous avez besoin. Toutes les variables qui peuvent être spécifiées ici se trouvent dans la documentation. C'est la première partie. Il y a une sorte de commentaire en haut pour qu'il soit pratique de voir ce qui se passe là-bas. Ensuite, il y a un ensemble de variables qui devraient être dans chaque migration - révision, down_revision. Nous travaillerons avec eux aujourd'hui. En outre - méta-informations supplémentaires.

Les méthodes les plus importantes sont la mise à niveau et la rétrogradation. Alembic remplacera ici la différence que l'objet MetaData trouve entre la description de votre schéma et ce qui se trouve dans la base de données.

env.py est le fichier le plus intéressant d'Alembic. Il contrôle la progression de l'exécution de la commande et vous permet de la personnaliser vous-même. C'est dans ce fichier que vous connectez votre objet MetaData. Comme je l'ai déjà dit, l'objet MetaData est le registre de toutes les entités de votre base de données.
Vous connectez cet objet MetaData ici. Et à partir de ce moment, Alembic comprend que les voilà, mes modèles, les voilà, mes assiettes. Il comprend avec quoi il travaille. Ensuite, Alembic a un code qui appelle Alembic soit hors ligne, soit en ligne. Nous allons maintenant considérer également tout cela.
C'est exactement la ligne où vous devez connecter les métadonnées dans votre projet. Ne vous inquiétez pas si quelque chose n'est pas très clair, j'ai tout mis dans un projet et l'ai posté sur GitHub . Vous pouvez le cloner et le voir, tout ressentir.

Qu'est-ce que le mode en ligne? En mode en ligne, Alembic se connecte à la base de données spécifiée dans le paramètre sqlalchemy.url dans le fichier alembic.ini et lance les migrations.
Pourquoi examinons-nous ce morceau de code? Alembic peut être personnalisé de manière très flexible.
Imaginez que vous ayez une application qui doit vivre dans différents schémas de base de données. Par exemple, vous souhaitez que de nombreuses instances d'application s'exécutent en même temps et chacune d'elles vit dans son propre schéma. Cela peut être pratique et nécessaire.
Cela ne vous coûte rien du tout. Après avoir appelé la méthode context.begin_transaction (), vous pouvez écrire la commande "SET search_path = SCHEMA", qui indiquera à PostgreSQL d'utiliser un schéma par défaut différent. Et c'est tout. Désormais, votre application vit dans un schéma complètement différent, les migrations se déroulent dans un schéma différent. C'est une question en une ligne.

Il existe également un mode hors ligne. Notez qu'Alembic n'utilise pas Engine ici. Vous pouvez simplement lui transmettre un lien ici. Vous pouvez bien sûr transférer le moteur également, mais il ne se connecte nulle part. Il génère simplement des requêtes brutes que vous pouvez ensuite exécuter quelque part.

Donc, vous avez Alembic et quelques MetaData avec des tables. Et vous souhaitez enfin générer des migrations pour vous-même. Vous exécutez cette commande, et c'est essentiellement tout. Alembic ira à la base de données et verra ce qu'il y a. Existe-t-il son label spécial «alembic_versions», qui vous dira que les migrations ont déjà été déployées dans cette base de données? Va voir quelles tables existent là-bas. Va voir les données dont vous avez besoin dans la base de données. Il analysera tout cela, générera un nouveau fichier, uniquement basé sur ce modèle, et vous aurez une migration. Bien sûr, vous devez absolument regarder ce qui a été généré lors de la migration, car Alembic ne génère pas toujours ce que vous voulez. Mais la plupart du temps, cela fonctionne.

Qu'avons-nous généré? Il y avait un signe d'utilisateurs. Lorsque nous avons généré la migration, j'ai indiqué le message initial. La migration sera nommée initial.py avec un autre modèle précédemment spécifié dans alembic.ini.
Il existe également des informations sur l'ID de cette migration. down_revision = None - c'est la première migration.
La prochaine diapositive sera la partie la plus importante: mise à niveau et rétrogradation.

Dans la mise à niveau, nous voyons que nous avons une plaque en cours de création. En cas de rétrogradation, ce signe est supprimé. Alembic, par défaut, ajoute spécifiquement de tels commentaires pour que vous y alliez, éditez-le, supprimez au moins ces commentaires. Et juste au cas où, nous avons examiné la migration, nous nous sommes assurés que tout vous convient. Il s'agit d'une seule équipe. Vous avez déjà une migration.

Après cela, vous souhaiterez probablement appliquer cette migration. Ça ne pourrait pas être plus simple. Vous avez juste besoin de dire: tête de mise à niveau d'alambic. Il appliquera absolument tout.
Si nous disons tête, il essaiera de mettre à jour la migration la plus récente. Si nous nommons une migration spécifique, elle sera mise à jour.
Il existe également une commande de rétrogradation - au cas où vous changez d'avis, par exemple. Tout cela se fait dans les transactions et cela fonctionne très simplement.

Donc, vous avez des migrations, vous savez comment les exécuter. Vous avez une application et vous posez, par exemple, cette question: j'ai un CI, des tests sont en cours et je ne sais même pas si je veux, par exemple, exécuter des migrations automatiquement? Peut-être vaut-il mieux le faire à la main?
Il y a ici différents points de vue. Cela vaut probablement la peine de respecter la règle: si vous n'avez pas un accès facile, la possibilité d'accéder à la voiture à partir de la base de données, il est préférable, bien sûr, de le faire automatiquement.
Si vous avez accès, vous créez un service qui fonctionne dans le cloud, et vous pouvez y accéder à partir d'un ordinateur portable que vous avez toujours avec vous, alors vous pouvez le faire vous-même et ainsi vous donner plus de contrôle.
En général, il existe de nombreux outils pour le faire automatiquement. Par exemple, dans le même Kubernetes. Il existe des conteneurs init qui peuvent faire cela et dans lesquels vous pouvez exécuter ces commandes. Vous pouvez ajouter une commande de lancement directement à Docker pour ce faire.
Il vous suffit de prendre en compte: si vous appliquez automatiquement les migrations, vous devez réfléchir à ce qui se passe si, par exemple, vous souhaitez revenir en arrière, mais que vous ne pouvez pas. Par exemple, vous aviez une plaque signalétique de 500 gigaoctets. Vous vous êtes dit: d'accord, ces données ne sont plus nécessaires pour la logique métier, vous pouvez probablement les supprimer. Ils l'ont pris et l'ont laissé tomber. Ou changé le type d'une colonne, qui a changé avec la perte de données. Par exemple, il y avait une longue file d'attente, mais elle est devenue courte. Ou quelque chose est parti. Ou vous avez supprimé une colonne. Vous ne pouvez pas revenir en arrière même si vous le souhaitez.
À un moment donné, j'ai fait des produits pour sur site, qui sont installés par un fichier exe pour les personnes directement sur la machine. Une fois que vous avez compris: oui, vous avez écrit la migration, elle est entrée en production, les gens l'ont déjà installée. Dans les cinq prochaines années, cela peut fonctionner pour eux selon le SLA, et vous voulez changer quelque chose, quelque chose pourrait être mieux. En ce moment, vous réfléchissez à la manière de gérer les changements irréversibles.

Pas de science-fusée ici non plus. L'idée est que vous pouvez éviter d'utiliser ces colonnes ou d'utiliser des tableaux autant que possible. Arrêtez de les contacter. Vous pouvez, par exemple, marquer des champs avec un décorateur spécial dans l'ORM. Il dira dans les journaux que vous sembliez vouloir ne pas toucher à ce champ, mais vous faites toujours référence à lui. Créez simplement une tâche dans le backlog et supprimez-la un jour.
Vous aurez, le cas échéant, le temps de reculer. Et si tout se passe bien, vous ferez calmement cette tâche plus tard dans l'arriéré. Faites une autre migration qui supprimera réellement tout.
Passons maintenant à la question la plus importante: pourquoi et comment tester les migrations?

Ceci est fait par quelques-uns de ceux à qui j'ai demandé. Mais il vaut mieux le faire. C'est une règle écrite dans la douleur, le sang et la sueur. Utiliser la migration en production est toujours risqué. Vous ne savez jamais comment cela pourrait se terminer. Même une très bonne migration sur une production de travail parfaitement normale, lorsque vous avez configuré CI, peut secouer.
Le fait est que lorsque vous testez des migrations, vous pouvez même télécharger, par exemple, une étape ou une partie de la production. La production peut être volumineuse, vous ne pouvez pas la télécharger complètement pour des tests ou d'autres tâches. En règle générale, les bases de développement ne sont pas vraiment des bases de production. Ils n'ont pas beaucoup de ce qui aurait pu s'accumuler au fil des ans.

Il peut s'agir de données corrompues, lorsque nous avons migré quelque chose, ou d'anciens logiciels qui ont amené les données dans un état incohérent. Il peut également s'agir de dépendances implicites - si quelqu'un a oublié d'ajouter une clé étrangère. Il pense que c'est lié, mais ses collègues, par exemple, ne le savent pas. Les champs sont également appelés tout à fait par accident, il n'est généralement pas clair qu'ils soient connectés.
Ensuite, quelqu'un a décidé d'ajouter une sorte d'index directement à la production, car "ça ralentit maintenant, mais que faire si ça commence à fonctionner plus vite?" Peut-être que j'exagère, mais les gens changent parfois quelque chose directement dans les bases de données.
Il y a, bien sûr, des erreurs dans les outils, dans la migration de schéma. Pour être honnête, je n'ai pas rencontré cela. Habituellement, il y avait les trois premiers problèmes. Et peut-être plus d'erreurs dans les hypothèses sur la façon dont les données devraient être transférées.
Lorsque vous avez un modèle objet très volumineux, il peut être difficile de tout garder à l'esprit. Il est difficile de rédiger constamment une documentation à jour. La documentation la plus à jour est votre code, et il n’a pas toujours une logique métier entièrement écrite: quoi et comment fonctionner, qui avait quoi en tête.

Que pouvons-nous vérifier? Au moins le fait que la migration commence. C'est déjà génial. Et qu'il n'y a pas de fautes de frappe stupides dans le code. Nous pouvons vérifier qu'il existe une méthode downgrade () valide, que tous les types de données créés par SQLAlchemy sont supprimés dans la méthode downgrade ().
SQLAlchemy fait beaucoup de belles choses. Par exemple, lorsque vous décrivez une table et spécifiez un type de colonne Enum, SQLAlchemy crée automatiquement un type de données pour cette énumération dans PostgreSQL. Mais le code pour supprimer ce type de données dans la méthode downgrade () ne sera pas généré automatiquement.
Vous devez vous souvenir et vérifier ceci: lorsque vous souhaitez annuler et réappliquer la migration, une tentative de création d'un type de données existant dans la méthode upgrade () lèvera une exception. Et surtout, si la migration modifie des données, vous devez vérifier que les données changent correctement lors de la mise à niveau. Et il est très important de vérifier qu'ils reviennent correctement en rétrogradation sans effets secondaires.

Avant de passer aux tests eux-mêmes, voyons comment se préparer au mieux à les écrire. J'ai vu de nombreuses approches à ce sujet. Certaines personnes créent une base, des plaques, puis écrivent un luminaire qui nettoie tout, utilisent une sorte de luminaires à application automatique . Mais le moyen idéal qui vous protégera à 100% et effectuera des tests dans un espace complètement isolé est de créer une base de données séparée.
Il existe un module sqlalchemy_utils génial qui peut créer et supprimer des bases de données. Dans PostgreSQL, il vérifie également: si l'un des clients s'est endormi et ne s'est pas déconnecté, il ne plantera pas avec l'erreur «quelqu'un utilise la base de données, je ne peux rien faire avec, je ne peux pas la supprimer». Au lieu de cela, il verra calmement qui s'est connecté à eux, déconnectera ces clients et supprimera calmement la base.
Construire une base de données et appliquer une migration à chaque test n'est pas toujours un processus rapide. Cela peut être résolu comme suit: PostgreSQL prend en charge la création de nouvelles bases de données à partir d'un modèle, vous pouvez donc diviser la préparation de la base de données en deux montages.
Le premier appareil s'exécute une fois pour exécuter tous les tests (scope = session), crée une base de données et y applique des migrations. Le deuxième appareil (portée = fonction) crée des bases directement pour chaque test en fonction de la base du premier appareil.
La création d'une base de données à partir d'un modèle est très rapide et permet de gagner du temps lors de l'application des migrations pour chaque test.

Si nous parlons simplement de la façon dont nous pouvons créer temporairement une base de données, alors nous pouvons écrire un tel appareil. Que se passe t-il ici? Nous allons générer un nom aléatoire. Nous ajoutons, juste au cas où, à la fin de pytest, de sorte que lorsque nous allons à localhost à nous-mêmes via un Postico, nous pouvons comprendre ce qui a été créé par des tests et ce qui ne l'était pas.
Ensuite, nous générons à partir du lien avec des informations sur la connexion à la base de données, que la personne a montré, une nouvelle, déjà avec une nouvelle base de données. Nous le créons et l'envoyons simplement à des tests. Une fois qu'une personne a travaillé avec cette base de données, nous la supprimons.

Nous pouvons également préparer le moteur à se connecter à cette base de données. Autrement dit, dans cet appareil, nous nous référons à l'appareil précédent utilisé comme dépendance. Nous créons un moteur et l'envoyons à des tests.

Alors, quels tests pouvons-nous écrire? Le premier test n'est qu'une brillante invention de mon collègue. Depuis son apparition, je pense avoir oublié les problèmes liés aux migrations.
C'est un test très simple. Vous l'ajoutez une fois à votre projet. C'est dans le projet sur GitHub... Vous pouvez simplement le faire glisser vers vous, ajouter et oublier, peut-être, environ 80% des problèmes.
Il fait une chose très simple: il obtient une liste de toutes les migrations et commence à les parcourir. Mise à niveau des appels, rétrogradation, mise à niveau.

Par exemple, nous avons cinq migrations. Voyons comment cela fonctionnera. Voici la première migration. Nous l'avons rempli. Annulez la première migration, réexécutez-la. Que s'est-il passé ici? En fait, nous avons vu ici que la personne a correctement implémenté la méthode downgrade (), car deux fois, par exemple, il n'aurait pas été possible de créer des tables.
Nous voyons que si une personne a créé certains types de données, elle les a également supprimés, car il n'y a pas de fautes de frappe et en général, cela fonctionne du moins d'une manière ou d'une autre.
Ensuite, le test continue. Il effectue la deuxième migration, y accède immédiatement, recule d'un pas, recommence. Et cela se produit autant de fois que vous avez des migrations.
Le but de ce test est de trouver des erreurs de base, des problèmes lors de la modification de la structure des données.
L'escalier commence sur une base vide et est généralement très rapide. Autrement dit, ce test concerne davantage la structure des données. Il ne s'agit pas de modifier les données dans les migrations. Mais dans l'ensemble, cela peut très bien vous sauver la vie.
Si vous voulez une solution rapide, c'est tout. Cette règle est. En règle générale: insérez-le dans votre projet, et cela devient plus facile pour vous.

Ce test ressemble à quelque chose comme ça. Nous obtenons toutes les révisions, générons la configuration Alembic. Voici ce que nous avons vu auparavant, le fichier alembic.ini, voici la fonction get_alembic_config, il lit ce fichier, y ajoute notre base temporaire, car là nous avons spécifié le chemin vers la base. Et après cela, nous pouvons utiliser les commandes Alembic.
La commande précédemment exécutée - la tête de mise à niveau d'alambic - peut également être importée en toute sécurité. Malheureusement, cette diapositive ne correspond pas à toutes les importations, mais croyez-moi sur parole. C'est juste de la mise à niveau d'importation d'alembic.com. Vous traduisez la configuration là-bas, dites où passer la mise à niveau. Puis dites: rétrograder.
Avec la rétrogradation, la migration est restaurée vers down_revision, c'est-à-dire vers la révision précédente, ou vers "-1".
"-1" est une autre façon de dire à Alembic d'annuler la migration actuelle. Il est très pertinent lorsque la première migration démarre, sa down_revision est None, tandis que l'API Alembic ne permet pas de passer None à la commande downgrade.
Ensuite, la commande de mise à niveau est exécutée à nouveau.
Voyons maintenant comment tester les migrations avec des données.

Les migrations de données sont le genre de chose qui semble généralement très simple, mais qui fait le plus mal. Il semblerait que vous écriviez certains sélectionnez, insérez, prenez des données dans une table, transférez-les dans une autre dans un format légèrement différent - quoi de plus simple?
Il reste à dire à propos de ce test que, contrairement au précédent, son développement est très coûteux. Quand j'ai fait de grandes migrations, il m'a parfois fallu six heures pour regarder tous les invariants, c'est correct de tout décrire. Mais quand je roulais déjà ces migrations, j'étais calme.

Comment fonctionne ce test? L'idée est que nous appliquons toutes les migrations jusqu'à celle que nous voulons maintenant tester. Nous insérons dans la base de données un ensemble de données qui changeront. Nous pouvons penser à insérer des données supplémentaires qui pourraient changer implicitement. Ensuite, nous mettons à niveau. Nous vérifions que les données ont été modifiées correctement, exécutons la rétrogradation et vérifions que les données ont été modifiées correctement.

Le code ressemble à quelque chose comme ça. Autrement dit, il y a aussi un paramétrage par révision, il y a un ensemble de paramètres. Nous acceptons notre moteur ici, acceptons la migration avec laquelle nous voulons commencer les tests.
Puis rev_head, c'est ce que nous voulons tester. Et puis trois rappels. Ce sont les rappels que nous définissons quelque part, et ils seront appelés une fois que quelque chose est fait. Nous pouvons vérifier ce qui se passe là-bas.
Où puis-je voir un exemple?
J'ai tout emballé dans un exemple sur GitHub . Il n'y a pas vraiment beaucoup de code là-dedans, mais il est assez difficile de l'ajouter à la diapositive. J'ai essayé d'endurer le plus élémentaire. Vous pouvez aller sur GitHub et voir comment cela fonctionne dans le projet lui-même, ce sera le moyen le plus simple.
À quoi d'autre vaut-il la peine de prêter attention? Au démarrage, Alembic recherche le fichier de configuration alembic.ini dans le dossier où il a été lancé. Bien sûr, vous pouvez spécifier le chemin à l'aide de la variable d'environnement ALEMBIC_CONFIG, mais ce n'est pas toujours pratique et évident.
Autre problème: les informations de connexion à la base de données sont spécifiées dans alembic.ini, mais vous avez souvent besoin de pouvoir travailler avec plusieurs bases de données à tour de rôle. Par exemple, déployez les migrations vers l'étape, puis vers la production. En général, vous pouvez spécifier les informations de connexion dans la variable d'environnement SQLALCHEMY_URL, mais cela n'est pas très évident pour les utilisateurs finaux de votre logiciel.
Il est également beaucoup plus intuitif pour les utilisateurs finaux d'utiliser l'utilitaire "$ project $ -db" que "alambic".
En regardant les exemples du projet, jetez un œil à l'utilitaire staff-db. Ceci est une mince enveloppe autour de l'Alembic et une autre façon de personnaliser Alembic pour vous. Par défaut, il recherche le fichier alembic.ini dans le projet par rapport à son emplacement. Quel que soit le dossier que les utilisateurs appellent, elle trouvera elle-même le fichier de configuration. De plus, staff-db ajoute un argument --db-url, avec lequel vous pouvez spécifier des informations pour vous connecter à la base de données. Et, surtout, voyez-le en passant l'option --help généralement acceptée. Après tout, le nom de l'utilitaire est intuitif.
Toutes les commandes de projet exécutables commencent par le nom du module "staff": staff-api, qui exécute l'API REST, et staff-db, qui gère l'état de base. Comprenant ce modèle, le client écrira le nom de votre programme et pourra voir tous les utilitaires disponibles en appuyant sur la touche TAB, même s'il oublie le nom complet. J'ai tout, merci.