
Cet article décrira l'expérience de la création d'un réseau de neurones pour la reconnaissance faciale, pour trier toutes les photos d'une conversation VK pour trouver une personne spécifique. Sans aucune expérience dans l'écriture de réseaux de neurones et une connaissance minimale de Python.
introduction
Nous avons un ami, qui s'appelle Sergei, qui aime se photographier de manière inhabituelle et envoyer une conversation, et pimente également ces photos avec des phrases d'entreprise. Donc, une des soirées sur la discorde, nous avons eu une idée - créer un public dans VK, où nous pourrions poster Sergey avec ses citations. Les 10 premiers messages du report étaient faciles, mais il est alors devenu clair qu'il ne servait à rien de passer en revue toutes les pièces jointes dans une conversation avec vos mains. Il a donc été décidé d'écrire un réseau de neurones pour automatiser ce processus.
Plan
- Obtenir des liens vers des photos à partir d'une conversation
- Télécharger des photos
- Écrire un réseau de neurones
Avant de commencer le développement
, Python pip. , 0, ,
1. Obtenir des liens vers des photos
Nous voulons donc récupérer toutes les photos de la conversation, la méthode messages.getHistoryAttachments nous convient , qui retourne les matériaux du dialogue ou de la conversation.
Depuis le 15 février 2019, Vkontakte a interdit l'accès aux messages pour les applications qui n'ont pas passé la modération. Pour contourner le problème , je peux suggérer vkhost , qui vous aidera à obtenir un jeton de messagers tiers
Avec le jeton reçu sur vkhost, nous pouvons collecter la demande d'API dont nous avons besoin à l'aide de Postman . Vous pouvez, bien sûr, tout remplir avec des stylos sans lui, mais pour plus de clarté, nous l'utiliserons
.
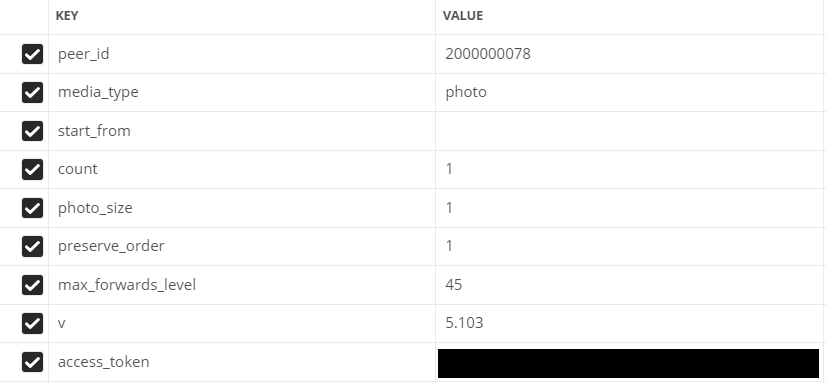
- peer_id - identifiant de destination
Pour une conversation: 2 000 000 000 + identifiant de conversation (visible dans la barre d'adresse).
Pour l'utilisateur: identifiant utilisateur. - media_type - type de média
Dans notre cas, photo
- start_from - offset pour sélectionner plusieurs éléments.
Laissez-le vide pour le moment.
- count - le nombre d'objets reçus
Maximum 200, c'est ce que nous allons utiliser
- photo_sizes - indicateur pour renvoyer toutes les tailles du tableau
1 ou 0. Nous utilisons 1
- préserver_order - indicateur indiquant si les pièces jointes doivent être retournées dans leur ordre d'origine
1 ou 0. Nous utilisons 1
- v - version api vk
1 ou 0. Nous utilisons 1
Champs remplis dans Postman
Aller à l'écriture du code
Pour plus de commodité, tout le code sera divisé en plusieurs scripts distincts.
Utilisera le module json (pour décoder les données) et la bibliothèque de requêtes (pour faire des requêtes http)
Code Listing s'il y a moins de 200 photos dans une conversation / dialogue
import json
import requests
val = 1 #
Fin = open("input.txt","a") #
# GET API response
response = requests.get("https://api.vk.com/method/messages.getHistoryAttachments?peer_id=2000000078&media_type=photo&start_from=&count=10&photo_size=1&preserve_order=1&max_forwards_level=45&v=5.103&access_token=_")
items = json.loads(response.text) # JSON
# GET ,
for item in items['response']['items']: # items
link = item['attachment']['photo']['sizes'][-1]['url'] # ,
print(val,':',link) #
Fin.write(str(link)+"\n") #
val += 1 #
S'il y a plus de 200 photos
import json
import requests
next = None #
def newfunc():
val = 1 #
global next
Fin = open("input.txt","a") #
# GET API response
response = requests.get(f"https://api.vk.com/method/messages.getHistoryAttachments?peer_id=2000000078&media_type=photo&start_from={next}&count=200&photo_size=1&preserve_order=1&max_forwards_level=44&v=5.103&access_token=_")
items = json.loads(response.text) # JSON
if items['response']['items'] != []: #
for item in items['response']['items']: # items
link = item['attachment']['photo']['sizes'][-1]['url'] # ,
print(val,':',link) #
val += 1 #
Fin.write(str(link)+"\n") #
next = items['response']['next_from'] #
print('dd',items['response']['next_from'])
newfunc() #
else: #
print(" ")
newfunc()Il est temps de télécharger des liens
2. Téléchargement d'images
Pour télécharger des photos, nous utilisons la bibliothèque urllib
import urllib.request
f = open('input.txt') #
val = 1 #
for line in f: #
line = line.rstrip('\n')
# "img"
urllib.request.urlretrieve(line, f"img/{val}.jpg")
print(val,':','') #
val += 1 #
print("")
Le processus de téléchargement de toutes les images n'est pas le plus rapide, surtout si les photos sont 8330. L'espace pour ce cas est également nécessaire, si le nombre de photos est le même que le mien ou plus, je recommande de libérer 1,5 à 2 Go pour cela . Le

travail approximatif est terminé, vous pouvez maintenant commencer vous-même intéressant - écrire un réseau de neurones
3. Écriture d'un réseau neuronal
Après avoir parcouru de nombreuses bibliothèques et options différentes, il a été décidé d'utiliser la bibliothèque de reconnaissance faciale
Qu'est-ce que ça peut faire?
À partir de la documentation, nous examinerons les caractéristiques les plus élémentaires
Recherche de visages dans les photographies
Peut trouver un nombre illimité de visages sur une photo, même en cas de flou.

Identification des visages sur une photographie.
Peut reconnaître à qui appartient un visage sur une photo.

Pour nous, le moyen le plus approprié est l' identification des visages
Entraînement
D'après les exigences de la bibliothèque, Python 3.3+ ou Python 2.7 est requis.En
ce qui concerne les bibliothèques, la reconnaissance de visage et le PIL mentionnés ci-dessus seront utilisés pour travailler avec des images.
La bibliothèque de reconnaissance faciale n'est pas officiellement prise en charge sur Windows , mais cela a fonctionné pour moi. Tout fonctionne de manière stable avec macOS et Linux.
Explication de ce qui se passe
Pour commencer, nous devons définir un classificateur pour rechercher une personne par laquelle une vérification supplémentaire des photos aura déjà lieu.
Je recommande de choisir la photo la plus claire possible d'une personne en vue frontale.Lors du téléchargement d'une photo, la bibliothèque divise les images en coordonnées des traits du visage d'une personne (nez, yeux, bouche et menton)

Eh bien, alors la question est petite, il ne reste plus qu'à appliquer une méthode similaire à la photo que nous voulons comparer avec notre classificateur. Ensuite, nous laissons le réseau neuronal comparer les traits du visage par coordonnées.
Eh bien, le code lui-même:
import face_recognition
from PIL import Image #
find_face = face_recognition.load_image_file("face/sergey.jpg") #
face_encoding = face_recognition.face_encodings(find_face)[0] # ,
i = 0 #
done = 0 #
numFiles = 8330 # -
while i != numFiles:
i += 1 #
unknown_picture = face_recognition.load_image_file(f"img/{i}.jpg") #
unknown_face_encoding = face_recognition.face_encodings(unknown_picture) #
pil_image = Image.fromarray(unknown_picture) #
#
if len(unknown_face_encoding) > 0: #
encoding = unknown_face_encoding[0] # 0 ,
results = face_recognition.compare_faces([face_encoding], encoding) #
if results[0] == True: #
done += 1 #
print(i,"-"," !")
pil_image.save(f"done/{int(done)}.jpg") #
else: #
print(i,"-"," !")
else: #
print(i,"-"," !")
Il est également possible de tout exécuter grâce à une analyse approfondie sur une carte vidéo, pour cela, vous devez ajouter le paramètre model = "cnn" et changer le fragment de code de l'image avec laquelle nous voulons rechercher la bonne personne:
unknown_picture = face_recognition.load_image_file(f"img/{i}.jpg") #
face_locations = face_recognition.face_locations(unknown_picture, model= "cnn") # GPU
unknown_face_encoding = face_recognition.face_encodings(unknown_picture) # Résultat
Pas de GPU. Par temps, le réseau de neurones est allé à travers et triées 8330 des photos en 1 heure 40 minutes et en même temps trouvé 142 photos, 62 d'entre eux à l'image de la personne désirée. Bien sûr, il y a eu de faux positifs sur les mèmes et d'autres personnes.
C GPU. Le temps de traitement a pris beaucoup plus, 17 heures et 22 minutes, et j'ai trouvé 230 photographies dont 99 sont les personnes dont nous avons besoin.
En conclusion, on peut dire que le travail n'a pas été fait en vain. Nous avons automatisé le processus de tri de 8330 photos, ce qui est bien mieux que de les trier vous-même.
Vous pouvez également télécharger l'intégralité du code source sur github