
J'ai toujours été fasciné par les défaillances du système et les bizarreries de leur comportement, en particulier lorsqu'ils fonctionnent dans leurs conditions normales. J'ai récemment vu une des diapositives de présentation d'Ian Goodfellow, que j'ai trouvée très drôle. Le bruit visuel aléatoire a été transmis au réseau neuronal entraîné, et elle l'a reconnu comme l'un des objets qu'elle connaissait. De nombreuses questions se posent immédiatement ici. Les différents réseaux de neurones entraînés verront-ils le même objet? Quel est le niveau de confiance maximal dans le réseau de neurones que ce bruit aléatoire est bien un objet reconnu? Et qu'est-ce que le réseau neuronal "voit" là-bas?
De ma curiosité à ce sujet, ce disque est né. Heureusement, ces expériences sont très faciles à faire avec PyTorch.... Pour visualiser pourquoi le réseau neuronal classe les objets d'une certaine manière, j'utilise le cadre d' interprétabilité du modèle Captum . Le code peut être téléchargé depuis Github .
Importance des questions
Vous pourriez vous demander pourquoi ces questions sont importantes. Dans de nombreux cas, les développeurs ne créent pas de modèles à partir de zéro. Ils choisissent les plates-formes et les réseaux pré-formés du zoo modèle comme points de départ. Cela permet de gagner du temps - vous n'avez pas besoin de collecter des données et d'effectuer une formation initiale du réseau neuronal. Cependant, cela signifie également que des problèmes inattendus peuvent survenir dans des endroits inattendus. Selon la façon dont ce modèle est utilisé, des problèmes de sécurité peuvent survenir au cours du processus.
Modèles pré-entraînés
Les modèles pré-entraînés sont faciles à utiliser et peuvent soumettre rapidement des données pour classification. Dans ce cas, vous n'avez pas besoin de définir des modèles et de les former - tout cela a déjà été fait avant vous et ils sont prêts à être utilisés immédiatement après le déploiement. Les modèles pré-entraînés de la bibliothèque Torchvision sont entraînés sur un ensemble d'images de la base de données Imagenet , divisé en 1000 catégories... Il est important de se rappeler que cette formation impliquait l'identification d'un seul objet dans une image, et non l'analyse d'images complexes contenant divers objets. Dans le second cas, vous pouvez également obtenir des résultats intéressants, mais c'est un sujet complètement différent. Le téléchargement de modèles pré-entraînés à partir de la bibliothèque Torchvision est très simple. Il vous suffit d'importer le modèle sélectionné en définissant le paramètre prétrainé sur True. J'ai également inclus un mode d'évaluation dans les modèles, car il n'y a pas de courbe d'apprentissage pendant les tests.
J'ai d'abord une ligne de code qui choisit d'utiliser cuda ou cpu, selon qu'un GPU est disponible. Pour des tests aussi simples, un GPU n'est pas nécessaire, mais comme j'en ai un, je l'utilise.
device = "cuda" if torch.cuda.is_available() else "cpu"
import torchvision.models as models
vgg16 = models.vgg16(pretrained=True)
vgg16.eval()
vgg16.to(device)
Une liste des modèles pré-entraînés de Torchvision peut être trouvée ici . Je ne voulais pas utiliser tous les réseaux de neurones pré-entraînés, c'est déjà trop. J'ai choisi les cinq suivants:
- vgg16
- resnet18
- alexnet
- densenet
- début
Je n'ai utilisé aucune méthodologie particulière pour choisir les réseaux de neurones. Par exemple, Vgg16 et Inception sont souvent utilisés dans différents exemples, et ils sont tous différents.
Comment créer des images avec du bruit
Nous aurons besoin d'un moyen de générer automatiquement des images contenant du bruit pouvant être transmises aux réseaux de neurones. Pour ce faire, j'ai utilisé une combinaison des bibliothèques Numpy et PIL, et j'ai écrit une petite fonction qui renvoie une image remplie de bruit aléatoire.
import numpy as np
from PIL import Image
def gen_image():
image = (np.random.standard_normal([256, 256, 3]) * 255).astype(np.uint8)
im = Image.fromarray(image)
return im
Vous vous retrouvez avec quelque chose comme ce qui suit:

Conversion d'images
Après cela, nous devons convertir nos images en tenseur et les normaliser. Le code suivant peut être utilisé non seulement sur le bruit aléatoire, mais également sur toute image que nous voulons alimenter vers des réseaux de neurones pré-entraînés (c'est pourquoi le code utilise les valeurs Resize et CenterCrop).
def xform_image(image):
transform = transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])])
new_image = transform(image).to(device)
new_image = new_image.unsqueeze_(0)
return new_imageNous obtenons des prédictions
Après avoir préparé les images transformées, il est facile d'obtenir des prédictions à partir du modèle déplié. Dans ce cas, la fonction xform_image est supposée renvoyer image_xform. Dans le code que j'ai utilisé pour les tests, j'ai réparti le travail entre ces deux fonctions, mais ici je les assemble pour plus de facilité. Nous devons essentiellement alimenter l'image transformée vers le réseau, exécuter la fonction softmax, utiliser la fonction topk pour obtenir le score et l'ID d'étiquette prédite pour le meilleur résultat.
with torch.no_grad():
vgg16_res = vgg16(image_xform)
vgg16_output = F.softmax(vgg16_res, dim=1)
vgg16score, pred_label_idx = torch.topk(vgg16_output, 1)
résultats
Eh bien, nous voyons maintenant comment générer des images bruyantes et les envoyer à un réseau pré-entraîné. Alors quels sont les résultats? Pour ce test, j'ai décidé de générer 1000 images bruyantes, de les faire passer à travers 5 réseaux pré-entraînés sélectionnés et de les insérer dans une trame de données Pandas pour une analyse rapide. Les résultats étaient intéressants et quelque peu inattendus.
| vgg16 | resnet18 | alexnet | densenet | début | |
|---|---|---|---|---|---|
| compter | 1000,000000 | 1000,000000 | 1000,000000 | 1000,000000 | 1000,000000 |
| signifier | 0,226978 | 0,328249 | 0,147289 | 0,409413 | 0,020204 |
| std | 0,067972 | 0,071808 | 0,038628 | 0,148315 | 0,016490 |
| min | 0,074922 | 0,127953 | 0,061019 | 0,139161 | 0,005963 |
| 25% | 0,178240 | 0,278830 | 0,120568 | 0,291042 | 0,011641 |
| 50% | 0,223623 | 0,324111 | 0,143090 | 0,387705 | 0,015880 |
| 75% | 0,270547 | 0,373325 | 0,171139 | 0,511357 | 0,022519 |
| max | 0,438011 | 0,580559 | 0,328568 | 0,868025 | 0,198698 |
Comme vous pouvez le voir, certains des réseaux de neurones ont décidé que ce bruit représentait en fait quelque chose de spécifique avec un niveau de confiance assez élevé. Resnet18 et densenet ont tous deux atteint un pic à 50%. C'est bien beau, mais qu'est-ce que ces réseaux «voient» exactement dans le bruit? Fait intéressant, différents réseaux y ont "trouvé" différents objets. Chacun des réseaux a vu quelque chose de différent. Resnet18 était sûr à 100% qu'il s'agissait d'une méduse, tandis qu'Inception, au contraire, avait très peu confiance dans les prédictions, bien qu'en même temps, elle ait vu beaucoup plus d'objets que tout autre réseau.
Vgg16:
978
14
7
1
Resnet18:
1000
Alexnet:
942
58
Densenet:
893
37
33
20
16
1
Inception:
155
123
102
85
83
81
69
32
26
25
24
18
16
16
12
12
11
9
9
8
7
5
5
5
- 5
4
4
4
4
3
3
3
3
3
2
2
2
2
2
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
Juste pour le plaisir, j'ai décidé de voir quel type de signature Microsoft mettra sous l'image de bruit, que j'ai rapproché du début de cette entrée. Pour le test, j'ai décidé d'aller de la manière la plus simple et d'utiliser PowerPoint à partir d'Office 365. Le résultat est intéressant car contrairement aux modèles imagenet qui tentent de reconnaître un seul objet, PowerPoint essaie de reconnaître plusieurs objets afin de créer une description précise de l'image.
L'image montre un éléphant, des gens, une grosse boule.
Le résultat ne m'a pas déçu. De mon point de vue, l'image de bruit était reconnue comme un cirque.
Points de vue
Cela nous amène à une autre question: que voit le réseau de neurones qui lui fait penser que le bruit est un objet? Dans notre recherche de réponse, nous pouvons utiliser un outil d'interprétation de modèle qui nous permettra de comprendre grossièrement ce que le réseau "voit". Captum est un cadre d'interprétation de modèle pour PyTorch. Je n'ai rien fait de spécial ici, j'ai juste utilisé le code des tutoriels sur leur site Web. Je viens d'ajouter le paramètre internal_batch_size avec une valeur de 50, car sans lui, mon GPU a manqué de mémoire très rapidement.
Pour les visualisations, j'ai utilisé deux attributions basées sur le gradient et une attribution basée sur l'occlusion. Avec ces visualisations, nous essayons de comprendre ce qui était important pour le classifieur, et donc de «voir» ce que voit le réseau. J'ai également utilisé mon modèle de resnet pré-formé, mais vous pouvez changer le code et utiliser tout autre modèle pré-formé.
Avant de passer au bruit, j'ai pris l'image de la camomille comme une démonstration du processus de rendu, car ses signes sont faciles à reconnaître.
result = resnet18(image_xform)
result = F.softmax(result, dim=1)
score, pred_label_idx = torch.topk(result, 1)
integrated_gradients = IntegratedGradients(resnet18)
attributions_ig = integrated_gradients.attribute(image_xform, target=pred_label_idx,
internal_batch_size=50, n_steps=200)
default_cmap = LinearSegmentedColormap.from_list('custom blue',
[(0, '#ffffff'),
(0.25, '#000000'),
(1, '#000000')], N=256)
_ = viz.visualize_image_attr(np.transpose(attributions_ig.squeeze().cpu().detach().numpy(), (1,2,0)),
np.transpose(image_xform.squeeze().cpu().detach().numpy(), (1,2,0)),
method='heat_map',
cmap=default_cmap,
show_colorbar=True,
sign='positive',
outlier_perc=1)
noise_tunnel = NoiseTunnel(integrated_gradients)
attributions_ig_nt = noise_tunnel.attribute(image_xform, n_samples=10, nt_type='smoothgrad_sq', target=pred_label_idx, internal_batch_size=50)
_ = viz.visualize_image_attr_multiple(np.transpose(attributions_ig_nt.squeeze().cpu().detach().numpy(), (1,2,0)),
np.transpose(image_xform.squeeze().cpu().detach().numpy(), (1,2,0)),
["original_image", "heat_map"],
["all", "positive"],
cmap=default_cmap,
show_colorbar=True)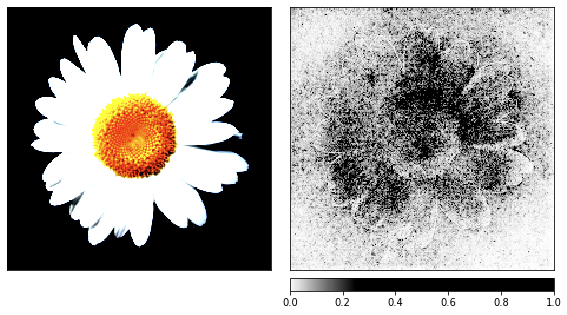
occlusion = Occlusion(resnet18)
attributions_occ = occlusion.attribute(image_xform,
strides = (3, 8, 8),
target=pred_label_idx,
sliding_window_shapes=(3,15, 15),
baselines=0)
_ = viz.visualize_image_attr_multiple(np.transpose(attributions_occ.squeeze().cpu().detach().numpy(), (1,2,0)),
np.transpose(image_xform.squeeze().cpu().detach().numpy(), (1,2,0)),
["original_image", "heat_map"],
["all", "positive"],
show_colorbar=True,
outlier_perc=2,
)

Visualisation du bruit
Nous avons généré les images précédentes à partir de la camomille, et il est maintenant temps de voir comment les choses fonctionnent avec un bruit aléatoire.
J'utilise le réseau resnet18 pré-entraîné et avec cette image, elle est sûre à 40% de voir une méduse. Je ne répéterai pas le code, le code de rendu est le même que celui donné ci-dessus.


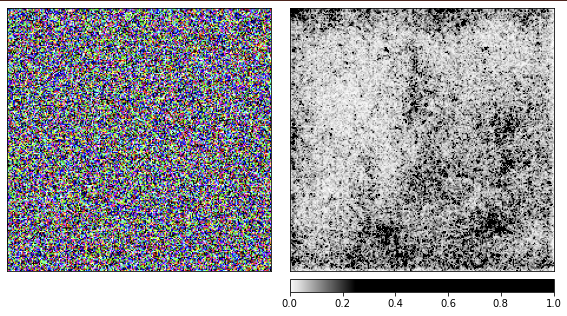

D'après les visualisations, il est clair que nous, les humains, ne pourrons jamais comprendre pourquoi le réseau voit une méduse ici. Certaines zones de l'image sont marquées comme plus importantes, mais elles ne sont pas du tout définies comme nous l'avons vu dans l'exemple de la camomille. Contrairement à la camomille, les méduses sont amorphes et diffèrent par le niveau de transparence.
Vous vous demandez peut-être à quoi ressemblerait le rendu du traitement d'une image réelle d'une méduse? Mon code est posté sur Github, et il sera facile d'obtenir une réponse à cette question avec son aide.
Conclusion
Sur la base de cet enregistrement, il est facile de voir à quel point il est facile de tromper les réseaux de neurones en leur fournissant des entrées inattendues. À leur honneur, nous dirons qu'ils ont fait leur travail et ont donné le meilleur résultat possible. Il ressort également des résultats des travaux que, dans de tels cas, il ne suffit pas de filtrer les options avec un faible degré de confiance, car certaines options avaient une confiance plutôt élevée. Nous devons être à l'affût des situations dans lesquelles les systèmes du monde réel échouent si facilement. Nous ne devons pas être surpris par l'entrée de données inattendues dans le système - et c'est ce que font les experts en sécurité depuis un certain temps.