introduction
Bonjour, Habr!
Beaucoup de gens ont aimé la partie précédente, alors j'ai à nouveau pelleté la moitié de la documentation sur le boost et j'ai trouvé quelque chose à écrire. Il est très étrange qu'il n'y ait pas une telle excitation autour de boost.compute que autour de boost.asio. Après tout, assez, cette bibliothèque est multiplateforme et fournit également une interface pratique (dans le cadre de c ++) pour interagir avec le calcul parallèle sur le GPU et le CPU.
Toutes les parties
- Partie 1
- Partie 2
Contenu
- Opérations asynchrones
- Fonctions personnalisées
- Comparaison de la vitesse de différents appareils dans différents modes
- Conclusion
Opérations asynchrones
Cela semblerait beaucoup plus rapide? Une façon d'accélérer l'utilisation des conteneurs dans l'espace de noms de calcul consiste à utiliser des fonctions asynchrones. Boost.compute nous fournit plusieurs outils. Parmi celles-ci, la classe compute :: future pour contrôler l'utilisation des fonctions et les fonctions copy_async (), fill_async () pour copier ou remplir le tableau. Bien sûr, il existe également des outils pour travailler avec des événements, mais il n'est pas nécessaire de les prendre en compte. Voici un exemple d'utilisation de tout ce qui précède:
auto device = compute::system::default_device();
auto context = compute::context::context(device);
auto queue = compute::command_queue(context, device);
std::vector<int> vec_std = {1, 2, 3};
compute::vector<int> vec_compute(vec_std.size(), context);
compute::vector<int> for_filling(10, context);
int num_for_fill = 255;
compute::future<void> filling = compute::fill_async(for_filling.begin(),
for_filling.end(), num_for_fill, queue); //
compute::future<void> copying = compute::copy_async(vec_std.begin(),
vec_std.end(), vec_compute.begin(), queue); //
filling.wait();
copying.wait();
Il n'y a rien de spécial à expliquer ici. Les trois premières lignes sont l'initialisation standard des classes nécessaires, puis deux vecteurs pour la copie, un vecteur pour le remplissage, dont la variable remplira le vecteur précédent et directement les fonctions de remplissage et de copie, respectivement. Ensuite, nous attendons leur exécution.
Pour ceux qui ont travaillé avec std :: future de STL, tout est pareil ici, seulement dans un espace de noms différent et il n'y a pas d'analogue de std :: async ().
Fonctions personnalisées pour les calculs
Dans la partie précédente, j'ai dit que j'expliquerais comment utiliser mes propres méthodes pour traiter un ensemble de données. J'ai compté 3 façons de le faire: utiliser une macro, utiliser make_function_from_source <> () et utiliser un cadre spécial pour les expressions lambda.
Je vais commencer par la toute première option - une macro. Je vais d'abord joindre un exemple de code, puis j'expliquerai comment cela fonctionne.
BOOST_COMPUTE_FUNCTION(float,
add,
(float x, float y),
{ return x + y; });
Le premier argument est le type de la valeur de retour, puis le nom de la fonction, ses arguments et le corps de la fonction. Plus loin sous le nom add, cette fonction peut être utilisée, par exemple, dans la fonction compute :: transform (). L'utilisation de cette macro est très similaire à une expression lambda régulière, mais j'ai vérifié qu'elles ne fonctionneront pas.
La deuxième méthode, probablement la plus difficile, est très similaire à la première. J'ai regardé le code de la macro précédente et il s'est avéré qu'elle utilise la deuxième méthode.
compute::function<float(float)> add = compute::make_function_from_source<float(float)>
("add", "float add(float x, float y) { return x + y; }");
Ici, tout est plus évident qu'il n'y paraît à première vue, la fonction make_function_from_source () n'utilise que deux arguments, dont l'un est le nom de la fonction, et le second est son implémentation. Une fois qu'une fonction est déclarée, elle peut être utilisée de la même manière qu'après une implémentation de macro.
Eh bien, la dernière option est un framework d'expression lambda. Exemple d'utilisation:
compute::transform(com_vec.begin(),
com_vec.end(),
com_vec.begin(),
compute::_1 * 2,
queue);
Comme quatrième argument, nous indiquons que nous voulons multiplier chaque élément du premier vecteur par 2, tout est assez simple et se fait sur place.
Les expressions booléennes peuvent être spécifiées de la même manière. Par exemple, dans la méthode compute :: count_if ():
std::vector<int> source_std = { 1, 2, 3 };
compute::vector<int> source_compute(source_std.begin() ,source_std.end(), queue);
auto counter = compute::count_if(source_compute.begin(),
source_compute.end(),
compute::lambda::_1 % 2 == 0,
queue);
Ainsi, nous avons compté tous les nombres pairs du tableau, le compteur sera égal à un.
Comparaison de la vitesse de différents appareils dans différents modes
Eh bien, la dernière chose sur laquelle je voudrais écrire dans cet article est une comparaison de la vitesse de traitement sur différents appareils et dans différents modes (uniquement pour le processeur). cette comparaison s'avérera quand il sera judicieux d'utiliser des GPU pour le calcul et le calcul parallèle en général.
Je vais tester comme ceci: en utilisant compute pour tous les appareils, j'appellerai la fonction compute :: sort () afin de trier un tableau de 100 millions de valeurs flottantes. Pour tester le mode mono-thread, appelez std :: sort sur un tableau de même taille. Pour chaque appareil, je noterai le temps en millisecondes à l'aide de la bibliothèque standard chrono et afficherai tout sur la console.
Le résultat est le suivant:

maintenant, je ne ferai la même chose que pour mille valeurs. Cette fois, le temps sera en microsecondes.

Cette fois, le processeur en mode mono-thread était en avance sur tout le monde. De cela, nous concluons que ce type d'opération ne vaut la peine d'être effectué que lorsqu'il s'agit de très grandes données.
Je voudrais faire d'autres tests, alors faisons un test pour calculer le cosinus, la racine carrée et la quadrature.
Dans le calcul du cosinus, la différence est très grande (le GPU fonctionne 60 fois plus vite que le CPU dans un thread).
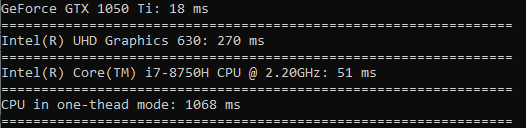
La racine carrée est calculée à peu près à la même vitesse que le tri.
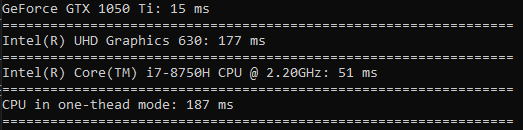
Le temps passé à la quadrature est encore moins une différence que le tri (le GPU n'est que 3,5 fois plus rapide).

Conclusion
Ainsi, après avoir lu cet article, vous avez appris à utiliser des fonctions asynchrones pour copier des tableaux et les remplir. Nous avons appris de quelle manière vous pouvez utiliser vos propres fonctions pour effectuer des calculs sur des données. Et aussi vu clairement quand il vaut la peine d'utiliser un GPU ou un CPU pour le calcul parallèle, et quand vous pouvez vous en tirer avec un seul thread.
Je serais heureux de recevoir des commentaires positifs, merci pour votre temps!
Bonne chance à tous!