
Amazon SageMaker offre plus que la simple capacité de gérer des blocs-notes dans Jupyter, mais un service configurable qui vous permet de créer, former, optimiser et déployer des modèles d'apprentissage automatique. Une idée fausse courante, en particulier lors de la mise en route de SageMaker, est que vous avez besoin de SageMaker Notebook Instance ou SageMaker (Studio) Notebook pour utiliser ces services. En fait, vous pouvez exécuter tous les services directement à partir de votre ordinateur local ou même de votre IDE préféré.
Avant d'aller plus loin, voyons comment interagir avec les services Amazon SageMaker. Vous disposez de deux API:
SageMaker Python SDK - Une API Python de haut niveau qui résume le code pour la création, la formation et le déploiement de modèles d'apprentissage automatique. En particulier, il fournit des évaluateurs pour des algorithmes de première classe ou intégrés, et il prend également en charge des frameworks tels que TensorFlow, MXNET, etc. Dans la plupart des cas, vous l'utiliserez pour interagir avec des tâches d'apprentissage automatique interactives.
SDK AWSEst une API de bas niveau utilisée pour interagir avec tous les services AWS pris en charge, pas nécessairement pour SageMaker. AWS SDK est disponible pour les langages les plus courants tels que Java, Javascript, Python (boto), etc. Dans la plupart des cas, vous utiliserez cette API pour des choses telles que la création de ressources d'automatisation ou l'interaction avec d'autres services AWS qui ne sont pas pris en charge par le SDK SageMaker Python.
Pourquoi un environnement local?
Le coût est la première chose qui me vient à l'esprit, mais la flexibilité de l'utilisation de votre IDE natif et la possibilité de travailler hors ligne et d'exécuter des tâches dans le cloud AWS lorsque vous êtes prêt sont également importantes.
Comment fonctionne l'environnement local
Vous écrivez le code pour créer le modèle, mais au lieu d'une instance de SageMake Notebook ou SageMaker Studio Notebook, vous le faites sur votre ordinateur local dans Jupyter ou à partir de votre IDE. Ensuite, lorsque tout sera prêt, vous commencerez à vous entraîner sur les instances SageMaker sur AWS. Après l'entraînement, le modèle sera stocké dans AWS. Vous pouvez ensuite exécuter le déploiement ou la conversion par lots à partir de votre ordinateur local.
Mettre en place un environnement avec conda
Il est recommandé de configurer un environnement virtuel Python. Dans notre cas, nous utiliserons conda pour gérer les environnements virtuels, mais vous pouvez utiliser virtualenv. Encore une fois, Amazon SageMaker utilise conda pour gérer les environnements et les packages. Il est supposé que conda est déjà installé, sinon, allez ici .
Créer un nouvel environnement conda
conda create -n sagemaker python=3Nous activons et vérifions l'environnement

Installation des packages requis
Pour installer des packages, utilisez les commandes
condaou pip. Choisissons l'option avec conda .
conda install -y pandas numpy matplotlibInstallation des packages AWS
Installez AWS SDK for Python (boto), awscli et SageMaker Python SDK. Le SDK SageMaker Python n'est pas disponible en tant que package conda, nous allons donc l'utiliser ici
pip.
pip install boto3 awscli sagemakerSi c'est la première fois que vous utilisez awscli, vous devez le configurer. Ici, vous pouvez voir comment procéder.
La deuxième version du SDK SageMaker Python sera installée par défaut. Assurez-vous de vérifier les modifications importantes dans la deuxième version du SDK.
Installer Jupyter et construire le noyau
conda install -c conda-forge jupyterlab
python -m ipykernel install --user --name sagemakerNous vérifions l'environnement et vérifions les versions
Lancez Jupyter via Jupyter Lab et sélectionnez le noyau que
sagemakernous avons créé ci-dessus.
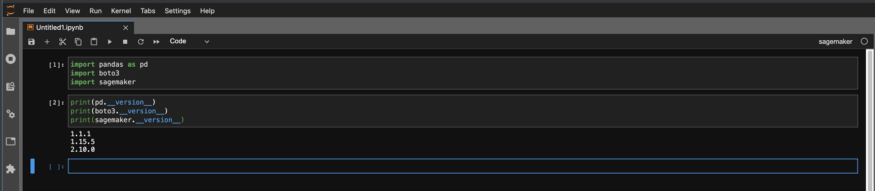
Vérifiez ensuite les versions dans le bloc-notes pour vous assurer qu'elles sont bien celles que vous souhaitez.
Nous créons et formons
Vous pouvez maintenant commencer à créer votre modèle localement et commencer à apprendre sur AWS lorsque vous êtes prêt.
Importer des packages
Importez les packages requis et spécifiez le rôle. La principale différence ici est que vous devez spécifier les
arnrôles directement , non get_execution_role(). Étant donné que vous exécutez tout à partir de votre machine locale avec des informations d'identification AWS et non une instance de notebook avec un rôle, la fonctionnalité get_execution_role()ne fonctionnera pas.
from sagemaker import image_uris # Use image_uris instead of get_image_uri
from sagemaker import TrainingInput # Use instead of sagemaker.session.s3_input
region = boto3.Session().region_name
container = image_uris.retrieve('image-classification',region)
bucket= 'your-bucket-name'
prefix = 'output'
SageMakerRole='arn:aws:iam::xxxxxxxxxx:role/service-role/AmazonSageMaker-ExecutionRole-20191208T093742'Créer un évaluateur
Créez un évaluateur et définissez les hyperparamètres comme vous le feriez normalement. Dans l'exemple ci-dessous, nous entraînons un classificateur d'images à l'aide de l'algorithme de classification d'images intégré. Vous spécifiez également le type d'instance Stagemaker et le nombre d'instances que vous souhaitez utiliser pour l'entraînement.
s3_output_location = 's3://{}/output'.format(bucket, prefix)
classifier = sagemaker.estimator.Estimator(container,
role=SageMakerRole,
instance_count=1,
instance_type='ml.p2.xlarge',
volume_size = 50,
max_run = 360000,
input_mode= 'File',
output_path=s3_output_location)
classifier.set_hyperparameters(num_layers=152,
use_pretrained_model=0,
image_shape = "3,224,224",
num_classes=2,
mini_batch_size=32,
epochs=30,
learning_rate=0.01,
num_training_samples=963,
precision_dtype='float32')
Canaux d'apprentissage
Spécifiez les canaux d'apprentissage comme vous le faites toujours, il n'y a pas non plus de changement par rapport à la façon dont vous le feriez sur votre copie de cahier.
train_data = TrainingInput(s3train, distribution='FullyReplicated',
content_type='application/x-image', s3_data_type='S3Prefix')
validation_data = TrainingInput(s3validation, distribution='FullyReplicated',
content_type='application/x-image', s3_data_type='S3Prefix')
train_data_lst = TrainingInput(s3train_lst, distribution='FullyReplicated',
content_type='application/x-image', s3_data_type='S3Prefix')
validation_data_lst = TrainingInput(s3validation_lst, distribution='FullyReplicated',
content_type='application/x-image', s3_data_type='S3Prefix')
data_channels = {'train': train_data, 'validation': validation_data,
'train_lst': train_data_lst, 'validation_lst': validation_data_lst}Nous commençons la formation
Démarrez la tâche d'entraînement dans SageMaker en appelant la méthode fit, qui commencera l'entraînement sur vos instances SageMaker AWS.
classifier.fit(inputs=data_channels, logs=True)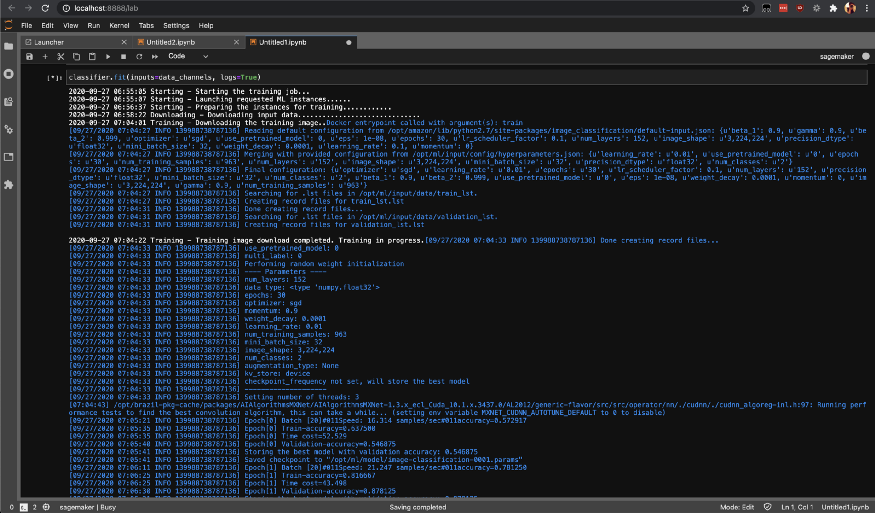
Vous pouvez vérifier l'état des tâches de formation avec list-training-jobs .
C'est tout. Aujourd'hui, nous avons compris comment configurer localement l'environnement SageMaker et créer des modèles d'apprentissage automatique sur une machine locale à l'aide de Jupyter. Outre Jupyter, vous pouvez faire la même chose depuis votre propre IDE.
Bon apprentissage!
