
Dans cet article, nous parlerons des détails d'implémentation et du fonctionnement de divers compilateurs JIT, ainsi que des stratégies d'optimisation. Nous discuterons de manière suffisamment détaillée, mais nous omettons de nombreux concepts importants. Autrement dit, il n'y aura pas suffisamment d'informations dans cet article pour parvenir à des conclusions raisonnables dans toute comparaison d'implémentations et de langues.
Pour obtenir une compréhension de base des compilateurs JIT, lisez cet article .
Une petite note:
, , , - . , JIT ( ), , . , , , , . - , , .
- Pypy
- GraalVM C
- OSR
- JIT
()
LuaJIT utilise ce qu'on appelle le traçage. Pypy effectue un méta-traçage, c'est-à-dire qu'il utilise le système pour générer des interprètes de trace et JIT. Pypy et LuaJIT ne sont pas des implémentations Python et Lua exemplaires, mais des projets autonomes. Je qualifierais LuaJIT de terriblement rapide, et il se décrit comme l'une des implémentations de langage dynamiques les plus rapides - et je le crois absolument.
Pour comprendre quand démarrer le traçage, la boucle de l'interpréteur recherche les hot loops (le concept de hot code est universel pour tous les compilateurs JIT!). Le compilateur "trace" ensuite la boucle, enregistrant les opérations exécutables pour compiler un code machine bien optimisé. Dans LuaJIT, la compilation est basée sur des traces avec une représentation intermédiaire de type instruction qui est unique à LuaJIT.
Comment le traçage est implémenté dans Pypy
Pypy commence à tracer la fonction après 1619 exécutions et compile après 1039 exécutions, c'est-à-dire qu'il faut environ 3000 exécutions de la fonction pour qu'elle commence à fonctionner plus rapidement. Ces valeurs ont été soigneusement choisies par l'équipe Pypy, et en général dans le monde des compilateurs, de nombreuses constantes sont soigneusement choisies.
Les langages dynamiques rendent l'optimisation difficile. Le code ci-dessous peut être supprimé de manière statique dans un langage plus strict car il
Falsesera toujours faux. Cependant, dans Python 2, cela ne peut être garanti avant l'exécution.
if False:
print("FALSE")
Pour tout programme intelligent, cette condition sera toujours fausse. Malheureusement, la valeur
Falsepeut être redéfinie, et l'expression sera dans une boucle, elle peut être redéfinie ailleurs. Par conséquent, Pypy peut créer une «garde». Si le défenseur échoue, JIT retombe dans la boucle d'interprétation. Pypy utilise ensuite une autre constante (200) appelée trace eagerness pour décider s'il faut compiler le reste du nouveau chemin avant la fin de la boucle. Ce sous-chemin s'appelle un pont .
De plus, Pypy fournit ces constantes comme arguments que vous pouvez personnaliser au moment de l'exécution avec le déroulement de la configuration, c'est-à-dire l'expansion de la boucle et l'inlining! Et en plus, il fournit des hooks que nous pouvons voir une fois la compilation terminée.
def print_compiler_info(i):
print(i.type)
pypyjit.set_compile_hook(print_compiler_info)
for i in range(10000):
if False:
pass
print(pypyjit.get_stats_snapshot().counters)
Ci-dessus, j'ai écrit un programme pur Python avec un hook de compilation pour afficher le type de compilation appliqué. Le code génère également des données à la fin, qui indiquent le nombre de défenseurs. Pour ce programme, j'ai une compilation en boucle et 66 défenseurs. Quand j'ai remplacé l'expression par une
ifsimple passe hors boucle for, il ne restait plus que 59 défenseurs.
for i in range(10000):
pass # removing the `if False` saved 7 guards!
En ajoutant ces deux lignes à la boucle
for, j'ai obtenu deux compilations dont l'une était de type "bridge"!
if random.randint(1, 100) < 20:
False = True
Attendez, vous parliez de métatracing!
L'idée du méta-traçage peut être décrite comme «écrivez un interpréteur et obtenez un compilateur gratuitement!» Ou «transformez votre interpréteur en compilateur JIT! Ecrire un compilateur est difficile, et si vous pouvez l'obtenir gratuitement, alors l'idée est cool. Pypy "contient" un interpréteur et un compilateur, mais il n'implémente pas explicitement un compilateur traditionnel.
Pypy a un outil RPython (conçu pour Pypy). C'est un cadre pour écrire des interprètes. Son langage est une sorte de Python et est typé statiquement. C'est dans cette langue que vous devez écrire un interprète. Le langage n'est pas conçu pour la programmation Python typée car il ne contient pas de bibliothèques ou de packages standard. Tout programme RPython est un programme Python valide. Le code RPython est transpilé en C puis compilé. Ainsi, un méta-compilateur dans ce langage existe en tant que programme C compilé.
Le préfixe "meta" dans le mot metatraces signifie que le traçage est effectué lorsque l'interpréteur est en cours d'exécution, pas le programme. Il se comporte plus ou moins comme n'importe quel autre interpréteur, mais il peut suivre ses opérations et est conçu pour optimiser les traces en mettant à jour son chemin. Avec un traçage plus poussé, le chemin de l'interpréteur devient plus optimisé. Un interpréteur bien optimisé suit un chemin spécifique. Et le code machine utilisé dans ce chemin, obtenu en compilant RPython, peut être utilisé dans la compilation finale.
En bref, le "compilateur" de Pypy compile votre interpréteur, c'est pourquoi Pypy est parfois appelé le méta-compilateur. Il ne compile pas tant le programme que vous exécutez que le chemin d'un interpréteur optimisé.
Le concept de métatracing peut sembler déroutant, donc à des fins d'illustration, j'ai écrit un programme très pauvre qui ne comprend que
a = 0et a++to.
# interpreter written with RPython
for line in code:
if line == "a = 0":
alloc(a, 0)
elif line == "a++":
guard(a, "is_int") # notice how in Python, the type is unknown, but after being interpreted by RPython, the type is known
guard(a, "> 0")
int_add(a, 1)
Si j'exécute ce cycle chaud:
a = 0
a++
a++
Les pistes pourraient ressembler à ceci:
# Trace from numerous logs of the hot loop
a = alloc(0) # guards can go away
a = int_add(a, 1)
a = int_add(a, 2)
# optimize trace to be compiled
a = alloc(2) # the section of code that executes this trace _is_ the compiled code
Mais le compilateur n'est pas un module séparé spécial, il est intégré à l'interpréteur. Par conséquent, le cycle d'interprétation ressemblera à ceci:
for line in code:
if traces.is_compiled(line):
run_compiled(traces.compiled(line))
continue
elif traces.is_optimized(line):
compile(traces.optimized(line))
continue
elif line == "a = 0"
# ....
Introduction à la JVM
J'ai passé quatre mois à écrire dans le langage TruffleRuby basé sur Graal et j'en suis tombé amoureux.
Hotspot (ainsi nommé car il recherche des hotspots ) est une machine virtuelle fournie avec des installations Java standard. Il contient plusieurs compilateurs pour l'implémentation de la compilation à plusieurs niveaux. La base de code de 250 000 lignes de Hotspot est ouverte et dispose de trois garbage collector. Les développeurs font face à la compilation JIT, dans certains benchmarks, cela fonctionne mieux que les impls C ++ (à cette occasion,
Les stratégies utilisées dans Hotspot ont inspiré de nombreux auteurs de compilateurs JIT ultérieurs, de frameworks de machines virtuelles de langage et en particulier de moteurs Javascript. Hotspot a également engendré une vague de langages JVM tels que Scala, Kotlin, JRuby et Jython. JRuby et Jython sont des implémentations amusantes de Ruby et Python qui compilent le code source en bytecode JVM, que Hotspot exécute ensuite. Tous ces projets réussissent relativement bien à accélérer les langages Python et Ruby (Ruby plus que Python) sans implémenter tous les outils, comme c'est le cas avec Pypy. Hotspot est également unique en ce sens qu'il s'agit d'un JIT pour les langages moins dynamiques (bien qu'il s'agisse techniquement d'un JIT pour le bytecode JVM, pas pour Java).

GraalVM est une JavaVM avec un morceau de code Java. Il peut exécuter n'importe quel langage JVM (Java, Scala, Kotlin, etc.). Il prend également en charge Native Image pour fonctionner avec le code compilé AOT via la machine virtuelle Substrate. Une proportion importante des services Scala de Twitter fonctionnent sur Graal, ce qui parle de la qualité de la machine virtuelle, et à certains égards, elle est meilleure que la JVM, bien qu'elle soit écrite en Java.
Et ce n'est pas tout! GraalVM fournit également Truffle: un framework pour implémenter des langages en créant des interpréteurs AST (Abstract Syntax Tree). Il n'y a pas d'étape explicite dans Truffle lorsque le bytecode JVM est généré comme dans un langage JVM standard. Au contraire, Truffle utilisera simplement l'interpréteur et parlera à Graal pour générer du code machine directement avec le profilage et ce que l'on appelle un score partiel. L'évaluation partielle dépasse le cadre de cet article, en un mot: cette méthode adhère à la philosophie «écrivez un interpréteur et obtenez un compilateur gratuitement!» De la philosophie du méta-suivi, mais l'aborde différemment.
TruffleJS — Truffle- Javascript, V8 , , V8 , Google , . TruffleJS «» V8 ( JS-) , Graal.
JIT-
C
Les implémentations JIT ont souvent un problème de prise en charge des extensions C. Les interpréteurs standard tels que Lua, Python, Ruby et PHP ont une API C qui permet aux utilisateurs de créer des packages dans ce langage, ce qui accélère considérablement l'exécution. De nombreux packages sont écrits en C, par exemple numpy, des fonctions de bibliothèque standard comme
rand. Toutes ces extensions C sont essentielles pour qu'un langage interprété fonctionne rapidement.
Les extensions C sont difficiles à maintenir pour un certain nombre de raisons. La raison la plus évidente est que l'API est conçue avec une implémentation interne à l'esprit. De plus, il est plus facile de prendre en charge les extensions C lorsque l'interpréteur est écrit en C, donc JRuby ne peut pas prendre en charge les extensions C, mais il dispose d'une API pour les extensions Java. Pypy a récemment publié une version bêta de la prise en charge des extensions C, même si je ne suis pas sûr que cela fonctionne en raison de la loi d' Hyrum . LuaJIT prend en charge les extensions C, y compris des fonctionnalités supplémentaires dans ses extensions C (LuaJIT est tout simplement génial!)
Graal résout ce problème avec Sulong, un moteur qui exécute le bytecode LLVM sur GraalVM, en le convertissant en Truffle. LLVM est une boîte à outils, et nous avons juste besoin de savoir que C peut être compilé en bytecode LLVM (Julia a aussi un backend LLVM!). C'est étrange, mais la solution est de prendre un bon langage compilé avec plus de quarante ans d'histoire, et de l'interpréter! Bien sûr, il ne fonctionne pas aussi vite que le C correctement compilé, mais il offre plusieurs avantages.
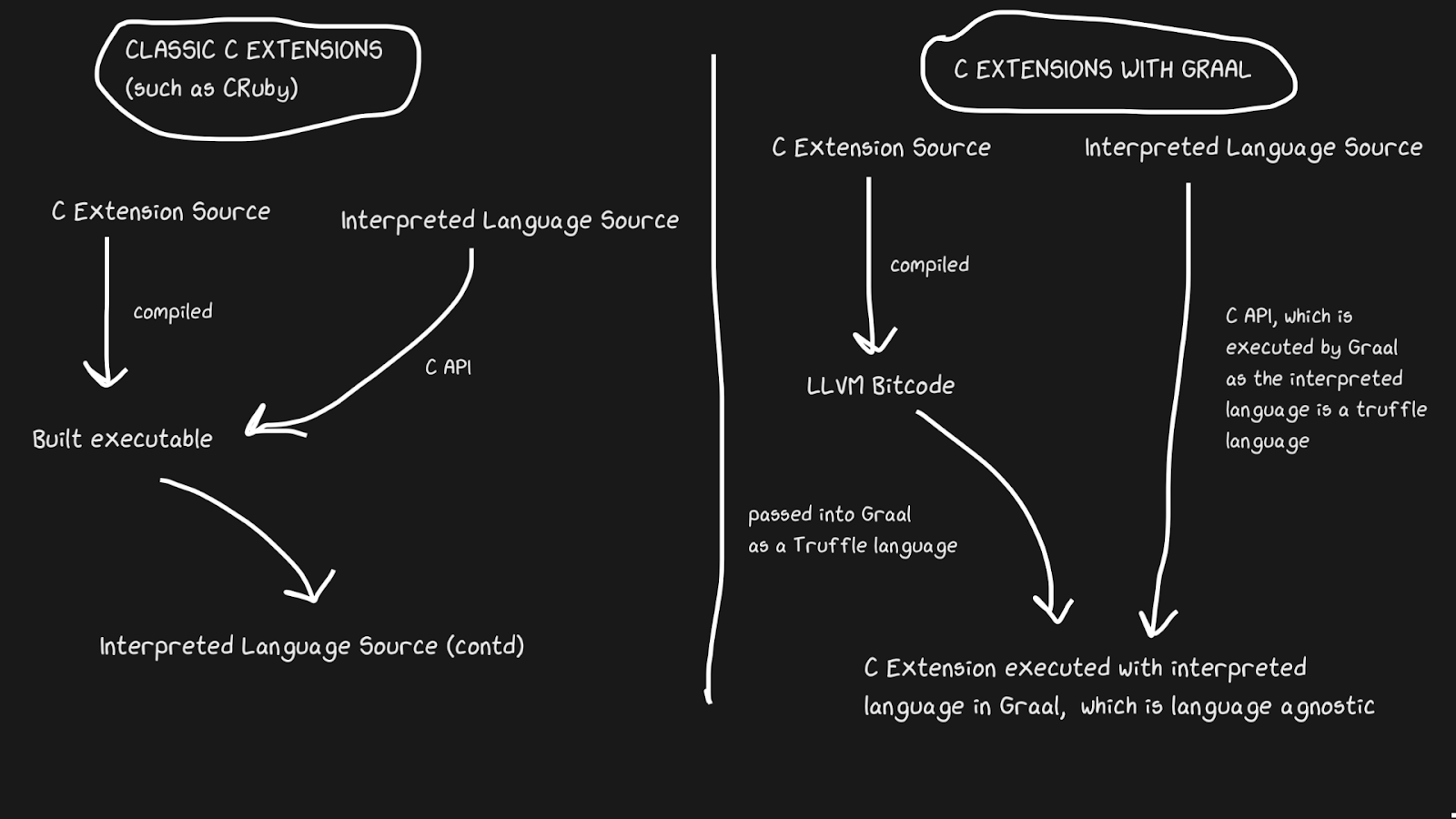
Le bytecode LLVM est déjà assez bas niveau, c'est-à-dire qu'il n'est pas aussi inefficace d'appliquer JIT à cette représentation intermédiaire qu'à C.Une partie du coût est compensée par le fait que le bytecode peut être optimisé avec le reste du programme Ruby, mais nous ne pouvons pas optimiser le programme C compilé ... Toutes ces bandes de mémoire, incrustations, blocs morts, etc. peuvent être appliqués au code C et Ruby, au lieu d'appeler le binaire C à partir du code Ruby. Les extensions TruffleRuby C sont plus rapides que les extensions CRuby C à certains égards.
Pour que ce système fonctionne, vous devez savoir que Truffle est complètement indépendant du langage et que la surcharge de basculement entre C, Java ou tout autre langage dans Graal sera minime.
La capacité de Graal à travailler avec Sulong fait partie de ses capacités polyglottes, ce qui permet une interchangeabilité linguistique élevée. Ce n'est pas seulement bon pour le compilateur, mais cela prouve également que vous pouvez facilement utiliser plusieurs langues dans une "application".
De retour au code interprété, c'est plus rapide
Nous savons que les JIT contiennent un interpréteur et un compilateur, et qu'ils passent d'interpréteur en compilateur pour accélérer les choses. Pypy crée des ponts pour le chemin de retour, bien que du point de vue de Graal et Hotspot, il s'agit d'une désoptimisation . Nous ne parlons pas de concepts complètement différents, mais par désoptimisation nous entendons un retour à l'interprète comme une optimisation consciente, et non une solution à l'inévitabilité d'un langage dynamique. Hotspot et Graal font un usage intensif de la désoptimisation, en particulier Graal, parce que les développeurs ont un contrôle étroit sur la compilation et ont besoin d'encore plus de contrôle sur la compilation pour des optimisations (par rapport, par exemple, à Pypy). La désoptimisation est également utilisée dans les moteurs JS, dont je parlerai beaucoup, car JavaScript dans Chrome et Node.js en dépend.
Pour appliquer rapidement la désoptimisation, il est important de vous assurer de basculer le plus rapidement possible entre le compilateur et l'interpréteur. Avec l'implémentation la plus naïve, l'interpréteur devra «rattraper» le compilateur pour effectuer la désoptimisation. Des complications supplémentaires sont associées à la désoptimisation des flux asynchrones. Graal crée un ensemble de cadres et le compare au code généré pour retourner à l'interpréteur. Avec les safepoints, vous pouvez faire une pause de thread Java et dire: "Bonjour, garbage collector, dois-je arrêter?" Pour que le traitement des threads ne nécessite pas beaucoup de temps système. Cela s'est avéré plutôt grossier, mais cela fonctionne assez rapidement pour que la désoptimisation soit une bonne stratégie.
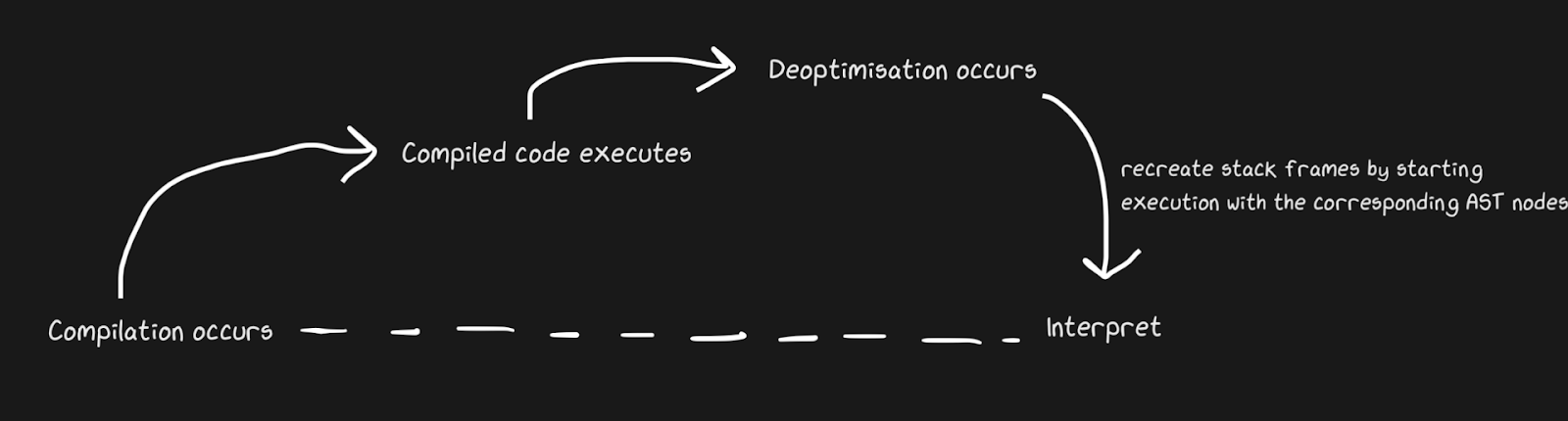
Semblable à l'exemple de pontage Pypy, le patching de fonctions monkey peut également être désoptimisé. C'est plus élégant parce que nous ajoutons du code de désoptimisation non pas lorsque le défenseur échoue, mais lorsque des correctifs de guérilla sont appliqués.
Un excellent exemple de désoptimisation JIT: le dépassement de capacité de conversion est un terme non officiel. Nous parlons d'une situation où un certain type (par exemple,
int32) est représenté / alloué en interne , mais il doit être converti en int64. TruffleRuby le fait avec des désoptimisations, tout comme le V8.
Dites, si vous demandez dans Ruby
var = 0, vous obtenez int32(Ruby l'appelle Fixnumet Bignum, mais j'utiliserai la notation int32et int64). Effectuer une opération avecvar, vous devez vérifier si un dépassement de valeur se produit. Mais c'est une chose à vérifier, et compiler du code qui gère les débordements coûte cher, surtout compte tenu de la fréquence des opérations numériques.
Sans même regarder les instructions compilées, vous pouvez voir comment cette désoptimisation réduit la quantité de code.
int a, b;
int sum = a + b;
if (overflowed) {
long bigSum = a + b;
return bigSum;
} else {
return sum;
}
int a, b;
int sum = a + b;
if (overflowed) {
Deoptimize!
}
Dans TruffleRuby, seule la première exécution d'une opération particulière est désoptimisée, nous ne gaspillons donc pas de ressources à chaque fois qu'une opération déborde.
Le code WET est un code rapide. Inlining et OSR
function foo(a, b) {
return a + b;
}
for (var i = 0; i < 1000000; i++) {
foo(i, i + 1);
}
foo(1, 2);
Même des trivialités comme ces déclencheurs sont désoptimisées dans V8! Avec des options comme
--trace-deoptet, --trace-optvous pouvez collecter de nombreuses informations sur le JIT et également modifier le comportement. Graal a des outils très utiles, mais j'utiliserai V8 car beaucoup l'ont installé.
La désoptimisation est lancée par la dernière ligne (
foo(1, 2)), ce qui est déroutant, car cet appel a été fait dans la boucle! Nous recevrons un message "Retour de type insuffisant pour l'appel" (la liste complète des raisons de la désoptimisation est ici , et il y a une drôle de raison pour "aucune raison"). Cela crée un cadre d'entrée affichant les littéraux 1et 2.
Alors pourquoi désoptimiser? Le V8 est assez intelligent pour faire du typage: quand il
iest typeinteger, les littéraux sont également passés integer.
Pour comprendre cela, remplaçons la dernière ligne par
foo(i, i +1). Mais la désoptimisation est toujours appliquée, mais cette fois le message est différent: "Retour de type insuffisant pour l'opération binaire". POURQUOI?! Après tout, c'est exactement la même opération qui est effectuée en boucle, avec les mêmes variables!
La réponse, mon ami, réside dans le remplacement sur pile (OSR). L'inlining est une puissante optimisation du compilateur (pas seulement JIT) dans laquelle les fonctions cessent d'être des fonctions et le contenu est passé au lieu des appels. Les compilateurs JIT peuvent en ligne pour augmenter la vitesse en changeant le code au moment de l'exécution (les langages compilés ne peuvent en ligne que de manière statique).
// partial output from printing inlining details
[compiling method 0x04a0439f3751 <JSFunction (sfi = 0x4a06ab56121)> using TurboFan OSR]
0x04a06ab561e9 <SharedFunctionInfo foo>: IsInlineable? true
Inlining small function(s) at call site #49:JSCall
Ainsi, V8 compilera
foo, déterminera qu'il peut être en ligne et en ligne avec OSR. Cependant, le moteur ne le fait que pour le code à l'intérieur de la boucle, car il s'agit d'un chemin d'accès actif et la dernière ligne n'est pas encore dans l'interpréteur au moment de l'inlining. Par conséquent, le V8 n'a pas encore assez de retour sur le type de fonction foo, car non pas il est utilisé dans la boucle, mais sa version en ligne. S'il est appliqué --no-use-osr, il n'y aura pas de désoptimisation, que nous passions littéralement ou i. Cependant, sans insertion, même un minuscule million d'itérations s'exécuteront sensiblement plus lentement. Les compilateurs JIT incarnent vraiment le principe de non-solution-seulement-compromis. Les désoptimisations coûtent cher, mais elles ne se comparent pas au coût de recherche de méthodes et d'inlining, ce qui est préféré dans ce cas.
L'inlining est incroyablement efficace! J'ai exécuté le code ci-dessus avec quelques zéros supplémentaires, et avec l'inlining désactivé, il a fonctionné quatre fois plus lentement.

Bien que cet article traite de JIT, l'inlining est également efficace dans les langages compilés. Tous les langages LLVM utilisent activement l'inlining, car LLVM le fera également, bien que Julia soit inline sans LLVM, c'est dans sa nature. Les JIT peuvent être intégrés à l'aide de l'heuristique d'exécution et peuvent basculer entre les modes non-en ligne et en ligne en utilisant OSR.
Une note sur JIT et LLVM
LLVM fournit un tas d'outils liés à la compilation. Julia travaille avec LLVM (notez qu'il s'agit d'une grande boîte à outils et que chaque langage l'utilise différemment), tout comme Rust, Swift et Crystal. Qu'il suffise de dire que c'est un grand et merveilleux projet qui prend également en charge les JIT, bien que LLVM ne dispose pas de JIT dynamiques intégrés significatifs. Le quatrième niveau de compilation JavaScriptCore a utilisé le backend LLVM pendant un certain temps, mais il a été remplacé il y a moins de deux ans. Depuis lors, cette boîte à outils n'a pas été très bien adaptée aux JIT dynamiques, principalement parce qu'elle n'est pas conçue pour fonctionner dans un environnement dynamique. Pypy a essayé 5-6 fois, mais s'est installé sur JSC. Avec LLVM, l'affaissement des allocations et le mouvement du code étaient limités.Il était également impossible d'utiliser de puissantes fonctionnalités JIT telles que l'inférence de plage (c'est comme la diffusion, mais avec une plage de valeurs connue). Mais plus important encore, avec LLVM, beaucoup de ressources sont consacrées à la compilation.
Et si au lieu d'une représentation intermédiaire basée sur des instructions, nous avions un grand graphe qui se modifiait?
Nous avons parlé du bytecode LLVM et du bytecode Python / Ruby / Java comme représentation intermédiaire. Ils ressemblent tous à une sorte de langage sous forme d'instructions. Hotspot, Graal et V8 utilisent la représentation intermédiaire «Sea of Nodes» (introduite dans Hotspot), qui est un AST de niveau inférieur. C'est une vision efficace car une part importante du profilage repose sur la notion d'un certain chemin qui est rarement utilisé (ou croisé dans le cas d'un modèle). Notez que ces compilateurs AST sont différents des analyseurs AST.
Habituellement, j'adhère à la position «essayez de le faire à la maison!», Mais il est assez difficile de considérer les graphiques, bien que très intéressants, et souvent extrêmement utiles pour comprendre le travail du compilateur. Par exemple, je ne peux pas lire tous les graphiques non seulement en raison d'un manque de connaissances, mais aussi à cause des capacités de calcul de mon cerveau (les options du compilateur peuvent aider à me débarrasser des comportements qui ne m'intéressent pas).
Dans le cas du V8, nous utiliserons l'outil D8 avec un drapeau
--print-ast. Pour Graal, ce sera le cas --vm.Dgraal.Dump=Truffle:2. Le texte sera affiché à l'écran (formaté pour obtenir un graphique). Je ne sais pas comment les développeurs V8 génèrent des graphiques visuels, mais Oracle a un "Visualiseur de Graphiques Idéal" qui est utilisé dans l'illustration précédente. Je n'avais pas la force de réinstaller IGV, j'ai donc pris les graphiques de Chris Seaton, générés avec Seafoam, dont la source est maintenant fermée.
Bon, jetons un œil à l'AST JavaScript!
function accumulate(n, a) {
var x = 0;
for (var i = 0; i < n; i++) {
x += a;
}
return x;
}
accumulate(1, 1)
J'ai parcouru ce code
d8 --print-ast test.js, bien que nous ne soyons intéressés que par la fonction accumulate. Voyez que je ne l'ai appelé qu'une seule fois, c'est-à-dire que je n'ai pas à attendre la compilation pour obtenir l'AST.
Voici à quoi ressemble l'AST (j'ai supprimé quelques lignes sans importance):
FUNC at 19
. NAME "accumulate"
. PARAMS
. . VAR (0x7ff5358156f0) (mode = VAR, assigned = false) "n"
. . VAR (0x7ff535815798) (mode = VAR, assigned = false) "a"
. DECLS
. . VARIABLE (0x7ff5358156f0) (mode = VAR, assigned = false) "n"
. . VARIABLE (0x7ff535815798) (mode = VAR, assigned = false) "a"
. . VARIABLE (0x7ff535815840) (mode = VAR, assigned = true) "x"
. . VARIABLE (0x7ff535815930) (mode = VAR, assigned = true) "i"
. BLOCK NOCOMPLETIONS at -1
. . EXPRESSION STATEMENT at 38
. . . INIT at 38
. . . . VAR PROXY local[0] (0x7ff535815840) (mode = VAR, assigned = true) "x"
. . . . LITERAL 0
. FOR at 43
. . INIT at -1
. . . BLOCK NOCOMPLETIONS at -1
. . . . EXPRESSION STATEMENT at 56
. . . . . INIT at 56
. . . . . . VAR PROXY local[1] (0x7ff535815930) (mode = VAR, assigned = true) "i"
. . . . . . LITERAL 0
. . COND at 61
. . . LT at 61
. . . . VAR PROXY local[1] (0x7ff535815930) (mode = VAR, assigned = true) "i"
. . . . VAR PROXY parameter[0] (0x7ff5358156f0) (mode = VAR, assigned = false) "n"
. . BODY at -1
. . . BLOCK at -1
. . . . EXPRESSION STATEMENT at 77
. . . . . ASSIGN_ADD at 79
. . . . . . VAR PROXY local[0] (0x7ff535815840) (mode = VAR, assigned = true) "x"
. . . . . . VAR PROXY parameter[1] (0x7ff535815798) (mode = VAR, assigned = false) "a"
. . NEXT at 67
. . . EXPRESSION STATEMENT at 67
. . . . POST INC at 67
. . . . . VAR PROXY local[1] (0x7ff535815930) (mode = VAR, assigned = true) "i"
. RETURN at 91
. . VAR PROXY local[0] (0x7ff535815840) (mode = VAR, assigned = true) "x"
Il est difficile d'analyser cela, mais il est similaire à l'AST d'un analyseur (pas vrai pour tous les programmes). Et le prochain AST est généré en utilisant Acorn.js.
Une différence notable est la définition des variables. Dans l'AST de l'analyseur, il n'y a pas de définition explicite des paramètres et la déclaration de boucle est cachée dans le nœud
ForStatement. Dans un AST au niveau du compilateur, toutes les déclarations sont regroupées avec des adresses et des métadonnées.
Le compilateur AST utilise également cette expression stupide
VAR PROXY. L'AST de l'analyseur ne peut pas déterminer la relation entre les noms et les variables (par adresses) en raison du levage de variables (levage), de l'évaluation (eval) et autres. Ainsi, l'AST du compilateur utilise des variables PROXYqui sont ensuite associées à la variable réelle.
// This chunk is the declarations and the assignment of `x = 0`
. DECLS
. . VARIABLE (0x7ff5358156f0) (mode = VAR, assigned = false) "n"
. . VARIABLE (0x7ff535815798) (mode = VAR, assigned = false) "a"
. . VARIABLE (0x7ff535815840) (mode = VAR, assigned = true) "x"
. . VARIABLE (0x7ff535815930) (mode = VAR, assigned = true) "i"
. BLOCK NOCOMPLETIONS at -1
. . EXPRESSION STATEMENT at 38
. . . INIT at 38
. . . . VAR PROXY local[0] (0x7ff535815840) (mode = VAR, assigned = true) "x"
. . . . LITERAL 0
Et voici à quoi ressemble l'AST du même programme, obtenu avec Graal!
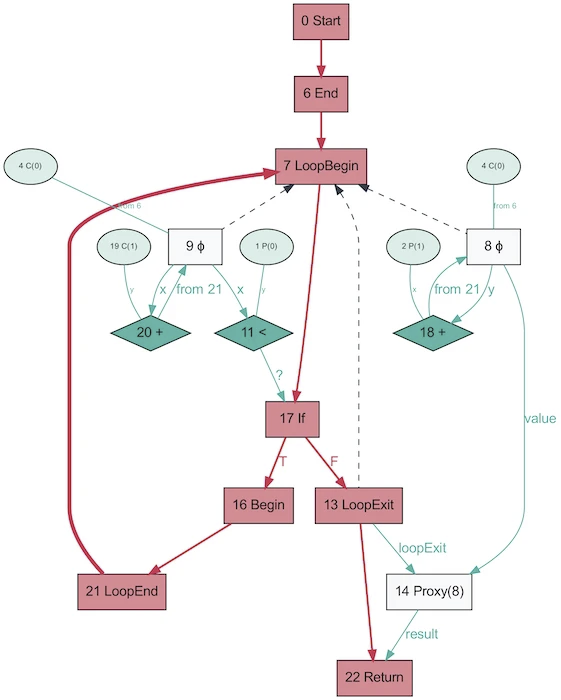
Cela semble beaucoup plus simple. Le rouge indique le flux de contrôle, le bleu indique le flux de données, les flèches indiquent les directions. Notez que si ce graphique est plus simple que l'AST de V8, cela ne signifie pas que Graal est meilleur pour simplifier le programme. Il est simplement généré sur la base de Java, qui est beaucoup moins dynamique. Le même graal graal généré à partir de Ruby sera plus proche de la première version.
C'est drôle que AST dans Graal change en fonction de l'exécution du code. Ce graphique est généré avec OSR désactivé et incorporé, lorsque la fonction est appelée à plusieurs reprises avec des paramètres aléatoires afin qu'elle ne soit pas optimisée. Et le dump vous fournira tout un tas de graphiques! Graal utilise un AST spécialisé pour optimiser les programmes (V8 fait des optimisations similaires, mais pas au niveau AST). Lorsque vous enregistrez des graphiques dans Graal, vous obtenez plus de dix schémas avec différents niveaux d'optimisation. Lors de la réécriture des nœuds, ils se remplacent (se spécialisent) par d'autres nœuds.
Le graphique ci-dessus est un excellent exemple de spécialisation dans un langage à typage dynamique (photo prise de One VM à Rule Them All, 2013). La raison pour laquelle ce processus existe est étroitement liée au fonctionnement de l'évaluation partielle - tout est question de spécialisation.
Hourra JIT a compilé le code! Compilons à nouveau! Et encore!
Ci-dessus j'ai parlé de "multiniveau", parlons-en. L'idée est simple: si nous ne sommes pas encore prêts à créer du code entièrement optimisé, mais que l'interprétation coûte toujours cher, nous pouvons précompiler puis compiler final lorsque nous sommes prêts à générer du code plus optimisé.
Hotspot est un JIT en couches avec deux compilateurs, C1 et C2. C1 effectue une compilation rapide et exécute le code, puis effectue un profilage complet pour obtenir le code compilé avec C2. Cela peut aider à résoudre de nombreux problèmes d'échauffement. Le code compilé non optimisé est de toute façon plus rapide que l'interprétation. De plus, C1 et C2 ne compilent pas tout le code. Si la fonction semble assez simple, avec une forte probabilité, C2 ne nous aidera pas et ne fonctionnera même pas (nous gagnerons également du temps sur le profilage!). Si C1 est occupé à compiler, le profilage peut continuer, le travail de C1 sera interrompu et la compilation avec C2 démarre.
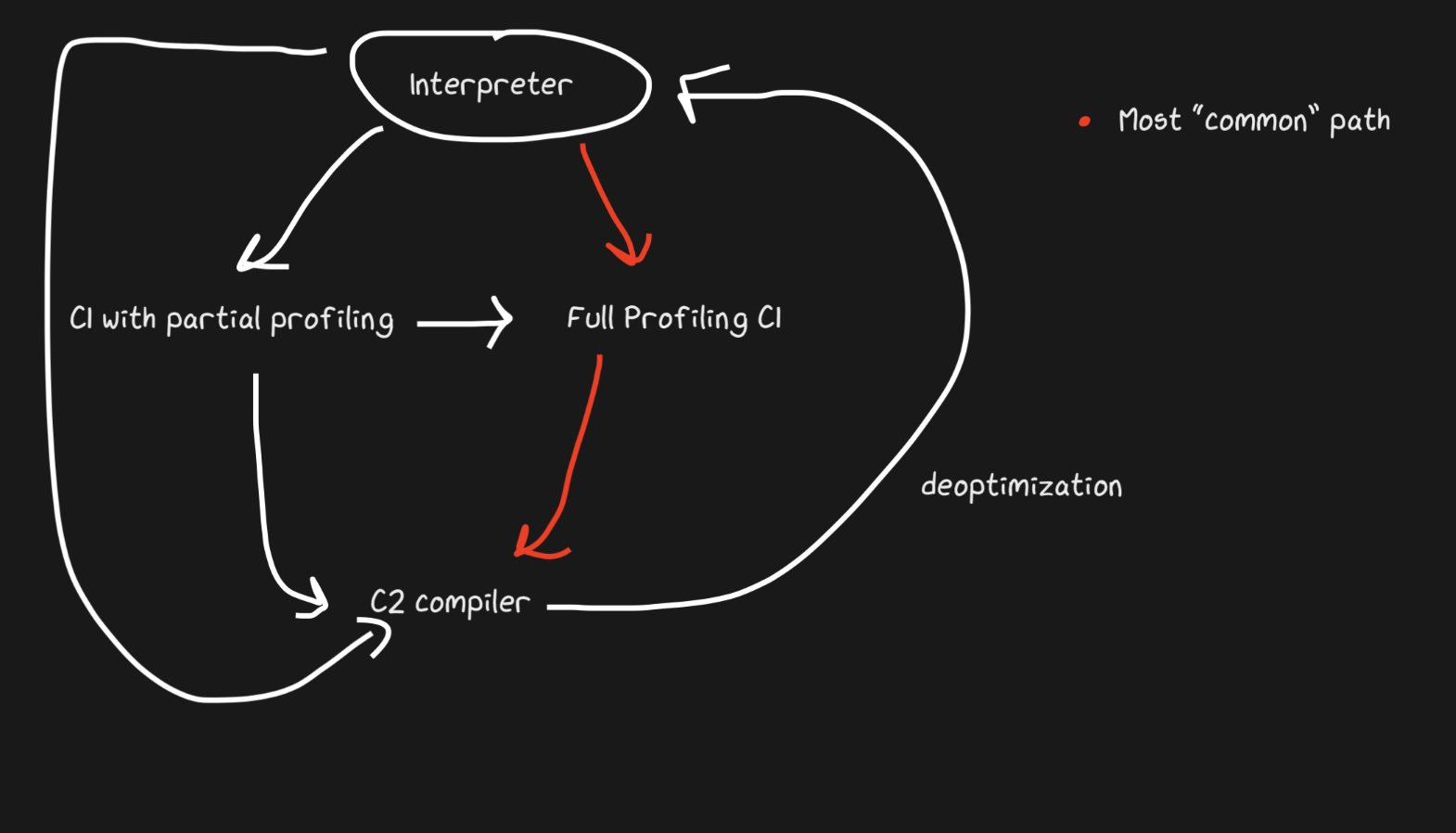
JavaScript Core a encore plus de niveaux! En fait, il existe trois JIT . L'interpréteur JSC effectue un profilage de la lumière, puis passe à Baseline JIT, puis DFG (Data Flow Graph) JIT et enfin FTL (Faster than Light) JIT. Avec autant de niveaux, la signification de la désoptimisation n'est plus limitée à la transition du compilateur à l'interpréteur, la désoptimisation peut être effectuée en commençant par DFG et en terminant par Baseline JIT (ce n'est pas le cas dans le cas de Hotspot C2-> C1). Toutes les désoptimisations et transitions vers le niveau suivant sont effectuées en utilisant OSR (Stack Override).
Baseline JIT se connecte après environ 100 exécutions et DFG JIT après environ 1000 (à quelques exceptions près). Cela signifie que le JIT obtient le code compilé beaucoup plus rapidement que le même Pypy (qui prend environ 3000 exécutions). La superposition permet au JIT d'essayer de corréler la durée d'exécution du code avec la durée de son optimisation. Il y a beaucoup d'astuces, quel type d'optimisation (inlining, casting, etc.) à effectuer à chacun des niveaux, et donc cette stratégie est optimale.
Sources utiles
- Comment fonctionne le compilateur de traces de LuaJIT de Mike Pall
- Impact du méta-traçage sur les machines virtuelles par Laurie Tratt
- Analyse de Pypy Escape
- Pourquoi les utilisateurs ne sont pas plus satisfaits des machines virtuelles par Laurie Tratt
- À propos des moteurs JS:
- À propos de la désoptimisation:
- Graal:
- :
- :