Répétez, mais à chaque fois d'une nouvelle manière - n'est-ce pas cet art?
Stanislav Jerzy Lec, du livre "Uncombed Thoughts"
Le dictionnaire définit la réplication comme le processus de maintien de deux (ou plus) ensembles de données dans un état cohérent. Qu'est-ce que «l'état cohérent des ensembles de données» est une grande question distincte, reformulons donc la définition de manière plus simple: le processus de modification d'un ensemble de données, appelé réplica, en réponse aux modifications d'un autre ensemble de données, appelé le maître. Les décors ne sont pas forcément les mêmes.

La prise en charge de la réplication de bases de données est l'une des tâches les plus importantes d'un administrateur: presque toutes les bases de données, quelle que soit leur importance, ont une réplique, voire plusieurs.
Les tâches de réplication incluent au moins
- prise en charge de la base de données de sauvegarde en cas de perte de la principale;
- réduire la charge sur la base due au transfert d'une partie des requêtes vers les répliques;
- transfert de données vers des systèmes d'archivage ou d'analyse.
Dans cet article, je parlerai des types de réplication et des tâches que chaque type de réplication résout.
Il existe trois approches de réplication:
- Bloquer la réplication au niveau du système de stockage;
- Réplication physique au niveau du SGBD;
- Réplication logique au niveau du SGBD.
Bloquer la réplication
Avec la réplication par blocs, chaque opération d'écriture est effectuée non seulement sur le disque principal, mais également sur la sauvegarde. Ainsi, un volume sur une baie correspond à un volume en miroir sur une autre baie, répétant le volume principal avec une précision d'octet:
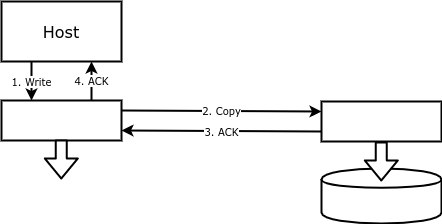
les avantages d'une telle réplication comprennent la facilité de configuration et la fiabilité. Une matrice de disques ou quelque chose (un périphérique ou un logiciel) entre l'hôte et le disque peut écrire des données sur un disque distant.
Les baies de disques peuvent être complétées par des options permettant d'activer la réplication. Le nom de l'option dépend du fabricant de la baie:
| Fabricant | Marque déposée
|
|---|---|
| CEM | SRDF (Symmetrix Remote Data Facility) |
| IBM | Metro Mirror - réplication synchrone
Global Mirror - réplication asynchrone |
| Hitachi | Vraie copie |
| Hewlett-Packard | Accès continu |
| Huawei | HyperRéplication |
Si la matrice de disques n'est pas capable de répliquer les données, un agent peut être installé entre l'hôte et la matrice, qui écrit sur deux baies à la fois. Un agent peut être un périphérique autonome (EMC VPLEX) ou un composant logiciel (HPE PeerPersistence, Windows Server Storage Replica, DRBD). Contrairement à une matrice de disques, qui ne peut fonctionner qu'avec la même matrice, ou au moins avec une matrice du même fabricant, un agent peut travailler avec des périphériques de disque complètement différents.
L'objectif principal de la réplication de bloc est de fournir une tolérance aux pannes. Si la base de données est perdue, vous pouvez la redémarrer à l'aide du volume en miroir.
La réplication en bloc est excellente pour sa polyvalence, mais la polyvalence a un prix.
Premièrement, aucun serveur ne peut gérer un volume en miroir, car son système d'exploitation ne peut pas contrôler les écritures sur celui-ci; du point de vue de l'observateur, les données sur le volume en miroir apparaissent spontanément. En cas de sinistre (panne du serveur principal ou de l'ensemble du centre de données où se trouve le serveur principal), vous devez arrêter la réplication, démonter le volume principal et monter le volume en miroir. Dès que possible, vous devez redémarrer la réplication dans la direction opposée.
Dans le cas de l'utilisation d'un agent, toutes ces actions seront effectuées par l'agent, ce qui simplifie la configuration, mais ne réduit pas le temps de commutation.
Deuxièmement, le SGBD lui-même sur le serveur de secours ne peut être démarré qu'après le montage du disque. Dans certains systèmes d'exploitation, par exemple sous Solaris, la mémoire du cache est balisée lors de l'allocation et le temps de marquage est proportionnel à la quantité de mémoire allouée, c'est-à-dire que le démarrage de l'instance ne sera pas instantané. De plus, le cache sera vide après le redémarrage.
Troisièmement, après avoir démarré sur le serveur de sauvegarde, le SGBD découvrira que les données sur le disque sont incohérentes et que vous devez passer beaucoup de temps à récupérer à l'aide des fichiers de journalisation: tout d'abord, répétez ces transactions, dont les résultats ont été enregistrés dans le journal, mais n'ont pas eu le temps d'être enregistrés dans les fichiers de données, puis annulez les transactions qui n'avaient pas eu le temps de se terminer au moment de l'échec.
La réplication de bloc ne peut pas être utilisée pour l'équilibrage de charge et un schéma similaire est utilisé pour mettre à niveau la banque de données avec le volume en miroir sur la même baie que la principale. EMC et HP appellent ce schéma BCV, seul EMC signifie Business Continuance Volume, et HP Business Copy Volume. IBM n'a pas de marque spéciale pour ce cas, ce schéma est appelé "volume en miroir".

Deux volumes sont créés dans la baie et les opérations d'écriture sont effectuées de manière synchrone sur les deux (A). A un certain moment, le miroir se brise (B), c'est-à-dire que les volumes deviennent indépendants. Le volume en miroir est monté sur un serveur dédié aux mises à niveau de stockage et une instance de base de données est générée sur ce serveur. L'instance prendra autant de temps que pour une restauration de réplication par bloc, mais ce temps peut être considérablement réduit en cassant le miroir pendant les périodes creuses. Le fait est que briser le miroir dans ses conséquences équivaut à une terminaison anormale du SGBD, et le temps de récupération en cas de terminaison anormale dépend significativement du nombre de transactions actives au moment du crash. La base de données destinée au déchargement est disponible à la fois en lecture et en écriture. Tous les identifiants de bloc,les miroirs modifiés après la pause, à la fois sur le volume principal et sur le volume en miroir, sont enregistrés dans une zone spéciale de Block Change Tracking - BCT.
Après la fin du téléchargement, le volume en miroir est démonté (C), le miroir est restauré et après un certain temps, le volume en miroir rattrape à nouveau le volume principal et devient sa copie.
Réplication physique
Les journaux (journal de rétablissement ou journal à écriture anticipée) contiennent toutes les modifications apportées aux fichiers de base de données. L'idée derrière la réplication physique est que les modifications des journaux sont ré-validées dans une autre base de données (réplique), et donc les données dans la réplique répliquent les données dans l'octet par octet maître.
La possibilité d'utiliser les journaux de base de données pour mettre à jour une réplique est apparue dans la version d'Oracle 7.3, qui a été publiée en 1996, et déjà dans la version d'Oracle 8i, la livraison des journaux de la base de données principale à la réplique était automatisée et s'appelait DataGuard. La technologie s'est avérée si demandée qu'aujourd'hui le mécanisme de réplication physique est présent dans presque tous les SGBD modernes.
| SGBD | Option de réplication
|
|---|---|
| Oracle | DataGuard actif |
| IBM DB2 | HADR |
| Microsoft SQL Server | Expédition de journaux / Toujours activé |
| PostgreSQL | Envoi de journaux / réplication en streaming |
| MySQL | Réplication InnoDB physique d'Alibaba |
L'expérience montre que si le serveur est utilisé uniquement pour maintenir la réplique à jour, environ 10% de la puissance de traitement du serveur sur lequel s'exécute la base principale est suffisante pour cela.
Les journaux de SGBD ne sont pas destinés à être utilisés en dehors de cette plate-forme, leur format n'est pas documenté et peut changer sans préavis. D'où l'exigence tout à fait naturelle que la réplication physique ne soit possible qu'entre instances de la même version du même SGBD. Par conséquent, il existe des limitations possibles sur le système d'exploitation et l'architecture du processeur, qui peuvent également affecter le format du journal.
Naturellement, la réplication physique n'impose aucune restriction sur les modèles de stockage. De plus, les fichiers de la base de données réplique peuvent être localisés d'une manière complètement différente de celle de la base de données source - il vous suffit de décrire la correspondance entre les volumes sur lesquels ces fichiers se trouvent.
Oracle DataGuard vous permet de supprimer certains des fichiers de la base de données de répliques - dans ce cas, les modifications des journaux liés à ces fichiers seront ignorées.
La réplication de base de données physique présente de nombreux avantages par rapport à la réplication de stockage:
- la quantité de données transférées est moindre en raison du fait que seuls les journaux sont transférés, mais pas les fichiers de données; les expériences montrent une diminution de 5 à 7 fois du trafic;
- : - , ; , ;
- , . , .
La capacité de lire des données à partir d'une réplique a été introduite en 2007 avec la sortie d'Oracle 11g, comme indiqué par l'épithète «active» ajoutée au nom de la technologie DataGuard. D'autres SGBD ont également la possibilité de lire à partir d'un réplica, mais cela n'est pas reflété dans le nom.
L'écriture de données sur une réplique est impossible, car les modifications lui sont apportées octet par octet et la réplique ne peut pas fournir une exécution compétitive de ses demandes. Oracle Active DataGuard dans les versions récentes permet d'écrire sur la réplique, mais ce n'est rien de plus que du «sucre»: en fait, les modifications sont effectuées sur la base principale et le client attend qu'elles soient transférées vers la réplique.
Si un fichier de la base de données principale est endommagé, vous pouvez simplement copier le fichier correspondant de la réplique (lisez attentivement le manuel de l'administrateur avant de le faire avec votre base de données!). Le fichier sur la réplique peut ne pas être identique au fichier de la base de données principale: le fait est que lorsque le fichier est développé, les nouveaux blocs ne sont pas remplis de quoi que ce soit pour accélérer, et leur contenu est accidentel. La base peut ne pas utiliser tout l'espace du bloc (par exemple, il peut y avoir de l'espace libre dans le bloc), mais le contenu de l'espace utilisé correspond à l'octet.
La réplication physique peut être synchrone ou asynchrone. Avec la réplication asynchrone, il existe toujours un certain ensemble de transactions qui se sont terminées sur la base principale, mais qui n'ont pas encore atteint la base de secours, et en cas de transition vers la base de secours si la base principale échoue, ces transactions seront perdues. Dans la réplication synchrone, l'achèvement de l'opération de validation signifie que tous les enregistrements de journal liés à cette transaction ont été validés dans le réplica. Il est important de comprendre que l'obtention d'un réplica de journal ne signifie pas que les modifications sont appliquées aux données. Si la base de données principale est perdue, les transactions ne seront pas perdues, mais si l'application écrit des données dans la base de données principale et les lit à partir de la réplique, elle a alors une chance d'obtenir l'ancienne version de ces données.
Dans PostgreSQL, il est possible de configurer la réplication de sorte que la validation ne se termine qu'après l'application des modifications aux données de réplique (option
synchronous_commit = remote_apply), tandis que dans Oracle, vous pouvez configurer la réplique entière ou des sessions individuelles afin que les requêtes ne soient exécutées que si la réplique n'est pas en retard par rapport à la base de données principale ( STANDBY_MAX_DATA_DELAY=0). Cependant, il est toujours préférable de concevoir l'application de manière à ce que l'écriture dans la base de données principale et la lecture à partir des répliques soient effectuées dans différents modules.
Lorsqu'ils cherchent une réponse à la question de savoir quel mode choisir, synchrone ou asynchrone, les spécialistes du marketing Oracle viennent à notre aide. DataGuard propose trois modes, chacun maximisant l'un des paramètres - sécurité des données, performances, disponibilité - au détriment des autres:
- Performances maximales: la réplication est toujours asynchrone;
- Maximum protection: ; , commit ;
- Maximum availability: ; , , , .
Malgré les avantages indéniables de la réplication de base de données par rapport à la réplication par blocs, les administrateurs de nombreuses entreprises, en particulier celles qui ont de vieilles traditions de fiabilité, sont toujours très réticents à abandonner la réplication par blocs. Il y a deux raisons à cela.
Premièrement, dans le cas d'une réplication à l'aide d'une matrice de disques, le trafic ne passe pas par le réseau de transmission de données (LAN), mais par le réseau de stockage. Souvent, dans les infrastructures construites il y a longtemps, les SAN sont beaucoup plus fiables et performants que les réseaux de données.
Deuxièmement, la réplication synchrone au moyen d'un SGBD est devenue fiable relativement récemment. Dans Oracle, la percée s'est produite dans la version 11g, sortie en 2007, et dans d'autres SGBD, la réplication synchrone est apparue encore plus tard. Bien sûr, 10 ans selon les standards de la sphère informatique, ce n'est pas si court, mais en matière de sécurité des données, certains administrateurs sont toujours guidés par le principe du «quoi qu'il arrive» ...
Réplication logique
Toutes les modifications apportées à la base de données se produisent à la suite d'appels à son API, par exemple à la suite de l'exécution de requêtes SQL. L'idée d'exécuter la même séquence de requêtes sur deux bases différentes semble très tentante. Pour la réplication, vous devez respecter deux règles:
- , , . D, A B.
- , , . B , , C.
La réplication des commandes (réplication basée sur des instructions) est implémentée, par exemple, dans MySQL. Malheureusement, ce schéma simple n'aboutit pas à des ensembles de données identiques pour deux raisons.
Premièrement, toutes les API ne sont pas déterministes. Par exemple, si une requête SQL contient la fonction now () ou sysdate () qui renvoie l'heure actuelle, elle renverra des résultats différents sur différents serveurs car les requêtes ne sont pas exécutées simultanément. En outre, différents états des déclencheurs et des fonctions stockées, différents paramètres régionaux affectant l'ordre de tri, et bien plus encore, peuvent entraîner des différences.
Deuxièmement, la réplication basée sur des commandes parallèles ne peut pas être interrompue et redémarrée normalement.
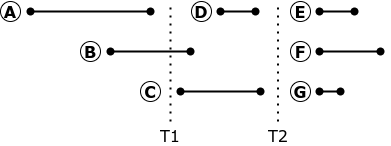
Si la réplication est arrêtée au moment T1, la transaction B doit être abandonnée et annulée. Lorsque vous redémarrez la réplication, l'exécution de la transaction B peut amener la réplique à un état différent de l'état de la base de données source: à la source, la transaction B a commencé avant la fin de la transaction A, ce qui signifie qu'elle n'a pas vu les modifications apportées par la transaction A.
La réplication des demandes peut être arrêtée et redémarré uniquement au moment T2, lorsqu'il n'y a pas de transactions actives dans la base de données. Bien sûr, il n'y a pas de tels moments sur une base industrielle très chargée.
En règle générale, la réplication logique utilise des requêtes déterministes. Le déterminisme de la requête est assuré par deux propriétés:
- la requête met à jour (ou insère, ou supprime) un seul enregistrement, l'identifiant par sa clé primaire (ou unique);
- tous les paramètres de demande sont explicitement définis dans la demande elle-même.
Contrairement à la réplication basée sur des instructions, cette approche est appelée réplication basée sur les lignes.
Supposons que nous ayons une table d'employés avec les données suivantes:
| ID | Nom | Département | Un salaire
|
|---|---|---|---|
| 3817 | Ivanov Ivan Ivanovitch | 36 | 1800 |
| 2274 | Petrov Petr Petrovich | 36 | 1600 |
| 4415 | Kuznetsov Semyon Andreevich | 41 | 2100 |
L'opération suivante a été effectuée sur cette table:
update employee set salary = salary*1.2 where dept=36;Afin de répliquer correctement les données, les requêtes suivantes seront exécutées dans le réplica:
update employee set salary = 2160 where id=3817;
update employee set salary = 1920 where id=2274;Les requêtes produisent le même résultat que sur la base d'origine, mais elles ne sont pas équivalentes aux requêtes exécutées.
La base de répliques est ouverte et disponible non seulement pour la lecture, mais aussi pour l'écriture. Cela permet au réplica d'être utilisé pour exécuter une partie des requêtes, y compris pour créer des rapports nécessitant la création de tables ou d'index supplémentaires.
Il est important de comprendre qu'une réplique logique sera équivalente à la base d'origine uniquement si aucune modification supplémentaire n'y est apportée. Par exemple, si dans l'exemple ci-dessus, dans la réplique, le département de Sidorov est ajouté à 36, il ne recevra pas de promotion, et si Ivanov est transféré du département 36, il recevra une promotion, quoi qu'il arrive.
La réplication logique fournit un certain nombre de fonctionnalités introuvables dans d'autres types de réplication:
- mise en place d'un ensemble de données répliquées au niveau de la table (pour la réplication physique - au niveau du fichier et de l'espace table, pour la réplication de bloc - au niveau du volume);
- création de topologies de réplication complexes - par exemple, consolidation de plusieurs bases de données en une réplication unique ou bidirectionnelle;
- diminution de la quantité de données transmises;
- réplication entre différentes versions d'un SGBD ou même entre des SGBD de différents fabricants;
- traitement des données pendant la réplication, y compris la restructuration, l'enrichissement, la préservation de l'histoire.
Il existe également des inconvénients qui empêchent la réplication logique de remplacer la réplication physique:
- toutes les données répliquées doivent avoir des clés primaires;
- la réplication logique ne prend pas en charge tous les types de données - par exemple, il peut y avoir des problèmes avec les BLOB.
- : , ;
- ;
- , , – , .
Les deux derniers inconvénients limitent considérablement l'utilisation d'une réplique logique comme outil de tolérance aux pannes. Si une requête dans la base de données principale modifie plusieurs lignes à la fois, le réplica peut être considérablement retardé. Et la possibilité de changer de rôle nécessite des efforts remarquables de la part des développeurs et des administrateurs.
Il existe plusieurs façons d'implémenter la réplication logique, et chacune de ces méthodes implémente une partie des capacités et n'implémente pas l'autre:
- réplication par déclencheurs;
- en utilisant les journaux de SGBD;
- utilisation du logiciel CDC (Change Data Capture);
- réplication appliquée.
Réplication de déclenchement
Le déclencheur est une procédure stockée qui est automatiquement exécutée lors de toute action de modification des données. Le déclencheur, qui est appelé lorsque chaque enregistrement change, a accès à la clé de cet enregistrement, ainsi qu'aux anciennes et nouvelles valeurs de champ. Si nécessaire, le déclencheur peut enregistrer les nouvelles valeurs de ligne dans une table spéciale, à partir de laquelle un processus spécial côté réplique les lira. La quantité de code dans les déclencheurs est importante, il existe donc un logiciel spécial qui génère de tels déclencheurs, par exemple, «réplication de fusion» - un composant de Microsoft SQL Server ou Slony-I - un produit distinct pour la réplication PostgreSQL.
Points forts de la réplication des déclencheurs:
- indépendance des versions de la base principale et de la réplique;
- capacités étendues de conversion de données.
Désavantages:
- charge sur la base principale;
- latence de réplication élevée.
Utilisation des journaux du SGBD
Le SGBD lui-même peut également fournir des capacités de réplication logique. Les journaux sont la source des données, tout comme pour la réplication physique. Les informations sur le changement d'octet sont également ajoutées aux informations sur les champs modifiés (journalisation supplémentaire dans Oracle,
wal_level = logicaldans PostgreSQL), ainsi que sur la valeur de la clé unique, même si elle ne change pas. En conséquence, le volume de journaux de base de données augmente - selon diverses estimations, de 10 à 15%.
Les capacités de réplication dépendent de l'implémentation dans un SGBD particulier - si vous pouvez créer une veille logique dans Oracle, dans PostgreSQL ou Microsoft SQL Server, vous pouvez déployer un système complexe d'abonnements mutuels et de publications à l'aide des outils de plateforme intégrés. De plus, le SGBD fournit une surveillance et un contrôle intégrés de la réplication.
Les inconvénients de cette approche incluent une augmentation du volume de journaux et une augmentation possible du trafic entre les nœuds.
Utilisation du CDC
Il existe toute une classe de logiciels conçus pour organiser la réplication logique. Ce logiciel s'appelle CDC, modifier la capture de données. Voici une liste des plateformes les plus connues de cette classe:
- Oracle GoldenGate (acquis par GoldenGate en 2009);
- IBM InfoSphere Data Replication (anciennement InfoSphere CDC; encore plus tôt, DataMirror Transformation Server, acquis par DataMirror en 2007);
- VisionSolutions DoubleTake / MIMIX (anciennement Vision Replicate1);
- Plateforme d'intégration de données Qlik (anciennement Attunity);
- CDC Informatica PowerExchange;
- Debezium;
- Collecteur de données StreamSets ...
La tâche de la plate-forme est de lire les journaux de la base de données, de transformer les informations, de transférer les informations vers une réplique et de postuler. Comme dans le cas de la réplication au moyen du SGBD lui-même, le journal doit contenir des informations sur les champs modifiés. L'utilisation d'une application supplémentaire vous permet d'effectuer des transformations complexes des données répliquées à la volée et de créer des topologies de réplication assez complexes.
Forces:
- la capacité de répliquer entre différents SGBD, y compris le chargement des données dans les systèmes de reporting;
- les plus larges possibilités de traitement et de transformation des données;
- trafic minimal entre les nœuds - la plate-forme coupe les données inutiles et peut compresser le trafic;
- capacités intégrées pour surveiller l'état de la réplication.
Il n'y a pas beaucoup d'inconvénients:
- augmentation du volume de logs, comme pour la réplication logique au moyen d'un SGBD;
- les nouveaux logiciels sont difficiles à configurer et / ou avec des licences coûteuses.
Ce sont les plates-formes CDC qui sont traditionnellement utilisées pour mettre à jour les entrepôts de données d'entreprise en temps quasi réel.
Réplication appliquée
Enfin, un autre moyen de réplication est la formation de vecteurs de changement directement côté client. Le client doit émettre des requêtes déterministes qui affectent un seul enregistrement. Ceci peut être réalisé en utilisant une bibliothèque de base de données spéciale telle que le moteur de base de données Borland (BDE) ou l'ORM Hibernate.
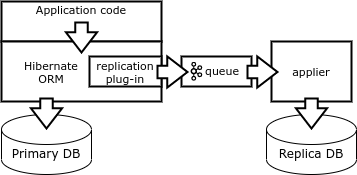
Lorsque l'application termine la transaction, le plugin Hibernate ORM écrit le vecteur de modification dans la file d'attente et exécute la transaction sur la base de données. Un processus de réplication spécial soustrait les vecteurs de la file d'attente et effectue des transactions dans la base de répliques.
Ce mécanisme est utile pour mettre à jour les systèmes de rapports. Il peut également être utilisé pour fournir une tolérance aux pannes, mais dans ce cas, l'état de réplication doit être surveillé dans l'application.
Traditionnellement - forces et faiblesses de cette approche:
- la capacité de répliquer entre différents SGBD, y compris le chargement des données dans les systèmes de reporting;
- la capacité de traiter et de transformer les données, la surveillance de l'état, etc.
- trafic minimal entre les nœuds - la plate-forme coupe les données inutiles et peut compresser le trafic;
- indépendance totale par rapport à la base de données - à la fois du format et des mécanismes internes.
Les avantages de cette méthode sont indéniables, mais il y a deux inconvénients très sérieux:
- restrictions sur l'architecture des applications;
- une énorme quantité de code de réplication natif.
Alors, quel est le meilleur?
Il n'y a pas de réponse sans équivoque à cette question, ainsi qu'à bien d'autres. Mais j'espère que le tableau ci-dessous vous aidera à faire le bon choix pour chaque tâche spécifique:
| Réplication de bloc de stockage | Bloquer la réplication par agent | Réplication physique | Réplication de SGBD logique | CDC |
|
||
|---|---|---|---|---|---|---|---|
| X | X | X/7..X/5 | X/7..X/5 | ≤X/10 | ≤X/10 | ≤X/10 | |
| 5 … | 5 … | 1..10 | 1..10 | 1..2 | 1..2 | 1..2 | |
| + | + | +++ | + | ∅ | ∅ | ∅ | |
| ∅ | ∅ | RO | R/W | R/W | R/W | R/W | |
| - | -
broadcast |
-
broadcast |
-
broadcast * p2p* |
-
broadcast * p2p* |
-
broadcast * p2p* |
-
broadcast * p2p* |
|
| ∅ | ∅ | – | – – | – – – | – – | ∅ | |
| + + + | + + | + + | + + | – | + | – – – | |
| – – | – – | – | – | ∅ | – – – | ∅ | |
| ∅ | + | + + | + + | + + | + + + | + + + |
- , ; .
- , .
- , .
- .
- , , .
- CDC , / .
- .